从0到1实战微服务架构(第2版)
地址汇总
第2版前言
自从本书发布了后,技术圈发生了许多变化:
- Spring Boot 2.X 稳定版发布
- Kubernetes下的包管理项目“Helm”,正式加入CNCF基金会
- 阿里巴巴开源了Nacos服务发现项目
- ......
3年后的2021年,我正式开启了本书2.0版的写作计划。
由于技术更新迭代频繁,这是一次完全的重写,不是修订。
由于gitbook项目已不再维护,我改用mdBook做为渲染工具,MarkText做为写作工具。
写作水平有限,还请各位多提宝贵意见。
第1版前言
微服务是继SOA后,最流行的服务架构风格之一。
按照微服务对系统进行拆分后,每个服务的业务逻辑都更加简单、清晰。服务之间是松耦合的,模块之间的边界也更加清晰。
微服务有效降低了软件项目的业务复杂程度,为小团队独立开发、持续交付和部署打下了良好的基础。
遗憾的是,微服务并不是银弹。与传统的单一架构相比,微服务架构对团队的组织架构、技术水平、运维能力等方面,都提出了更高的要求。如果没有掌握得当的方法而生搬硬套,微服务架构只会会适得其反--降低项目的开发效率,这是本书的创作初衷之一。
在国内外的技术社区中,比较推崇现有开源方案,如"Spring Cloud全家桶"或者阿里开源的"Dubbo"。
上述框架通常已经实现了服务发现、配置、负载均衡、限流熔断,等微服务架构所必须的的核心功能。
使用开源框架省却了造轮子的过程,但也降低了我们学习、思考的动力。
为什么需要服务发现,又如何实现它呢?配置中心呢....思考和设计的过程充满了挑战,也是提升自身架构能力的一种手段。这是本书的创作初衷之二。
已有的微服务资料过于重视微服务的开发,忽略了微服务赖以生存的生态系统:工具链、自动化运维。可以说,离开了这两点的支持,微服务架构将难以落地。完善这两方面的思考和实战,是本书的创作初衷之三。
为此,我撰写了这本《从0到1实战微服务架构》。让我们"暂时忘掉"已有的、成熟的开源解决方案。尝试亲自动手,实现微服务架构的各个模块。
我们会从微服务开发、工具链、运维这三个角度,阐述微服务架构的实战方案。
如果本书帮助了你,欢迎在在github加Star,但严禁用于商业用途!(参见本页底部版权声明)
由于能力水平所限,本书难免存在各种错误,恳请各位进行指正(Issue or PR),谢谢!
读者基础
由于篇幅、精力所限,本书无法写成一本”零起点”教程。我假设读者具有至少2年的服务端工作经验,并且了解以下技术或原理:
- Git
- Maven & Gradle
- Docker & Kubernetes
- Java
- Spring / Spring Boot
- 数据库: 如MySQL
- 消息队列: 如RabbitMQ
- 缓存系统: 如Memcached
- 内存数据库: 如Redis
本书可以供架构师、项目经理、高级服务端程序员参考、学习。
动手实战是本书的核心内容,因此本书所涉及的全部代码,都托管到了我的Github上(以lmsia-开头的项目)。
这些代码以研讨为主要目的,也可以直接应用于生产,但本人不对其稳定性负责。
版权
本书虽然在github上公开写作,但版权归本人Coder4所有。
依照 署名-非商业性使用-相同方式共享 ,任何人可以在保留署名的情况下转载。但严禁用于商业用途。
This is a book powered by mdBook.
微服务概述
什么是“微”服务?
如果你仔细观察,会发现我在上一行的标题中,将“微”打了个引号。
如果我们暂时去掉这个''微"字理解,微服务就是我们熟知的“服务端” 或者 “后端”。
现在让我们把微字加回来:-)
"微服务"(Microservices)由马丁·福勒(Martin Fowler)提出的一种架构理念,原文发表于2014年。
微服务是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。
我们抓三个关键点来理解:
-
单一应用划分为一组更小的服务:将一个较大的、复杂的应用,拆分为多个小的服务。你可能会问:“这样不会增加复杂度么”?是的,会增加。但这种拆分也会带来明显的优点,我们后面会提到。
-
独立的进程:每个微服务独立运行在自己的进程中,互不干扰。虽然这里并没有限制进程的部署方式,但可以想见,经过"划分"后的微服务,势必会产生众多进程。微服务是拆分而来的,他们之间势必存在逻辑的耦合。由此,会产生新的问题"微服务间的通信"。
-
相互协调、配合:微服务的进程间需要通信、交互。从理论而言,所有IPC(Inter-Process Communacation,进程间通信)的方式都可以完成这个过程。但微服务的进程众多,很难完整地部署在同一台机器上,这势必产生跨主机的网络通信。所以,在微服务中,多采用RPC(Reomote Procedure Call,远程过程调用)的方式来完成通信。
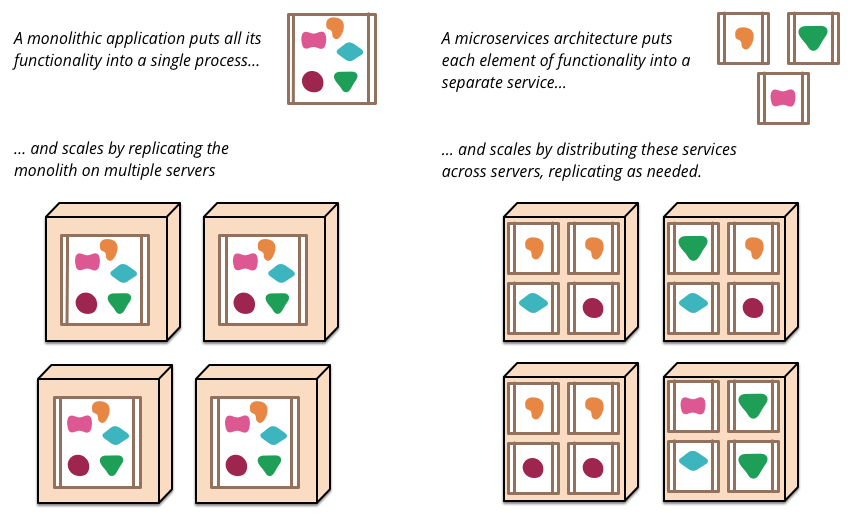
上图展示了单体服务 和 微服务的区别。
为什么需要微服务?
在前文中,我们挖了一个坑:'微服务的划分会导致复杂度上升',为什么还要使用一项有缺陷的技术呢?
我们先讲第一个故事。
小张入职了一家互联网创业公司,一开始只有3个后端程序员,每天的工作是:和产品经理讨(si)论(bi)需求、写代(b)码(ug),改Bug,工作紧张但规律。服务端的上线窗口是周五下午:合并分支、代码Review、推送线上,一气呵成,不仅能准点下班,还能去吃个火锅。
过了两个月,行业赶上了风口,公司的业务快速发展,后端团队也快速膨胀到20人。然而,麻烦也接踵而至:大家修改的是同一个仓库下的服务端代码,"解冲突"成为了家常便饭,还发生了几次"一个小修改,破坏了其他业务主流程“的严重线上事故。
为了改善这种情况,老板招聘了2位QA(质量保证,测试)人员,由他们负责测试工作。然而,一个很小的改动都需要对整个后端服务的case进行全量回归测试。一个功能的开发需要1天,测试却耗费1周,迫于老板的压力,研发同学只能安慰自己:XX功能简单,不需要测试了,直接上线。
最终,周五成为了"噩梦日":周四晚上要提前开一个Excel表、统计好第二天要上线的需求,并按优先级排定顺序。周五全员提前1小时来公司,开始逐个逐个需求的"合并代码"”、"解冲突",“上线”、"观察" 、“回滚”、“修改代码”......
上线结束的收工时间从6点变成了9点,又逐渐拖到了11点,最后索性全员加班、通宵上线。技术团队的每一位同学,都感到身心俱疲。
听完这个故事,你是否有"似曾相识"的感觉?
科普一下,上述故事中的服务一般称作“单体服务” 或者 “巨石服务”(Monoliths)。
接下来,是第二个故事。
由于工作强度大、线上故障频发、团队士气低落,老板请来了老刘担任技术经理。
第一周:老刘带领团队将复杂、臃肿的"巨型服务"拆分成了“用户”、“订单”、“服务”三个微服务。
第二周:老刘将团队进行了上述类似的拆分,也分成了三个小组。
第三周:事情有了微妙的变化。分组后,合并代码引发的冲突减少了。开发业务时,多数的改动都封闭在单独的微服务内,改动造成的影响范围减少了,测试周期缩短了。
......
三个月后的一个周五的下午,(得益于提高的交付质量,以及微服务的独立并行上线),团队提前2小时完成了上线,距离上一次故障通报已经过去了两个月。
研发讨论群里,小张发了一条消息:“今天居然可以正点下班了,老刘真厉害!”
老刘回复:这是大家的努力的结果,真正“厉害”的应该是“微服务”。
听完这两个故事,我们来总结下微服务架构的两个优点:)
-
逻辑清晰:一个微服务只负责一项(或少数几项)很明确的业务,逻辑更加简介清晰,易于理解。
-
独立自治:每个微服务由一个小组负责。减少了跨团队的代码冲突,同时降低了改动的影响范围,提高了研发效率。
在故事之外,微服务架构还具有以下的优点:
-
伸缩性强:相对于庞大的巨石服务,微服务更加独立,可以针对不同的性能需求,有选择的对不同微服务进行伸缩。举个栗子:明天有大促,产品预测:注册功能提升10倍,其他功能无波动。针对巨石服务,我们只能整体扩容10倍;微服务架构下,我们只需要10倍扩容用户微服务。
-
技术异构性:每个微服务内可以使用不同的技术栈,甚至不同的开发语言。只要微服务之间使用统一的通信方式即可。
微服务架构有很多优势,那团队抓紧上马微服务吧?
微服务是“银弹”么?
直接泼一盆冷水:
There is no Silver Bullet. -- 《人月神话》
微服务不是“银弹”,它存在以下缺点:
-
复杂度升高:在巨石服务中,所有修改都集中在同一个项目内;在微服务架构下,复杂功能的开发,需要同步修改多个微服务,复杂度骤然升高。
-
性能损耗:原本在巨石服务中的方法调用,演变为微服务之间的跨进程、网络通信。性能会受到较大影响。
-
可靠性陷阱:假设每个服务的可靠性都是99%,一个巨石服务,可靠性是99%、三个微服务的可靠性会下降到99% x 99% x 99% = 97%。
-
运维难度加大:巨石服务被拆分成N个微服务,部署的数量翻倍的增长。此外,多组微服务的运行,也会增大运维、监控的难度。
有意思的是:"拆分"带来了优点,也引入了缺点。
夫尺有所短,寸有所长,物有所不足,智有所不明。 -- 《楚辞.屈原.卜居》
微服务架构也是如此,它的优缺点并存。
微服务适用什么场景?
什么场景适用微服务,什么场景不适用呢?
这篇文章[《When to use and not use microservices》](Best of 2020: When To Use - and Not To Use - Microservices - Container Journal)给出了一些建议:
适用微服务架构的场景:
-
希望巨石服务能适应“可扩展性”、“敏捷性”、“可管理性”,提升交付速度时
-
需要为(使用陈旧技术开发的)的老系统,迭代新功能时
-
有一些相对独立的模块可以跨业务复用时:如登录、检索、身份验证等。
-
构建需要快速交付、创新度高、敏捷的应用 / 服务
不适用微服务架构的场景:
-
业务简单,无需处理复杂问题
-
团队规模太小,尚无法负担微服务拆分带来的复杂度提升
-
为了微服务而微服务
最后,引用马丁·福勒(Martin Fowler)论文的结尾做结束本节的讨论。
我们怀着谨慎、乐观的态度写了这篇文章。到目前为止,我们已经看到:微服务风格是一条非常值得探索的路。我们不能肯定地说,我们将在哪里结束,但软件开发的挑战之一是,你只能基于目前能拿到手的、不完善的信息作出决定。
微服务研发工具链
子曰:“工欲善其事,必先利其器。居是邦也,事其大夫之贤者,友其士之仁者。”
-- 《论语》
普通话版:工匠想要做好工作,先要把工具打磨锋利。
程序员版:软件工程师要想写好代码,需要一把机械键盘,并定期清洗轴以维持最佳手感。
对于程序员而言,除了键盘等硬件,还有一系列软件。我们这里将这些软件称为工具链。
小王的一天
下面,让我们跟随小张 - 是的,就是在风口创业公司的那位 - 看看在微服务架构下,研发工具链包含了哪些内容。
| 时间 | 工作 | 工具需求 | 备注 |
|---|---|---|---|
| 09:01 | 打开浏览器,登录公司内网 | 使用同一个账号,登录公司所有的内部系统。 | 暂不讨论“操作系统”、“浏览器”等通用软件。 |
| 09:03 | 打开代码审核平台,查看Review | 代码版本控制、代码托管,代码审核 | |
| 10:23 | 老张让我升级下xx的包,加了新接口 | 版本依赖管理系统 | 我们将开发语言暂时限定为Java |
| 11:56 | 修改了一部分逻辑,午饭前抓紧提交上去,看能否跑通所有Case | 持续集成(Continuous integration)系统 | 暂不讨论“IDE”等通用软件。 |
| 15:20 | 功能开发完毕,上线! | 持续交付(Continuous delivery)系统 | |
| 16:03 | X功能重构,拆分到两个微服务中 | 微服务开发辅助工具 |
研发工具链
小张的公司还处于创业阶段,出于节省成本的考虑,我们尽量选择开(mian)源(fei)的解决方案:
-
内部帐号统一管理:在企业的内部,存在许多内部系统。出于安全性、管理性的考虑,需要统一的帐号管理系统。这里我们选用OpenLDAP:一款的开源的帐号管理服务,它实现了广泛使用的“轻量级目录管理协议”(LDAP v3),可以轻松对接各类系统的帐号管理功能。
-
代码管理:团队协作的软件开发模式,需要版本控制系统。我们选用了Git做为代码的版本控制系统。在代码的托管、审核方面,Gerrit和GitLab都是成熟的开源解决方案。Gitlab上手容易,生态链更加成熟;Gerrit有一定上手门槛,在代码Review方面更加优秀。关于两者的讨论,可以参考这篇帖子。经过多方面的综合考虑,我们选择了GitLab。
-
版本依赖系统:在Java开发中,Maven是依赖管理的事实标准。同时在企业开发中,不希望将私有包发布到公开仓库中,我们选用Nexus Repository OSS搭建私有的Maven仓库。
-
持续集成、持续交付,持续部署是三个既相近又重要的概念,我们将在下一小节展开讨论。
-
微服务辅助开发工具:在微服务架构下,新增微服务、升级pom版本,接口变更等操作会频繁发生。需要开发一些辅助工具,提升研发效率。我们会在后面展开讨论。
针对上述选择的工具,我们会在后续章节详细介绍。
微服务辅助开发工具
结合微服务的开发特点,我们需要这样一些辅助工具:
-
自动创建新的微服务:包括从模板项目生成微服务代码、自动创建git项目、部署项目
-
RPC桩文件生成:在RPC的(IDL)接口文件变更后,需要重新生成桩文件,这个步骤较为繁琐,需要工具辅助完成。
-
pom版本自动升级:微服务之间的版本依赖,更新会更加频繁,我们需要一个工具,自动修改pom版本
这里我们只初步讨论一下需求,具体的实现会在后续章节展开。
持续集成、持续部署、持续交付
标题里的三个“持续”在前几年特别火热,属于技术热词(BuzzWord)。
持续交付(Continuous Delivery)由马丁·福勒(Martin Fowler)于2006年提出。
是的,你没看错,又是马丁·福勒,那位提出微服务的大神。
歪个楼,介绍一些马丁·福勒的代表作:
-
《重构:改善既有代码的设计》
-
《企业应用架构模式》
-
《敏捷软件开发宣言》(联合)
-
“微服务”、“持续部署” ....
以上任何一条单独拿出来,都足以封神。
言归正传,我们在一本“微服务”的书中讨论持续交付,仅仅因为它是由大神提出的么?
当然不是,我们将在本文的末尾再讨论这个问题。
这篇文章很好的阐述了三个概念的联系与区别,我们展开讨论。
持续集成
小王每次向gitlab提交一个代码,就会触发一次项目的自动构建、运行单元测试,这就是持续集成(Continuous Integration)。如下图所示:
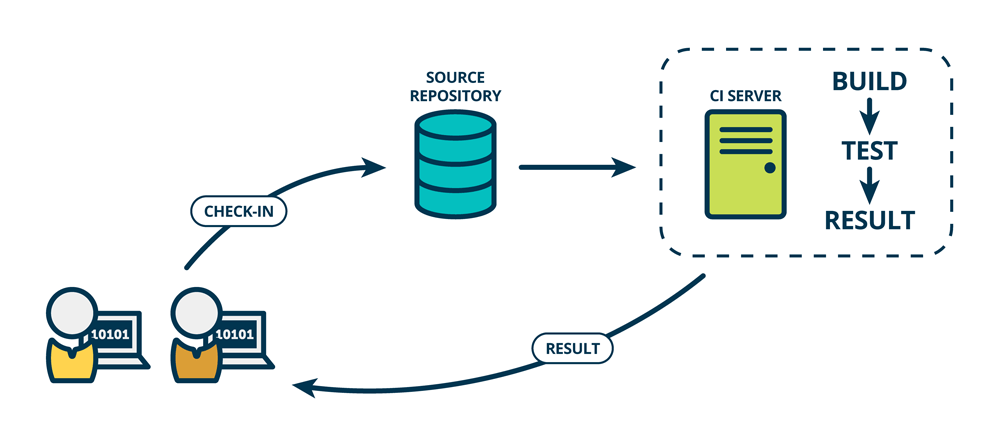
假设小王在提交中引入了一个Bug,借助CI流程(中的集成 or 单元测试),我们就能在第一时间发现,并尽早修复问题。
管理学大师戴明指出:“问题发现的越早,修复的成本越低”。通过持续集成,我们可以尽早发现问题,从而降低(修复问题带来的)返工成本。
持续部署
持续部署(Continuous Deployment)指的是:在持续集成(成功)的基础上,自动将服务部署到"类似于线上"的环境中,如下图所示:
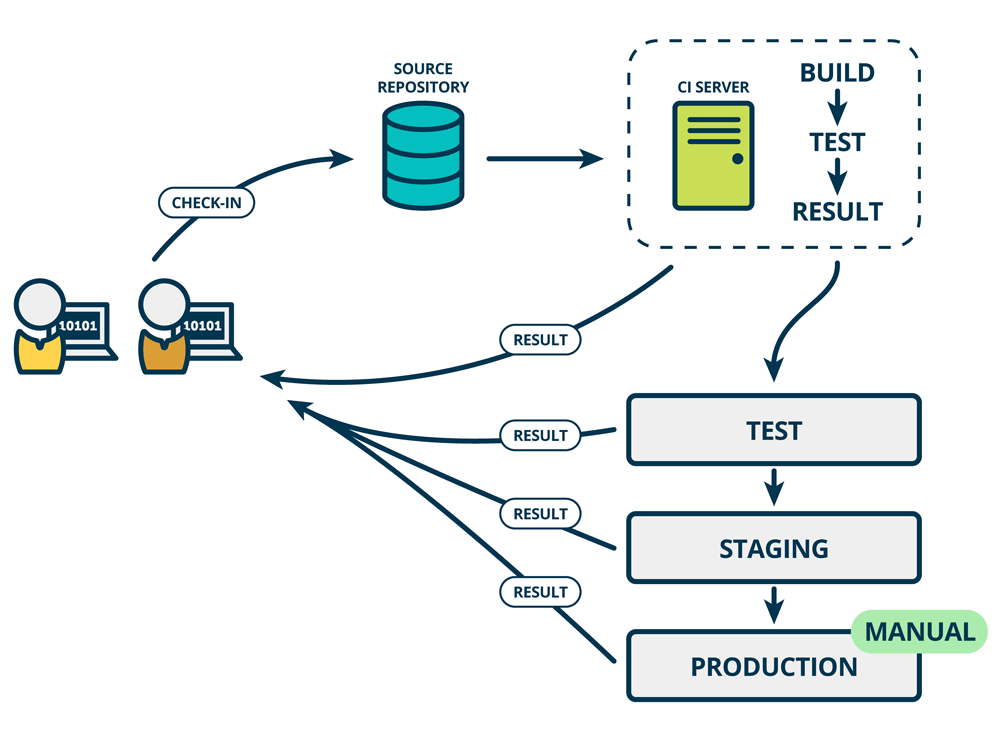
为什么要部署到"类似于线上环境"呢?因为代码只在"集成阶段"通过了一部分"单元测试",假设单元测试覆盖不全,甚至还需要人工测试,那就可能将隐含的Bug发布到线上,造成生产事故。
图中画的"TEST"(测试环境)、"STAGING"(预发环境),都是这类"类似线上环境"。当新版本通过最终确认后,再手动(MANUAL)部署到线上。
持续交付
持续交付(Continuous Delivery)在持续部署的基础上,更近了一步:成功发布到"类似生产环境"后,会继续自动发布到线上,如下图所示:
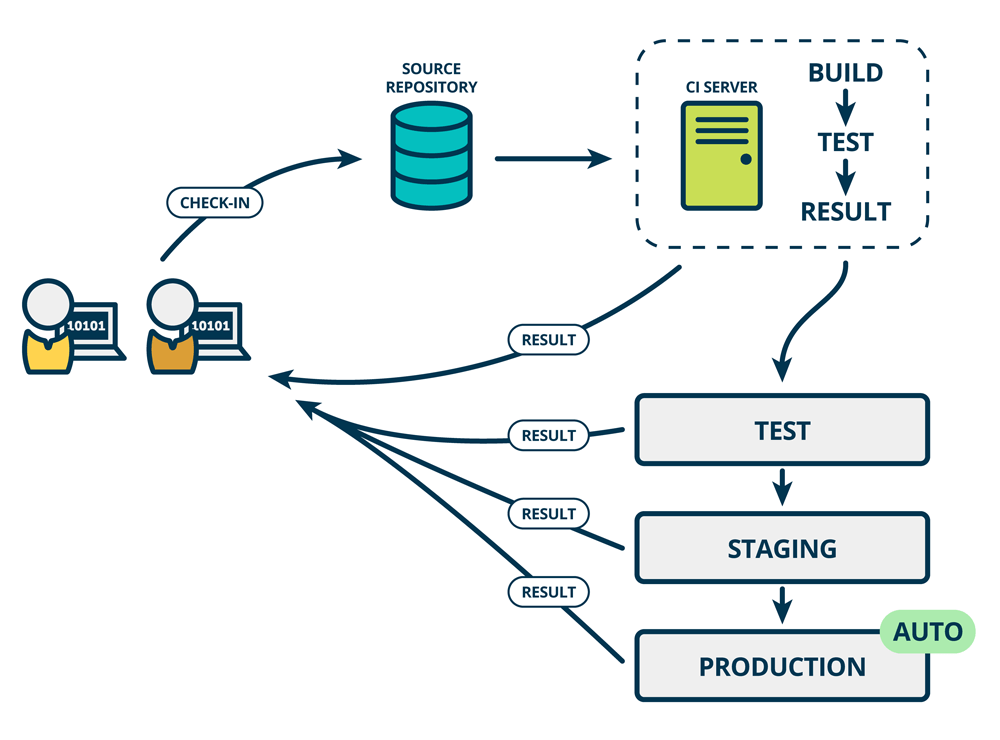
显然,这种"自动发布"需要极强的自信和勇气。这可能源于充分的单元测试,清晰的架构,以及对业务能力的自信。
实际上业界只有极少数公司"从容地"实现了上述意义上的"持续交付"。
其余宣称实现了"持续交付"的公司,或者混淆了持续部署的概念,或者对技术故障存在较大容忍度。 (先发布再灰度,难道不是一种容忍?)
这并不是高级黑,如果你认真做过一段时间软件开发,应该能明白“即使100%的单测覆盖率,也不能自动检查出尚未发现的Bug”,更何况绝大多数项目根本无法达到100%单元覆盖率。
我们回到本文开头的问题:为什么要在一本“微服务”的书中,讨论持续部署?
还记得微服务概述一节中,微服务的缺点么?可靠性陷阱、运维复杂度升高。
-
借助持续集成,能够尽早发现缺陷,提升微服务架构下的可靠性。
-
应用持续部署,可以上线效率,降低运维难度。
由此可见,持续集成、持续部署,能够切实解决微服务中存在的问题。我们将在本书的后续章节,打造自己的持续集成系统,敬请期待。
一种微服务的分层架构
在上一小节,我们讨论了微服务架构“的的特征、优缺点等话题。
你可能对微服务有了一个模糊的概念,依然感觉不够清晰。
这种感受能够理解。因为,微服务的理论只是提供了一种“架构风格”的建议,并不包含具体的实施方案。
下图展示了一种微服务的分层架构:

让我们自底向上、逐层分解:
-
基础设施层
基础设施层涵盖了服务端运行时,所需要的物理资源。包括:计算资源、存储资源、网络资源等。
针对小型公司,可以直接选用云计算平台的资源(如阿里云、AWS等);中大型公司出于成本、审计等因素,会自建机房或混合云。
计算资源:CPU、GPU、内存等。除了CPU的核数、内存容量,配比等常见问题,还需要考虑计算资源的弹性伸缩能力,即如何应对“平台大促”等场景带来的流量提升。
存储资源:不仅要考虑磁盘容量,还要考虑磁盘性能([IOPS](IOPS - 维基百科,自由的百科全书))。举个例子:服务端日志主要是顺序写,异步处理 + 大容量机械磁盘就能满足要求;对MySQL等数据库场景,涉及大量随机读,使用SSD可以显著提升性能。
网络资源:外网带宽(峰值)、内网带宽、负载均衡、VPC等。内外网带宽问题较为常见,我们不再讨论。负载均衡:当业务流量规模升高后,接入层的传统软负载解决方案(Nginx、LVS)会显得力不从心。硬件负载均衡(F5)可以提供更高的性能,但做为专用计算的商业产品,其价格在百万以上。这几年,随着Kernel By Pass技术的兴起,基于X86通用硬件 + Linux的的软负载均衡也取得一定的性能突破,感兴趣的话,可以参考这篇文章。
基础设施层的技能栈主要是:运维、网络建设,我们不在本书中做更多讨论。
-
运维平台层
运维平台层是“持续交付”的重要载体,包括:
持续部署系统:构建从代码仓库、持续集成、持续部署的全链路系统、最终实现持续交付。
部署的版本管理系统:管理部署镜像粒度的版本,以支持滚动发布、回滚等部署功能。
容器、容器管理调度平台:容器是一种操作系统级的轻量虚拟化技术。在部署系统中,不仅需要容器技术、还需要容器调度管理系统。这两项技术我们会在后续章节展开讨论。
-
微服务设施层
本层为微服务的开发和运行提供公用的设施基础。
在这里我们只做基本介绍,在后续章节会详细展开。
开发框架:微服务的开发需要一些基础的编程框架,可以自己从零搭建,也可以基于成熟开源框架完善。
RPC:微服务内部使用RPC(Remote Procedure Call)完成通信。
服务注册与发现:微服务A调用服务B且后者有3个实例,如何感知这3个实例的IP、端口,以及A要调用哪个实例呢?这就是服务的注册与发现问题,是微服务的核心问题之一。
配置中心:微服务的数量、实例众多,逐一修改配置文件的传统模式,既不经济又容易出错。配置中心是一个中央(但不一定是单机)配置系统,负责配置管理、修改等工作。
熔断:当微服务调链路上,服务不可用或响应时间太长时,触发熔断,快速提前返回。举个例子:家里有用电设备路时电流过大,空气开关会直接跳闸,防止造成进一步的破坏。
限流:为了保护服务不被流量击垮,而提前限制流量。举个例子:经过测算,故宫接待能力是每日1万人。那么当天超过1万后,就触发限流,不让更多游客入园。
数据库:传统的SQL数据库用于业务数据落盘,NoSQL数据库则用于缓存或高性能存取。
消息队列:将业务流量“削峰填谷”,对应对突发流量。
中间件:中间件是介于 服务端 与 数据库、消息队列等设施的中间。中间件帮助 业务服务更简单地使用这些基础设施。
近几年,“可观测性”成为了新的技术热词。这个舶来于控制理论的词,在软件系统中指的是:可以帮团队有效调试系统的工具或解决方案。以这个视角看,下述部分都是可观测性的一部分:
日志:如何在众多的微服务实例中,快速定位到某一种出错日志?日志平台实现了微服务实例中的日志收集、存储、检索、分析。
监控系统:通过采集多种指标,实时反馈系统运行状态,保证服务的平稳运行。举个生活中的例子:汽车驾驶位的仪表盘。
报警系统:当监控系统发现异常时,及时将报警发送出来。
链路追踪:当服务A->B->C调用链上发生超时,如何快速定位哪个环节发生了故障?链路追踪解决了分布式、复杂调用链路中的采集、追踪,分析工作。
-
业务服务层
借助“基础设施“、”运维平台“、”微服务设施“的帮助,我们可以更高效、稳健的应用微服务,实现业务目标。关于微服务的拆分、建模理论,可以参考“领域驱动设计”的相关内容,本书不做讨论。
-
聚合接入层
在“微服务概述”一节中,我们曾提到微服务的缺点之一:拆分导致的复杂度升高。在当前主流的前后端分离架构中,用户对这一拆分基本无感知。复杂度被转嫁到 前端 / 客户端 中:原本只需要调用一个接口,现在要分别调用N个微服务。还需要考虑时序关系、错误处理等。聚合接入层就是为解决这个问题而生的,他聚合多个微服务的调用,只保留必要字段,为前端 / 客户端提供了统一、清晰的服务接口。聚合接入层可以由服务端实现,有时还会加入部分熔断、限流等逻辑,组合成为微服务网关。聚合接入也可以由前端实现,有时也被称作BFF(Backend For Frontend)。
在剖析微服务的各层架构之后,不难发现:微服务的架构下,需要多个团队,多层系统、多纬度的支持。这也印证了在“微服务概述”一节中的观点:应用微服务架构,需要较高成本。
因此,尽量选用成熟、易维护的技术,从而尽可能降低成本,显得尤为重要。我们将在下一节展开讨论技术选型。
一种微服务分层架构的技术栈选型
我们在工具链、一种微服务的分层架构 两小节中讨论了技术栈的需求。
在本节中,我们将具体讨论技术栈的选型。
你可能注意到,上一节的标题是“一种微服务的分层架构”,而这一节的标题是“一种微服务分层架构的技术栈选型”。
加上“一种”这个词是有意而为之,请不要怀疑我的语文水平:-)
"一种"强调的是:
-
微服务只是一种架构风格,他可以有N种不同的实现,上一节只介绍了其中一种。
-
每一种微服务架构的实现,也可以对应N种不同的技术栈选型。
那么,在这N^2种架构 + 技术栈的组合种,哪一种才是最好的?
不急着回答,我们先来看下这个:
php is the best language for web programming.
这是PHP官方手册的原文,更多人更熟悉前5个单词,“PHP是全世界最好的语言”。
但加上后3个单词“for web programming”后,就变成了“PHP是web领域最好的语言”。
而我的观点(哪个架构更优) 与 PHP社区(关于语言优劣)的观点,是一致的:没有最好的语言(技术),只有最适合具体场景的。
因此,我们只会针对各项场景,列出技术选型,而不会打“为什么A比B好的”口水战。
容器管理平台的技术选型
微服务架构下会对服务进行拆分,产生大量的服务实例。
容器化技术,可以实现环境隔离、快速部署,是微服务架构的基石。
Docker凭借“快速”、“可移植性”等特性""一战成名",是单机或小规模应用部署的最佳选择
然而,在复杂的分布式部署场景中,"扩容"、"编排"、"故障恢复"等成为了"刚需",“容器管理平台”应运而生。在这个赛道上,曾经出现过三个主流产品:
-
swarm: Docker公司于2014年末推出的容器集群技术方案。尽管swarm是Docker公司的“亲儿子”、手握大量社区资源,但很快被Kubernetes超越。
-
Kubernetes: 简称k8s,支持自动部署,扩展和管理容器化应用程序的开源系统。k8s借鉴了Google的Borg管理系统,自问世以来发展迅猛,当前已经成为了容器管理的事实标准。
-
Marathon: 构建在[Apache Mesos](Apache Mesos)集群上的一套容器集群管理软件。由于Mesos的部署存在门槛,Marathon项目的关注度并不高,社区也并不活跃。其上一个发布版本依然停留在2019年,已经近2年没有更新。
因此,我们"毫无争议"地选择k8s作为微服务架构下的容器管理平台。
除了容器管理平台,我们还需要镜像仓库存储应用的容器镜像,我们将使用Docker搭建私有镜像仓库。
微服务设施层的技术选型
设施层涉及较多的技术需求,技术选型如下:
| 需求 | 选型 | 版本 |
|---|---|---|
| 开发语言 | Java | 8 |
| 开发框架 | Spring Boot | 2.5.4 |
| RPC | gRPC | 1.14.x |
| 服务注册 / 发现 / 配置中心 | Nacos | 2.x |
| 熔断 / 限流 | Resilience4j | 1.7.1 |
| SQL数据库 | MySQL | 8.0.X |
| 内存数据库 | Redis | 6.2 |
| 消息队列 | RocketMQ | 4.9.1 |
| 日志 | Kafka + ELK | 2.13 + 7.14.X |
| 监控 / 告警 | VictoriaMetrics + Grafana | 1.64.1 + 8.1.X |
| 链路追踪 | SkyWalking | 8.7.0 |
开发语言:我们选择了Java做为开发语言。与新近崛起的Go、Rust等语言相比,Java不是最完美的语言,但它依然拥有较高的开发、运行效率,最充足的人才供给。版本方面我们选择Java 8(最后一个免费的Java版本)。
开发框架:在Java开发领域,Spring生态的渗透率已超过60% ([出处](Spring dominates the Java ecosystem with 60% using it for their main applications | Snyk))。顺应这一趋势,我们选择Spring 生态内的Spring Boot做为主要开发框架。Spring Boot提供的注解配置、嵌入式容器、starter等特性,可以极大简化Java应用的开发。
RPC框架:我们选择开源的gRPC做为RPC框架,它使用Protocl Buffer序列化,HTTP 2传输协议,具有更灵活的通信模式和较高的传输效率。
服务注册、发现、配置中心:[Nacos](什么是 Nacos)是阿里巴巴开源的服务管理项目,同时具备服务注册、发现、配置中心。Nacos原生支持Spring Boot、k8s等融合方向。经过几年的发展,Nacos已经较为成熟,支撑了阿里巴巴、中国移动等数十家大型公司的线上系统。
熔断、限流:本书不会探讨Service Mesh等平台级别的流量控制方案。我们主要讨论服务进程级别的熔断、限流方案。老牌项目Hystrix停更后,我们选择开源的Resilience4j做为熔断、限流的Java库解决方案。
数据库:做为开源数据库的佼佼者,MySQL常年稳居市场份额的前三名。我们选择其较新的稳定版8.0.X。
内存数据库:做为SQL数据库的补充,内存数据库的应用场景是:吞吐量更大、延迟更低。高性能的Redis是最佳选择。根据官方评测,Redis 6.x在开启pipeline模式的前提下,可以提供高达55万RPS。
消息队列:Apache RocketMQ是阿里巴巴的开源的分布式消息队列,具有极低的延迟和较高的吞吐量。相比于老牌的Kafka,Rocket MQ更适用于消息队列的场景。我们选用其最新稳定版4.9.1。
日志:ELK是经典的日志日志方案。在此基础上,我们前置增加了Kafka,利用其强大的写能力,构建起缓冲队列,以应对海量日志的突发写入。
监控 / 告警:纵观DevOps领域,Prometheus + Grafana已经成为了监控领域的事实标准。然而,Prometheus并不支持原生的集群部署,其在大规模应用下很容易出现瓶颈。VictoriaMetrics是一款可以嵌入Prometheus的分布式时序存储引擎。起初VictoriaMetrics只想做一个引擎,在近几个版本社区加大了对vmagent的开发投入。vmagent是一款轻量级的代理,兼容Prometheus协议,可以直接替代Prometheus完成大部分工作。在本书中,我们直接选择VictoriaMetrics + Grafana做为兼容告警的默认技术栈。
链路追踪:SkyWalking是由国人主导的一款开源APM(application performance management)。在小米、滴滴等公司都有应用。我们选择其最新的稳定版本。
看了上面的文字,你可能有点困惑:“只是简单罗列选型结果,并没有具体分析过程“?
技术选型是一个非常大的话题,每一个点单独拎出来,都能洋洋洒洒的写一章出来,但是我觉得必要性不大,原因在于:
-
技术演进的速度非常快,今天适合的明天就有可能被淘汰(看看Docker)
-
每个公司面临的具体场景情况都是不同的,很难穷尽、更无法全部都满足
因此,我只是在自己可见的技术水平内,选择了相对靠谱的方案,解决了一部分“选择障碍的问题”,如果你有更优秀的选择,也欢迎提Issue交流、讨论。
微服务开发上篇:开发框架及其与RPC、数据库、Redis的集成
从这一章开始,我们正式进入微服务开发篇,共分上、中、下三篇。
本章我们将讨论开发框架,框架与RPC、数据库、Redis的集成。
2001年,我刚开始编程时,接触的第一个语言是"ASP"(没有.net),它通过脚本注解的方式,实现动态功能(存取数据库等),有点类似于PHP。在那个没有开发框架的年代,我们依然可以实现功能。但是这里只是“功能上的满足”,确无法做到“工程上的最优”,例如:
-
HTML与脚本混编,无论是页面样式修改,还是逻辑修改都很麻烦(视图、逻辑混合)
-
有不少功能重复的代码,无法复用(如创建数据库连接)
-
页面之间的内部依赖难以处理(往往只能通过url / session参数传递)
开发框架的出现,解决了上述部分问题,以Spring为例:
-
Spring MVC实现的分层架构,将页面、视图、逻辑层强制分离
-
Spring JPA组件可以创建数据库模板,减少重复代码
-
通过IoC容器,可以清晰地分离逻辑、处理依赖
-
....
当然,引入开发框架会带来额外的学习成本。Spring Boot借鉴了ROR框架中“约定优于配置”的设计理念,进行了大量的改造,实现了框架的“开箱可用”,有效降低了学习成本。
本章会使用一个微服务为例,介绍Gradle + Spring Boot的基础集成。在此基础上,我们会介绍几个与框架紧密相关的内容:RPC框架、数据库、Redis的集成。
Gradle构建工具配置
构建工具解决了依赖管理、打包流程、项目结构工程化等问题,是现代软件开发中的必备工具。
Gradle是一款Java开发语言的构建工具,兼容POM以来,使用Groovy作为描述语言,构建速度快、可拓展性强,是大量项目的首选。
在本节中,我们将介绍Gradle的基本用法与配置。
Gradle的下载与安装
我们使用稳定版7.2,你可以在官网下载二进制版本。
解压缩后,需要将二进制目录加入你的PATH路径:
export PATH=$PATH:HOME/soft/gradle/bin/
然后执行gradle,查看是否安装成功
gradle -v
------------------------------------------------------------
Gradle 7.2
------------------------------------------------------------
Build time: 2021-08-17 09:59:03 UTC
Revision: a773786b58bb28710e3dc96c4d1a7063628952ad
Kotlin: 1.5.21
Groovy: 3.0.8
Ant: Apache Ant(TM) version 1.10.9 compiled on September 27 2020
JVM: 1.8.0_291 (Oracle Corporation 25.291-b10)
OS: Mac OS X 10.16 x86_64
修改Gradle的Maven仓库镜像
gradle的依赖使用了Maven的仓库。由于众所周知的原因,这些仓库在国内的速度并不稳定,我们需要将仓库切换成国内镜像。
修改~/.gradle/init.gradle文件如下:
// project
allprojects{
repositories {
mavenLocal()
maven { url 'https://maven.aliyun.com/repository/public/' }
maven { url 'https://maven.aliyun.com/repository/jcenter/' }
maven { url 'https://maven.aliyun.com/repository/google/' }
maven { url 'https://maven.aliyun.com/repository/gradle-plugin/' }
maven { url 'https://jitpack.io/' }
}
}
// plugin
settingsEvaluated { settings ->
settings.pluginManagement {
// Clear repositories collection
repositories.clear()
// Add my Artifactory mirror
repositories {
mavenLocal()
maven {
url "https://maven.aliyun.com/repository/gradle-plugin/"
}
}
}
}
解释下文件配置:
-
上半部分:将maven中央仓库、jcenter仓库都修改为国内镜像(阿里云),并增加了jitpack仓库(后续章节会使用)。
-
下半部分:将gradle插件仓库修改为国内镜像,这部分是必须的,不要忘记。
我们可以通过一个简单的脚本,检查配置是否生效
验证脚本build.gradle
task listrepos {
doLast {
println "Repositories:"
project.repositories.each { println "Name: " + it.name + "; url: " + it.url }
}
}
执行验证:
gradle listrepos
Repositories:
Name: MavenLocal; url: file:/Users/coder4/.m2/repository/
Name: maven; url: https://maven.aliyun.com/repository/public/
Name: maven2; url: https://maven.aliyun.com/repository/jcenter/
Name: maven3; url: https://maven.aliyun.com/repository/google/
Name: maven4; url: https://maven.aliyun.com/repository/gradle-plugin/
Name: maven5; url: https://jitpack.io/
IntelliJ
gradle-wrapper生成
gradle-wrapper是用于执行gradle的脚本 + 精简版的gradle二进制文件。
既然已经有了gradle,为什么还要单独弄一个wrapper出来么?
-
方便没有安装gradle的环境执行构建(例如打包机)
-
支持多版本gradle的快速切换(实现nvm的效果)
初始化gradle项目时,执行如下命令:
gradle init
gradle会生成如下wrapper相关文件:
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
└── settings.gradle
建议将上述文件一并加入git仓库中,以防出现版本兼容问题。
IntelliJ IDEA中配置Gradle
IntelliJ IDEA是一款功能强大的IDE,是许多Java程序员的首选。
IDEA默认支持Gradle,请确保配置正确:
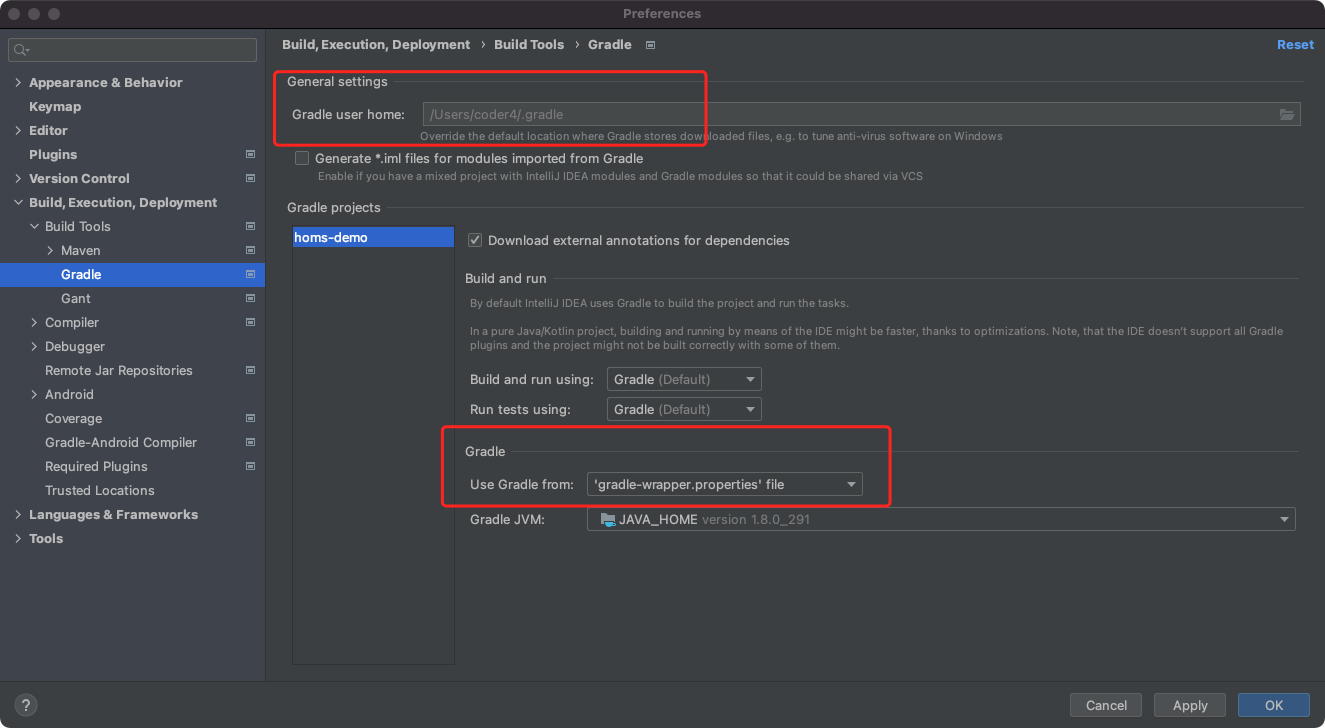
上方的Gradle配置文件默认路径,请维持默认配置,使用家目录下默认的。
下方的Gradle版本,推荐使用默认选项(gradle-wrapper.properties),即使用项目路径下gradle-wrapper.properties指定的版本。
经过上述配置,我们已经搭建了Gradle的构建环境。在下一节,我们会在此基础上集成Spring Boot框架。
Sprint Boot项目与Gradle的集成
本节我们将借助Spring Start快速搭建微服务项目。
在此基础上,我们会将工程改造成子项目的组织形式。
Spring Start快速生成项目
为了降低微服务的开发门槛,社区提供了Spring initializr工具。它可以一键生成微服务项目。如图所示:
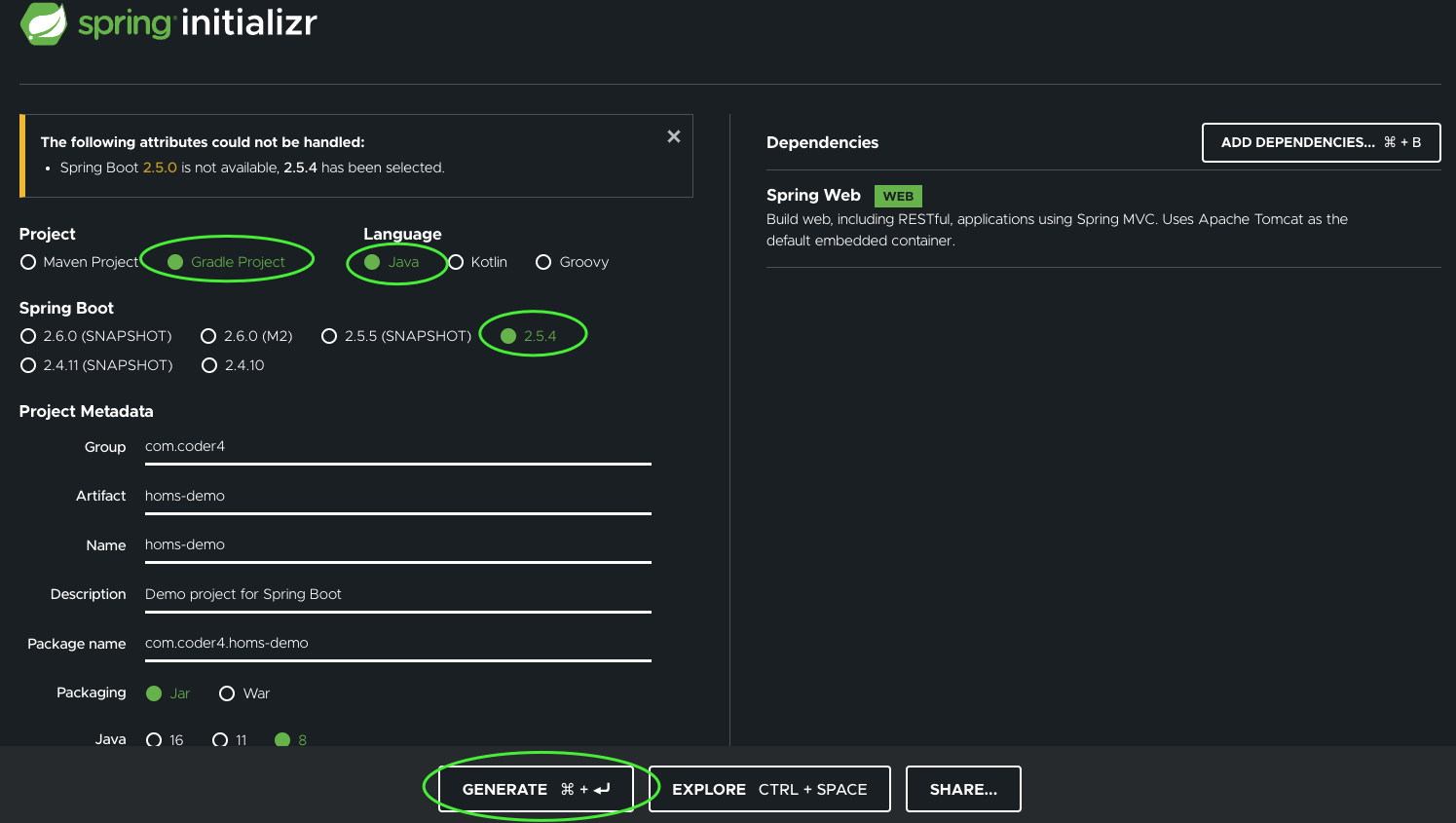
我们需要注意几个配置:
-
Project(项目):选择Gradle
-
Language(开发语言):选择Java
-
Spring Boot(版本):选择2.5.4
-
下面的工程名、包名根据自己的需要填写
-
Java(版本):选择8
完成后,点击下方的GENERATE(生成)按钮,即可下载项目的zip包。
解压缩后,目录结构如下:
.
├── HELP.md
├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── settings.gradle
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── coder4
│ │ └── homsdemo
│ │ └── HomsDemoApplication.java
│ └── resources
│ ├── application.properties
│ ├── static
│ └── templates
└── test
└── java
└── com
└── coder4
└── homsdemo
└── HomsDemoApplicationTests.java
这是一个标准的gradle项目路径:
- gradle*:gradle相关文件,可以参考Gradle构建工具配置一节中的介绍
- src:项目源文件
- test:项目单元测试文件
我们来看一下src目录下唯一的Java源文件,HomsDemoApplication.java:
package com.coder4.homsdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class HomsDemoApplication {
public static void main(String[] args) {
SpringApplication.run(HomsDemoApplication.class, args);
}
}
借助Spring Boot的精简设计,项目只需上述一个源文件即可服务端进程
编译项目:
gradle build
BUILD SUCCESSFUL in 19s
7 actionable tasks: 7 executed
运行项目:
java -jar ./build/libs/homs-demo-0.0.1-SNAPSHOT.jar
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.5.4)
2021-09-08 12:47:51.906 INFO 2806 --- [ main] com.coder4.homsdemo.HomsDemoApplication : Starting HomsDemoApplication using Java 1.8.0_291 on coder4deMacBook-Pro.local with PID 2806 (/Users/coder4/Downloads/homs-demo/build/libs/homs-demo-0.0.1-SNAPSHOT.jar started by coder4 in /Users/coder4/Downloads/homs-demo)
2021-09-08 12:47:51.909 INFO 2806 --- [ main] com.coder4.homsdemo.HomsDemoApplication : No active profile set, falling back to default profiles: default
2021-09-08 12:47:52.960 INFO 2806 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2021-09-08 12:47:52.975 INFO 2806 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2021-09-08 12:47:52.975 INFO 2806 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.52]
2021-09-08 12:47:53.032 INFO 2806 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2021-09-08 12:47:53.032 INFO 2806 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1067 ms
2021-09-08 12:47:53.413 INFO 2806 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2021-09-08 12:47:53.424 INFO 2806 --- [ main] com.coder4.homsdemo.HomsDemoApplication : Started HomsDemoApplication in 1.951 seconds (JVM running for 2.388)
我们在浏览器打开 http:127.0.0.1:8080 已经可以成功打开了!
在微服务架构中,需要新建大量微服务。而Spring社区提供的Starter工具,降低了微服务的初始化门槛。在实际开发中,我们也可以结合实际情况,定制出适合自己团队的脚手架工具。
子项目改造
上述脚手架生成的项目,是独立项目模式:一个目录下,只有一个独立项目。
在实际微服务开发中,一个目录下需要多组相互关联的子项目,例如:
-
protobuf和桩文件单独拆成子项目
-
常量提取到单独子项目
在本书的实战中,我们的微服务选用的是server / client 双子项目结构
-
client:内置protobuf、桩文件,客户端代码、自动配置代码
-
server:专注服务端逻辑开发
将Gradle项目拆分为子项目的功能,网上资料不多,自己摸索需要踩很多坑。
本文提供的也只是一种实现方式,你可以在此基础上,进行改造。
先看下整体目录结构:
./├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── homs-demo-client
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── com
│ └── coder4
│ └── homs
│ └── demo
│ ├── HomsDemo.proto
│ ├── HomsDemoGrpc.java
│ ├── HomsDemoProto.java
│ └── client
│ └── HomsDemoClient.java
├── homs-demo-server
│ ├── build.gradle
│ └── src
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── coder4
│ │ │ └── homs
│ │ │ └── demo
│ │ │ └── server
│ │ │ ├── Application.java
│ │ └── resources
│ │ └── application.yaml
│ └── test
│ └── java
│ └── com
│ └── coder4
│ └── homs
│ └── demo
│ └── server
│ └── Test.java
└── settings.gradle
如上图所述,我们在独立项目的基础上,改造如下:
-
新增homs-demo-client / homs-demo-server 两个子项目
-
子项目内,额外添加了build.gradle文件
下面我们来看下gradle的相关配置
首先是根目录下的
settings.gradle
rootProject.name = 'homs-demo'
include 'homs-demo-client'
include 'homs-demo-server'
如上所述,定义了项目名为"homs-demo",两个子项目"homs-demo-client" 和 "homs-demo-server"。
接着看一下根目录下的
build.gradle
plugins {
id 'java'
id 'idea'
id 'org.springframework.boot' version '2.5.3' apply false
id 'io.spring.dependency-management' version '1.0.11.RELEASE' apply false
}
subprojects {
group = 'com.coder4'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
}
这里的plugin部分,定义了4个插件:
-
java:java项目必选
-
idea (Intellj IDEA):生成idea需要的文件
-
org.springframework.boot:Spring Boot插件,支持构建可执行的server.jar
-
io.spring.dependency-management:Spring Boot相关版本的依赖管理
subprojects部分定义了所以子项目(server / client)的公用参数
-
group / version 项目包名和版本
-
sourceCompatibility:Java 8的语言版本
我们再来看一下client子项目
homs-demo-client/build.gradle
plugins {
id 'java'
id 'io.spring.dependency-management'
}
dependencies {
implementation "org.slf4j:slf4j-api:1.7.32"
}
上述是client子项目的gradle配置,不难发现:
-
plugins:java、spring依赖
-
dependencies:这里的配置等同于maven的pom.xml中的依赖配置,但gradle以冒号分割的语法更加简洁。这里只配置了一个slf4j。
再看下server子项目
plugins {
id 'java'
id 'org.springframework.boot'
id 'io.spring.dependency-management'
}
dependencies {
implementation project(':homs-demo-client')
implementation 'org.slf4j:slf4j-api:1.7.32'
implementation 'org.springframework.boot:spring-boot-starter-web'
}
server与client有所不同:
-
plugins:增加了spring boot插件
-
dependencies:首先依赖了客户端子项目,接着依赖Spring Boot的web-starter。
你可能已经注意到了,在server的依赖中,并没有设定spring-boot-starter-web的版本。
Spring相关依赖的版本补全由'dependency-management'插件自动处理。当我们在项目根路径的build.gradle中,声明Spring Boot插件和Dependency Management时,就确定了所有子项目中,Spring依赖的版本。
经过上述改造,我们已经“基本”完成了子项目的改造。
实现BOM功能
为什么我们说“基本”完成呢?
因为,子项目改造引入了新的问题:
若在client和server中,各自依赖slf4j但版本不同,会发生什么情况?
没错,这就是经典的“Maven依赖冲突”问题,关于背景和常见解法可以参考[这篇](Solving Dependency Conflicts in Maven - DZone Java)文章。
依赖冲突问题的最根本解法是:让大家都依赖于相同的版本。在Maven中可以使用bom清单(bill of material):将所有公用包的版本都声明在bom文件中,然后其余项目都依赖bom。
Gradle并没有直接实现BOM,但在6.0+支持了platform机制。它可以实现与BOM类似的效果。
我们新建一个独立的项目,bom-homs
settings.gradle
rootProject.name = 'bom-homs'
这里声明了bom的名字
build.gradle
plugins {
id 'java-platform'
id 'maven-publish'
}
group 'com.coder4'
version '1.0'
dependencies {
constraints {
api 'org.slf4j:slf4j-api:1.7.32'
}
}
publishing {
publications {
myPlatform(MavenPublication) {
from components.javaPlatform
}
}
}
上述配置的解析如下:
-
plugins:platform和maven发布插件
-
group、version:maven中同等概念,一会用到
-
dependencies:公用包的版本声明,这里只又一个slf4j
-
publishing:这里借用了Maven的发布方式
下面我们执行发布(到本地):
gradle publishToMavenLocal
BUILD SUCCESSFUL in 704ms
3 actionable tasks: 3 executed
(这里我们暂时发布到本地,如何发布到远程、私有仓库,将在后续章节再介绍。)
成功发布后,我们回到homs-demo项目中,将server的子项目改造如下:
plugins {
id 'java'
id 'org.springframework.boot'
id 'io.spring.dependency-management'
}
dependencies {
implementation project(':homs-demo-client')
implementation platform('com.coder4:bom-homs:1.0')
implementation 'org.slf4j:slf4j-api'
implementation 'org.springframework.boot:spring-boot-starter-web'
}
通过引入platform,我们就无需在项目中指明slf4j的版本了,从而在源头上解决了版本冲突的问题!
针对client子项目,也是类似的修改,这里不做赘述。
至此,我们完成Gradle与Spring Boot的集成、子项目拆分。
关于“Spring Boot + Gradle子项目”的资料,在网上并不多见,希望你能仔细阅读、反复揣摩、举一反三:-)
本文涉及的项目代码,我整理到了这里,供大家参考。
Spring Boot集成SQL数据库1
从银行的交易数据到打车订单,衣食住行,都离不开数据库的存储。
在接下来的两个小节中,我们将通过3种不同的技术,在Spring Boot中集成MySQL数据库。
-
JDBC
-
MyBatis
-
JPA (Hibernate)
本节的前半部分,我们将通过Docker快速搭建MySQL的环境,随后介绍JDBC的集成方式。
搭建MySQL实验环境
本书的重点是讨论微服务实战,我们直接使用Docker的方式,快速搭建实验环境。
如果你想部署在生产环境,请参考官方部署文档。
首先,请确认已经成功安装了Docker:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
若尚未安装Docker,可以参考[官方文档](Install Docker Engine | Docker Documentation)。
MySQL的Docker运行脚本如下:
#!/bin/bash
NAME="mysql"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/mysql"
MYSQL_ROOT_PASS="123456"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--volume "$VOLUME":/var/lib/mysql \
--env MYSQL_ROOT_PASSWORD=$MYSQL_ROOT_PASS \
--env PUID=$PUID \
--env PGID=$PGID \
-p 3306:3306 \
--detach \
--restart always \
mysql:8.0
如脚本所述:
-
使用官方的8.0镜像启动Docker
-
退出后自动重启
-
暴露3306端口到本机
-
设置Volume盘到~/docker_data/mysql路径下
-
root密码123456(请务必更改为安全密码)
执行后的效果:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
feb2838197a6 mysql:8.0 "docker-entrypoint.s…" 46 hours ago Up 7 hours 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql
启动成功后,我们尝试连接数据库,新建库并授权给用户:
mysql -h 127.0.0.1 -u root -p
> CREATE DATABASE homs_demo;
> CREATE USER 'HomsDemo'@'%' identified by '123456';
> GRANT ALL PRIVILEGES ON homs_demo.* TO 'HomsDemo'@'%';
尝试用新用户登录:
mysql -h 127.0.0.1 -u HomsDemo -p homs_demo
若能成功登录,我们创建本书实验所需的表:
CREATE TABLE `users` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(64) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这里我们创建了表users,有两个列:id和name。
温馨提示:我们使用utf8mb4字符集,如果用utf8是会有坑,可以参考这篇文章。强烈推荐你对所有的数据表,都设置为utf8mb4。
Spring Boot 集成 JDBC操作MySQL
我们先通过集成jdbc的方式操作MySQL数据库。
首先在server项目的build.gradle中添加依赖
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'mysql:mysql-connector-java:8.0.20'
上述依赖中:
-
spring-boot-starter-jdbc是集成jdbc的starter依赖包
-
mysql-connector-java是集成MySQL的驱动
接着,我们配置下数据源:
spring.datasource:
url: jdbc:mysql://127.0.0.1:3306/homs_demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false
username: HomsDemo
password: 123456
hikari:
minimumIdle: 10
maximumPoolSize: 100
上述配置分为两部分:
-
spring.datasource.url / username / password定义了MySQL的访问链接
-
hikari是数据库连接池的配置。
Hikari是Spring Boot 2默认的链接池,官方性能评测优秀。这里我们配置了minimumIdle(最小连接数)和maximumPoolSize(最大连接数)两个选项。更多配置参数可以参考[官方文档](GitHub - brettwooldridge/HikariCP: 光 HikariCP・A solid, high-performance, JDBC connection pool at last.)。
经过上述的组合配置后,对应DataSource对应的Configuration会自动激活,并注册一系列的关联Bean。
下面让我们使用它访问MySQL数据库:
@Repository
public class UserRepository1Impl implements UserRepository {
@Autowired
protected NamedParameterJdbcTemplate db;
private static RowMapper<User> ROW_MAPPER = new BeanPropertyRowMapper<>(User.class);
@Override
public Optional<Long> create(User user) {
String sql = "INSERT INTO `users`(`name`) VALUES(:name)";
SqlParameterSource param = new MapSqlParameterSource("name", user.getName());
KeyHolder holder = new GeneratedKeyHolder();
if (db.update(sql, param, holder) > 0) {
return Optional.ofNullable(holder.getKey().longValue());
} else {
return Optional.empty();
}
}
@Override
public Optional<User> getUser(long id) {
String sql = "SELECT * FROM `users` WHERE `id` = :id";
SqlParameterSource param = new MapSqlParameterSource("id", id);
try {
return Optional.ofNullable(db.queryForObject(sql, param, ROW_MAPPER));
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
@Override
public Optional<User> getUserByName(String name) {
String sql = "SELECT * FROM `users` WHERE `name` = :name";
SqlParameterSource param = new MapSqlParameterSource("name", name);
try {
return Optional.ofNullable(db.queryForObject(sql, param, ROW_MAPPER));
} catch (EmptyResultDataAccessException e) {
return Optional.empty();
}
}
}
在上面的代码中,我们自动装配了"NamedParameterJdbcTemplate",然后用它访问MySQL数据库:
-
读请求使用db.query,配合RowMapper做类型转化
-
写请求使用db.update,配合KeyHolder获取自增主键
使用JDBC访问MySQL的方式,优点和缺点是完全一样的:使用显示的SQL语句操作数据库。
优点:直接、方便代码Review和性能检查
缺点:SQL编写过程繁琐、易错,特别是对于CRUD请求,效率较低
Spring Boot集成SQL数据库2
Spring Boot 集成 MyBatis操作MySQL
MyBatis是一款半自动的ORM框架。由于某国内大厂的广泛使用,MyBatis在国内非常火热(在国外其热度不如Hibernate)。
首先还是集成依赖:
implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.2.0'
implementation 'mysql:mysql-connector-java:8.0.20'
套路与jdbc类似,但starter并不是官方的了,而是mybatis自己做的starter,感兴趣的可以来这里看下具体组成(会有惊喜)。
接下来是yaml配置环节:
spring.datasource:
url: jdbc:mysql://127.0.0.1:3306/homs_demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false
username: HomsDemo
password: 123456
hikari:
minimumIdle: 10
maximumPoolSize: 100
# mybatis extra
mybatis:
configuration:
map-underscore-to-camel-case: true
type-aliases-package: com.coder4.homs.demo.server.mybatis.dataobject
不难发现,数据库链接的定义复用了jdbc的那一套,MyBatis的定义分3行,如下:
-
configuration:开启驼峰规则转化
-
type-aliases-package:mapper文件存放的包名
更多MyBatis的配置选项可以参考[这里](mybatis-spring-boot-autoconfigure – Introduction)
接着,我们定义Mapper,在MyBatis中,Mapper相当于前面手写的Repository,定义如下:
package com.coder4.homs.demo.server.mybatis.mapper;
import com.coder4.homs.demo.server.mybatis.dataobject.UserDO;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
/**
* <p>
* Mapper 接口
* </p>
*
* @author author
* @since 2021-09-09
*/
@Repository
@Mapper
public interface UserMapper {
@Insert("INSERT INTO users(name) VALUES(#{name})")
@Options(useGeneratedKeys = true, keyProperty = "id")
long create(UserDO user);
@Select("SELECT * FROM users WHERE id = #{id}")
UserDO getUser(@Param("id") Long id);
@Select("SELECT * FROM users WHERE name = #{name}")
UserDO getUserByName(@Param("name") String name);
}
你可能会奇怪:这不是接口(interface)么,并没有实现?
是的,通过定义@Repository和@Mapper,MyBatis会通过运行时的切面注入,帮我们自动实现,具体执行的SQL和映射,会读取@Select、@Options等注解中的配置。
经过上述介绍,你可以发现:
MyBatis可以直接通过注解的方式快速访问数据库,(相对于JDBC的)精简了大量无用代码。
同时,MyBatis依然需要指定运行的SQL语句,这与JDBC的方式是一致的。虽然有些繁琐,但可以保证性能可控。
如果你在网上搜索"MyBatis Spring集成",会找到大量xml配置的用法。
在一些老项目中,xml是标准的集成方式。在这种配置方式下,配置繁琐、代码量大,即使借助"MyBatisX"等插件,也依然较为复杂。
因此,除非你要维护遗留的老项目代码,我都建议你使用(本文中)注解式集成MyBatis。
Spring Boot集成 JPA 操作MySQL
JPA的全称是Java Persistence API,即持久化访问规范API。
Spring也提供了集成JPA的方案,称为 Spring Data JPA,其底层是通过Hibernate的JPA来实现的。
首先集成依赖:
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'mysql:mysql-connector-java:8.0.20'
与前面类似,不再重复介绍。
接着是配置:
# jdbc demo
spring.datasource:
url: jdbc:mysql://127.0.0.1:3306/homs_demo?useUnicode=true&characterEncoding=UTF-8&useSSL=false
username: HomsDemo
password: 123456
hikari:
minimumIdle: 10
maximumPoolSize: 100
# jpa demo
spring.jpa:
database-platform: org.hibernate.dialect.MySQL8Dialect
hibernate.ddl-auto: validate
在MySQL连接上,我们依然复用了Spring DataSource的配置。
jpa侧的配置为:
-
database-platform:设置使用MySQL8语法
-
hibernate.ddl-auto:只校验表,不回主动更新数据表的结构
接着,我们来定义实体(Entity):
@Entity
@Data
@Table(name = "users")
public class UserEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
// @Column(name = "name")
private String name;
public User toUser() {
User user = new User();
user.setId(id);
user.setName(name);
return user;
}
}
这里我们将UserEntity与表"users"做了关联。
接下来是Repository:
@Repository
public interface UserJPARepository extends CrudRepository<UserEntity, Long> {
Collection<UserEntity> findByName(String name);
}
我们继承了CrudRepository,他会自动生成针对UserEntity的CRUD操作。
此外,我们还定义了1个额外函数:
- findByName,通过隐士语法规则,让JPA自动帮我们生成对应SQL
从直观感受上,JPA比MyBatis更加“高级” -- 一些简单的SQL都不用写了。
但天下真的有免费的馅饼么?我们先卖个关子。
JMJ应该选哪个
经过这两节的介绍,你已经掌握了JDBC、MyBatis、JPA三种操作数据库的方式。
在实战中,究竟要选哪个呢?
从易用性的角度来评估,我们可以得出结论:JPA > MyBatis > JDBC
那么从性能的角度来看呢?
我们使用wrk做了(get-by-id接口的)简单压测,结论如下:
| 读QPS | |
|---|---|
| JDBC | 457 |
| MyBatis | 445 |
| JPA | 114 |
这里,你会惊讶的发现:
-
JDBC和MyBatis的性能差别不大,在5%以内
-
JPA(Hibernate)的性能,居然只有其余两种方式的1/3
如此差的性能,真的让人百思不得其解,我尝试打印了SQL和执行耗时,并没有发现什么异常。
更进一步的,我们尝试用指定SQL的方式,替换了自动生成的接口,如下
@Repository
public interface UserJPARepository extends CrudRepository<UserEntity, Long> {
@Query(value = "SELECT * FROM users WHERE id = :id", nativeQuery = true)
Optional<UserEntity> findByIdFast(@Param("id") long id);
}
这次的压测结果是:447,性能基本和JDBC持平了。但是这种NativeSQL的用法并没有使用自动生成SQL的功能,没有发挥Hibernate本来的功效。
所以,我们认为,锅在于Hibernate自动生成SQL的逻辑耗时过大。
当然,Hibernate也不是一无是处,针对多层关联,建模复杂的场景,使用Entity做映射,会更加方便。
让我们回到前面的问题上:JMJ应该选哪个?
-
如果对性能有极致要求,建议JDBC或者MyBatis。
-
如果建模场景复杂,嵌套密集,且对性能要求不高,可以选用Hibernate。
Spring Boot集成gRPC框架
gRPC是谷歌开源的高性能、开源、通用RPC框架。由于gRPC基于HTTP2协议,所以其对移动端非常友好。
本节将介绍Spring Boot集成gRPC的服务端、客户端。
安装protoc及gRPC
gRPC默认使用[Protocol Buffers](Protocol Buffers | Google Developers)做为序列化协议,我们首先安装protoc编译器:
在这里下载最新版本的protoc编译器,请根据你的操作系统选择对应版本,这里我选用MacOSX的。
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.17.3/protoc-3.17.3-osx-x86_64.zip
unzip protoc-3.17.3-osx-x86_64.zip
解压缩后,将其加入PATH路径下:
export PATH=$PATH:$YOUR_PROTOC_PATH
试一下是能否执行:
protoc --version
libprotoc 3.17.3
除此之外,我们还需要一个gRPC的Java插件,才能生成gRPC的桩代码,你可以在[这里](Maven Central Repository Search)找到最新版本。这里我们依然选择OSX的64位版本:
wget https://search.maven.org/remotecontent?filepath=io/grpc/protoc-gen-grpc-java/1.40.1/protoc-gen-grpc-java-1.40.1-osx-x86_64.exe
下载后,将其加入PATH路径中。尝试定位一下:
which protoc-gen-grpc-java
Your_Path/protoc-gen-grpc-java
至此,protoc和grpc的安装准备工作已经就绪。
Client侧集成
首先是集成依赖,我们放在client子项目的builld.gradle中:
implementation 'com.google.protobuf:protobuf-java:3.17.3'
implementation "io.grpc:grpc-stub:1.39.0"
implementation "io.grpc:grpc-protobuf:1.39.0"
implementation 'io.grpc:grpc-netty-shaded:1.39.0'
由于版本依赖较多,我建议使用platform统一管理,可以参考前文。
接着,我们编写protoc文件,HomsDemo.proto:
syntax = "proto3";
option java_package = "com.coder4.homs.demo";
option java_outer_classname = "HomsDemoProto";
;
message AddRequest {
int32 val1 = 1;
int32 val2 = 2;
}
message AddResponse {
int32 val = 1;
}
message AddSingleRequest {
int32 val = 1;
}
service HomsDemo {
rpc Add(AddRequest) returns (AddResponse);
rpc Add2(stream AddSingleRequest) returns (AddResponse);
}
我们添加了两个RPC方法:
-
Add是正常的调用
-
Add2是单向Stream调用
接着,我们需要编译,生成桩文件:
#!/bin/sh
DIR=`cd \`dirname ${BASH_SOURCE[0]}\`/.. && pwd`
protoc HomsDemo.proto --java_out=${DIR}/homs-demo-client/src/main/java --proto_path=${DIR}/homs-demo-client/src/main/java/com/coder4/homs/demo/
protoc HomsDemo.proto --plugin=protoc-gen-grpc-java=`which protoc-gen-grpc-java` --grpc-java_out=${DIR}/homs-demo-client/src/main/java --proto_path=${DIR}/homs-demo-client/src/main/java/com/coder4/homs/demo/
这里分为两个步骤:
-
第一次protoc编译,生成protoc的桩文件
-
第二次protoc编译,使用了protoc-gen-grpc-java的插件,生成gRPC的服务端和客户端文件
编译成功后,路径如下:
homs-demo-client
├── build.gradle
└── src
└── main
└── java
└── com
└── coder4
└── homs
└── demo
├── HomsDemo.proto
├── HomsDemoGrpc.java
└── HomsDemoProto.java
如上所示:HomsDemoProto是protoc的桩文件,HomsDemoGrpc是gRPC服务的桩文件。
下面我们来编写客户端代码,HomsDemoClient.java:
package com.coder4.homs.demo.client;
import com.coder4.homs.demo.HomsDemoGrpc;
import com.coder4.homs.demo.HomsDemoProto.AddRequest;
import com.coder4.homs.demo.HomsDemoProto.AddResponse;
import com.coder4.homs.demo.HomsDemoProto.AddSingleRequest;
import io.grpc.Channel;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import io.grpc.StatusRuntimeException;
import io.grpc.stub.StreamObserver;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Collection;
import java.util.Optional;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
/**
* @author coder4
*/
public class HomsDemoClient {
private Logger LOG = LoggerFactory.getLogger(HomsDemoClient.class);
private final HomsDemoGrpc.HomsDemoBlockingStub blockingStub;
private final HomsDemoGrpc.HomsDemoStub stub;
/**
* Construct client for accessing HelloWorld server using the existing channel.
*/
public HomsDemoClient(Channel channel) {
blockingStub = HomsDemoGrpc.newBlockingStub(channel);
stub = HomsDemoGrpc.newStub(channel);
}
public Optional<Integer> add(int val1, int val2) {
AddRequest request = AddRequest.newBuilder().setVal1(val1).setVal2(val2).build();
AddResponse response;
try {
response = blockingStub.add(request);
return Optional.ofNullable(response.getVal());
} catch (StatusRuntimeException e) {
LOG.error("RPC failed: {0}", e.getStatus());
return Optional.empty();
}
}
public Optional<Integer> add2(Collection<Integer> vals) {
try {
CountDownLatch cdl = new CountDownLatch(1);
AtomicLong respVal = new AtomicLong();
StreamObserver<AddSingleRequest> requestStreamObserver =
stub.add2(new StreamObserver<AddResponse>() {
@Override
public void onNext(AddResponse value) {
respVal.set(value.getVal());
}
@Override
public void onError(Throwable t) {
cdl.countDown();
}
@Override
public void onCompleted() {
cdl.countDown();
}
});
for (int val : vals) {
requestStreamObserver.onNext(AddSingleRequest.newBuilder().setVal(val).build());
}
requestStreamObserver.onCompleted();
try {
cdl.await(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
return Optional.ofNullable(respVal.intValue());
} catch (StatusRuntimeException e) {
LOG.error("RPC failed: {0}", e.getStatus());
return Optional.empty();
}
}
}
代码如上所示:Add还是相对简单的,但是使用了Stream的Add2就比较复杂了。
在上述代码中,需要传入Channel做为连接句柄,在假设知道IP和端口的情况下,可以如下构造:
String target = "127.0.0.1:5000";
ManagedChannel channel = null;
try {
channel = ManagedChannelBuilder
.forTarget(target)
.usePlaintext()
.build();
} catch (Exception e) {
LOG.error("open channel excepiton", e);
return;
}
HomsDemoClient client = new HomsDemoClient(channel);
在微服务架构下,实例众多,获取每个IP显得不太实际,我们会在后续章节介绍集成服务发现的Channel构造方案。
Server侧集成
老套路,首先是依赖集成:
implementation 'com.google.protobuf:protobuf-java:3.17.3'
implementation "io.grpc:grpc-stub:1.39.0"
implementation "io.grpc:grpc-protobuf:1.39.0"
implementation 'io.grpc:grpc-netty-shaded:1.39.0'
与上述客户端的集成完全一致。
接下来我们实现RPC的服务逻辑:
/**
* @(#)HomsDemoImpl.java, 8月 12, 2021.
* <p>
* Copyright 2021 coder4.com. All rights reserved.
* CODER4.COM PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*/
package com.coder4.homs.demo.server.grpc;
import com.coder4.homs.demo.HomsDemoGrpc.HomsDemoImplBase;
import com.coder4.homs.demo.HomsDemoProto.AddRequest;
import com.coder4.homs.demo.HomsDemoProto.AddResponse;
import com.coder4.homs.demo.HomsDemoProto.AddSingleRequest;
import io.grpc.stub.StreamObserver;
/**
* @author coder4
*/
public final class HomsDemoGrpcImpl extends HomsDemoImplBase {
@Override
public void add(AddRequest request, StreamObserver<AddResponse> responseObserver) {
responseObserver.onNext(AddResponse.newBuilder()
.setVal(request.getVal1() + request.getVal2())
.build());
responseObserver.onCompleted();
}
@Override
public StreamObserver<AddSingleRequest> add2(StreamObserver<AddResponse> responseObserver) {
return new StreamObserver<AddSingleRequest>() {
int sum = 0;
@Override
public void onNext(AddSingleRequest value) {
sum += value.getVal();
}
@Override
public void onError(Throwable t) {
}
@Override
public void onCompleted() {
responseObserver.onNext(AddResponse.newBuilder()
.setVal(sum)
.build());
sum = 0;
responseObserver.onCompleted();
}
};
}
}
这里要特别说明,因为gRPC都是异步回调的方式,所以其RPC在实现上有点反直觉:
-
通过responseObserver.onNext返回调用结果
-
通过responseObserver.onCompleted结束调用
而add2方法,由于采用了Client-Streaming,所以实现会更加复杂一些。
实际上,gRPC支持[4种调用模式](Generated-code reference | Java | gRPC):
-
Unary: 客户端单输入,服务端单输出
-
Client-Streaming: 客户端多输入,服务端单输出
-
Server-Streaming: 客户端单输入,服务端多输出
-
Bidirectional-Streaming: 客户端多输入,服务端多输出
由于篇幅所限,本文种只实现了前2种,推荐你手动实现另外的两种模式。
Spring Boot集成Redis内存数据库
常规的业务数据,一般选择存储在SQL数据库中。
传统的SQL数据库基于磁盘存储,可以正常的流量需求。然而,在高并发应用场景中容易被拖垮,导致系统崩溃。
针对这种情况,我们可以通过增加缓存、使用NoSQL数据库等方式进行优化。
Redis是一款开源的内存NoSQL数据库,其稳定性高、[性能强悍](How fast is Redis? – Redis),是KV细分领域的市场占有率冠军。
本节将介绍Redis与Spring Boot的集成方式。
Redis环境准备
与前文类似,我们使用Docker快速部署Redis服务器。
#!/bin/bash
NAME="redis"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/redis"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--volume "$VOLUME":/data \
-p 6379:6379 \
--detach \
--restart always \
redis:6 \
redis-server --appendonly yes --requirepass redisdemo
在上述脚本中:
-
使用了最新的redis 6镜像
-
开启"appendonly"的持久化方式
-
启用密码"redisdemo"
-
端口暴露为6379
我们尝试连接一下:
redis-cli -h 127.0.0.1 -a redisdemo
成功!(如果你没有redis-cli的可执行文件,可以到官网下载)
Redis的缓存使用
Spring提供了内置的Cache框架,可以通过@Cache注解,轻松实现redis Cache的功能。
首先引入依赖:
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-json'
implementation 'org.apache.commons:commons-pool2:2.11.0'
上述依赖的作用分别为:
-
redis客户端:Spring Boot 2使用的是lettuce
-
json依赖:我们要使用jackson做json的序列化 / 反序列化
-
commons-pool2线程池,这里其实是data-redis没处理好,需要额外加入,按理说应该集成在starter里的
接着我们在application.yaml中定义数据源:
# redis demo
spring:
redis:
host: 127.0.0.1
port: 6379
password: "redisdemo"
lettuce:
pool:
max-active: 50
min-idle: 5
接着我们需要设置自定义的Configuration:
package com.coder4.homs.demo.server.configuration;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.ObjectMapper.DefaultTyping;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import java.time.Duration;
/**
* @author coder4
*/
@Configuration
@EnableCaching
public class RedisCacheCustomConfiguration extends CachingConfigurerSupport {
@Bean
public KeyGenerator keyGenerator() {
return (target, method, params) -> {
StringBuilder sb = new StringBuilder();
// sb.append(target.getClass().getName());
sb.append(target.getClass().getSimpleName());
sb.append(":");
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
sb.append(":");
}
sb.deleteCharAt(sb.length() - 1);
return sb.toString();
};
}
@Bean
public RedisCacheConfiguration redisCacheConfiguration() {
Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<Object>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, DefaultTyping.NON_FINAL);
// use json serde
serializer.setObjectMapper(objectMapper);
return RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(5)) // 5 mins ttl
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(serializer));
}
}
上述主要包含两部分:
-
KeyGenerator可以根据Class + method + 参数 生成唯一的key名字,用于Redis中存储的key
-
RedisCacheConfiguration做了2处定制:
-
更改了序列化方式,从默认的Java(Serilization更改为Jackson(json)
-
缓存过期时间为5分钟
-
接着,我们在项目中使用Cache
public interface UserRepository {
Optional<Long> create(User user);
@Cacheable(value = "cache")
Optional<User> getUser(long id);
Optional<User> getUserByName(String name);
}
这里我们用了@Cache注解,"cache"是key的前缀
访问一下:
curl http://127.0.0.1:8080/users/1
然后看一下redis
redis-cli -a redisdemo
> keys *
> "cache::UserRepository1Impl:getUser1"
> get "cache::UserRepository1Impl:getUser1"
"[\"com.coder4.homs.demo.server.model.User\",{\"id\":1,\"name\":\"user1\"}]"
> ttl "cache::UserRepository1Impl:getUser1"
> 293
数据被成功缓存在了Redis中(序列化为json),并且会自动过期。
我们使用Spring Boot集成SQL数据库2一节中的压测脚本验证性能,QPS达到860,提升达80%。
在数据发生删除、更新时,你需要更新缓存,以确保一致性。推荐你阅读[缓存更新的套路](缓存更新的套路 | 酷 壳 - CoolShell)。
在更新/删除方法上应用@CacheEvict(beforeInvocation=false),可以实现更新时删除的功能。
Redis的持久化使用
Redis不仅可以用作缓存,也可以用作持久化的存储。
首先请确认Redis已开启持久化:
127.0.0.1:6379> config get save
1) "save"
2) "3600 1 300 100 60 10000"
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "yes"
上述分别为rdb和aof的配置,有任意一个非空,即表示开启了持久化。
实际上,在我们集成Spring Data的时候,会自动配置RedisTemplte,使用它即可完成Redis的持久化读取。
不过默认配置的Template有一些缺点,我们需要做一些改造:
package com.coder4.homs.demo.server.configuration;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* @author coder4
*/
@Configuration
public class RedisTemplateConfiguration {
@Autowired
public void decorateRedisTemplate(RedisTemplate redisTemplate) {
RedisSerializer stringSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringSerializer);
redisTemplate.setKeySerializer(stringSerializer);
redisTemplate.setValueSerializer(stringSerializer);
redisTemplate.setHashKeySerializer(stringSerializer);
redisTemplate.setHashValueSerializer(stringSerializer);
}
}
如上所述,我们设置RedisTemplate的KV,分别采用String的序列化方式。
接着我们在代码中使用其存取Redis:
@Autowired
private RedisTemplate redisTemplate;
redisTemplate.boundValueOps("key").set("value");
RedisTemplate的语法稍微有些奇怪,你也可以直接使用Conn来做操作,这样更加"Lettuce"。
@Autowired
private LettuceConnectionFactory leconnFactory;
try (RedisConnection conn = leconnFactory.getConnection()) {
conn.set("hehe".getBytes(), "haha".getBytes());
}
至此,我们已经完成了Spring Boot 与 Redis的集成。
思考题:当一个微服务需要连接多组Redis,该如何集成呢?
请自己探索,并验证其正确性。
微服务开发中篇:微服务的注册与发现、配置中心、消息队列、稳定性
你可能留意到,在"微服务上篇"的讨论中,我们介绍的RPC、数据库等内容,都局限于单机环境,并没有真正涉及“分布式”。
在本章,我们将"真正的"进入分布式的微服务实战开发。
在微服务的架构下,经过服务的拆分,会形成复杂的服务调用关系,例如A调用B,B调用C....调用Z。同时,出于性能考虑,每一个服务X可能由若干个实例组成。如此庞大的实例数量,如果依靠手工配置来管理,是一个不可能完成的任务。为此,我们需要引入微服务的注册中心。
我们将基于Nacos来实现服务的注册与发现:Nacos的基本用法、服务端的自动注册,客户端的自动发现、装配。
Nacos不仅是服务管理平台,也提供了配置管理的功能,我们将基于此实现微服务的配置中心。
消息队列是应用接耦、流量消峰的利器,我们将介绍Rocket MQ的基础概念,并将其集成进开发框架中。
保证微服务的稳定性有三大法宝:“熔断、限流、降级”。在本章的最后,我们将引入轻量但强大的resilience4j,为微服务保驾护航。
Nacos注册中心:注册篇

这是一张从互联网上找到的图,你的直观感受是什么?头皮发麻?
实际上,这个球儿是某一年亚马逊的微服务结构图,每一个球的端点,都是一个微服务。
假设某个微服务A,想通过RPC调用另一个微服务B,需要如何实现呢?
-
微服务B可能有多个实例,他需要先找到一个存活的实例,假设叫做B1。
-
需要知道B1的IP和端口
-
建立连接,发起请求,并响应结果。
仔细揣摩上述流程,你会有一些疑问:
-
怎么知道B的哪个实例还在存活?
-
怎么知道B1的具体IP和端口?
-
假设微服务B扩容后,有一个新的B6,如何上服务A感知到呢?
这些都是微服务注册中心要解决的问题。
Nacos服务注册中心
Nacos 致力于帮助您发现、配置和管理微服务。它提供了一组简单易用的特性集,帮助应用快速实现动态服务发现、服务配置、服务元数据及流量管理。
为了演示基本原理,我们将采用单机模式,在实际生产环境中,建议你采用集群部署。
#!/bin/bash
NAME="nacos"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-e MODE=standalone \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--detach \
--restart always \
nacos/nacos-server:2.0.3
如上,我们采用官方镜像的单机模式,端口介绍如下:
-
8848是web界面和rest api端口
-
9848、9849是gRPC端口
启动成功后,访问http://127.0.0.1:8848,会进入如下界面:
默认的用户名和密码都是nacos。
服务端集成Nacos自动注册
接下来,我们实现微服务的自动注册,即服务启动时,将自身的IP和端口,主动注册到Nacos上。
由于我们的架构体系中,通过gRPC进行服务通信,因此我们只注册RPC的部分。我们沿用第2章中的设定,端口是5000。
在服务端集成Nacos有很多方法,一般常见的都是直接使用spring-cloud-starter,但本书并没有采用这种做法,原因是:
-
需要引入大量额外的cloud包,导致技术依赖过于旁杂。
-
cloud模式采用注解的方式,并不能很好支持"一个微服务与多个不同微服务通信"的场景。
综上我们直接使用裸客户端的方式,首先是依赖:
implementation 'com.alibaba.nacos:nacos-client:2.0.3'
接着,我们在第2章的基础上,在RPC服务上做如下修改:
@Configuration
public class RpcServerConfiguration {
private Logger LOG = LoggerFactory.getLogger(RpcServerConfiguration.class);
@Autowired
private BindableService bindableService;
@Autowired
private HomsRpcServer server;
@Autowired
private NacosService nacosService;
@Bean
public HomsRpcServer createRpcServer() {
return new HomsRpcServer(bindableService, 5000);
}
@PostConstruct
public void postConstruct() throws IOException, NacosException {
server.start();
// register
nacosService.registerRPC(SERVICE_NAME);
}
@PreDestroy
public void preDestory() throws NacosException {
try {
server.stop();
} catch (InterruptedException e) {
LOG.info("stop gRPC server exception", e);
} finally {
// unregister
nacosService.deregisterRPC(SERVICE_NAME);
LOG.info("stop gRPC server done");
}
}
}
如上所示,我们在RPC服务启动的时候,增加了向Nacos的注册、在RPC停止的时候,在Nacos上注销服务。
NacosService是对NacosClient的简单封装,代码如下:
@Service
public class NacosServiceImpl implements NacosService {
@Value("${nacos.server}")
private String nacosServer;
private NamingService namingService;
@PostConstruct
public void postConstruct() throws NacosException {
namingService = NamingFactory
.createNamingService(nacosServer);
}
@Override
public void registerRPC(String serviceName) throws NacosException {
namingService.registerInstance(serviceName, getIP(), 5000);
}
@Override
public void deregisterRPC(String serviceName) throws NacosException {
namingService.deregisterInstance(serviceName, getIP(), 5000);
}
private String getIP() {
return System.getProperty("POD_IP", "127.0.0.1");
}
}
如上所示,我们从yaml中读取Nacos服务的地址,然后从环境变量读取IP地址,并实现了注册、注销功能。
这里,你可以暂时假定环境变量一定可以取到IP,在后续Kubernetes的章节,我们会介绍如何将Pod的IP注入容器的环境变量。
你可以试着启动服务,然后访问Nacos的Web UI,会发现我们的服务正常发现了!
至此,我们实现了服务端的服务注册。至于另一半,服务的发现,请听下回分解!
Nacos注册中心:发现篇
经过上一节的努力,我们已经将RPC服务成功的注册到Nacos上了。
我们还是以老生常谈的A调用B为例,B的所有实例B1、B2...都在Nacos上了。我们本节要实现的,都客户端,也就是A的部分。
老规矩,先引入依赖:
implementation 'com.alibaba.nacos:nacos-client:2.0.3'
implementation 'org.springframework.boot:spring-boot-autoconfigure:2.2.0.RELEASE'
上述除了引入nacos的依赖外,还引入了spring-boot的自动配置包,后续做客户端的自动装配时会用到。
客户端改造
在正式对接Nacos前,我们先对客户端的包做一些改造。
首先,引入一个通用的Grpc客户端实现:
public abstract class HSGrpcClient implements AutoCloseable {
private ManagedChannel channel;
private String ip;
private int port;
public HSGrpcClient(String ip, int port) {
this.ip = ip;
this.port = port;
}
public void init() {
channel = ManagedChannelBuilder
.forTarget(ip + ":" + port)
.usePlaintext()
.build();
initSub(channel);
}
protected abstract void initSub(Channel channel);
public void close() throws InterruptedException {
channel.shutdownNow().awaitTermination(5, TimeUnit.SECONDS);
}
}
代码如上所示:
-
HSGrpcClient管理了ManagedChannel,这是用于实际网络通信的连接池。
-
提供了initStub抽象方法,让子类根据自己的需求,去初始化自己的stub。
-
实现了AutoCloseable接口,让客户端可以通过close方法自动关闭。
在这个基础上,我们改造之前的具体RPC客户端,如下:
public class HomsDemoGrpcClient extends HSGrpcClient {
private Logger LOG = LoggerFactory.getLogger(HomsDemoGrpcClient.class);
private HomsDemoGrpc.HomsDemoFutureStub futureStub;
/**
* Construct client for accessing HelloWorld server using the existing channel.
*/
public HomsDemoGrpcClient(String ip, int port) {
super(ip, port);
}
@Override
protected void initSub(Channel channel) {
futureStub = HomsDemoGrpc.newFutureStub(channel);
}
public Optional<Integer> add(int val1, int val2) {
AddRequest request = AddRequest.newBuilder().setVal1(val1).setVal2(val2).build();
try {
AddResponse response = futureStub.add(request).get();
return Optional.ofNullable(response.getVal());
} catch (Exception e) {
LOG.error("grpc add exception", e);
return Optional.empty();
}
}
}
如上,我们改用了FutureStub,并且将Manage的管理部分,移到了基类中。
SimpleGrpcClientManager的实现
在正式引入Nacos之前,我们先实现一个“看起来没什么营养”的SimpleGrpcClientManager,它可以提供IP、Port直连的客户端管理。
首先是基类:
public abstract class AbstractGrpcClientManager<T extends HSGrpcClient> {
protected Logger LOG = LoggerFactory.getLogger(getClass());
protected volatile CopyOnWriteArrayList<T> clientPools = new CopyOnWriteArrayList<>();
protected Class<T> kind;
public AbstractGrpcClientManager(Class<T> kind) {
this.kind = kind;
}
public Optional<T> getClient() {
if (clientPools.size() == 0) {
return Optional.empty();
}
int pos = ThreadLocalRandom.current().nextInt(clientPools.size());
return Optional.ofNullable(clientPools.get(pos));
}
public abstract void init() throws Exception;
public void shutdown() {
clientPools.forEach(c -> {
try {
shutdown(c);
} catch (InterruptedException e) {
LOG.error("shutdown client exception", e);
}
});
}
protected void shutdown(HSGrpcClient client) throws InterruptedException {
client.close();
}
protected Optional<HSGrpcClient> buildHsGrpcClient(String ip, int port) {
try {
Class[] cArg = {String.class, int.class};
HSGrpcClient client = kind.getDeclaredConstructor(cArg)
.newInstance(ip, port);
client.init();
return Optional.ofNullable(client);
} catch (Exception e) {
LOG.error("build MyGrpcClient exception, ip = "+ ip + " port = "+ port, e);
return Optional.empty();
}
}
}
代码如上,解释一下:
- clientPools是一组HSGrpcClient对象,即支持同时与多个微服务实例(多组不同的ip和端口)建立连接。在微服务场景下,这一特性尤为重要。
- 而从每一个HSGrpcClient的视角来看,其内置的ManagedChannel内部实现了连接池。因此针对同一个微服务的ip和端口,我们只需要一个HSGrpcClient的实例即可。
下面,我们看一下基础的、不带服务发现的实现:
package com.coder4.homs.demo.client;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* @author coder4
*/
public class SimpleGrpcClientManager<T extends HSGrpcClient> extends AbstractGrpcClientManager<T> {
protected Logger LOG = LoggerFactory.getLogger(SimpleGrpcClientManager.class);
private String ip;
private int port;
public SimpleGrpcClientManager(Class<T> kind, String ip, int port) {
super(kind);
this.ip = ip;
this.port = port;
}
public void init() {
// init one client only
HSGrpcClient client = buildHsGrpcClient(ip, port)
.orElseThrow(() -> new RuntimeException("build HsGrpcClient fail"));
clientPools = new CopyOnWriteArrayList(Arrays.asList(client));
}
public static void main(String[] args) throws Exception {
SimpleGrpcClientManager<HomsDemoGrpcClient> manager = new SimpleGrpcClientManager(HomsDemoGrpcClient.class, "127.0.0.1", 5000);
manager.init();
manager.getClient().ifPresent(t -> System.out.println(t.add(1, 2)));
manager.shutdown();
}
}
从上述实现中不难发现:
-
该实现中,默认只与预先设定的IP和端口,构造一个单独的HSGrpcClient。
-
由于IP和端口通过外部指定,因此使用了CopyOnWriteArrayList以保证线程安全。
NacosGrpcClientManager的实现
下面,我们着手实现带Nacos服务发现的版本。
package com.coder4.homs.demo.client;
import com.alibaba.nacos.api.naming.NamingFactory;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.listener.NamingEvent;
import com.alibaba.nacos.api.naming.pojo.Instance;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* @author coder4
*/
public class NacosGrpcClientManager<T extends HSGrpcClient> extends AbstractGrpcClientManager<T> {
protected String serviceName;
protected String nacosServer;
protected NamingService namingService;
public NacosGrpcClientManager(Class<T> kind, String nacosServer, String serviceName) {
super(kind);
this.nacosServer = nacosServer;
this.serviceName = serviceName;
}
@Override
public void init() throws Exception {
namingService = NamingFactory
.createNamingService(nacosServer);
namingService.subscribe(serviceName, e -> {
if (e instanceof NamingEvent) {
NamingEvent event = (NamingEvent) e;
rebuildClientPools(event.getInstances());
}
});
rebuildClientPools(namingService.selectInstances(serviceName, true));
}
private void rebuildClientPools(List<Instance> instanceList) {
ArrayList<HSGrpcClient> list = new ArrayList<>();
for (Instance instance : instanceList) {
buildHsGrpcClient(instance.getIp(), instance.getPort()).ifPresent(c -> list.add(c));
}
CopyOnWriteArrayList<T> oldClientPools = clientPools;
clientPools = new CopyOnWriteArrayList(list);
// destory old ones
oldClientPools.forEach(c -> {
try {
c.close();
} catch (InterruptedException e) {
LOG.error("MyGrpcClient shutdown exception", e);
}
});
}
}
解释如下:
-
在init方法中,初始化了NamingService,并订阅对应serviceName服务的更新事件。
-
当第一次,或者有服务更新时,我们会根据最新列表,重建所有的HSGrpcClient
-
每次重建后,关闭老的HSGrpcClient
为了让上述客户端使用更加方便,我们添加了如下的自动配置:
@Configuration
public class HomsDemoGrpcClientManagerConfiguration {
@Bean(name = "homsDemoGrpcClientManager")
@ConditionalOnMissingBean(name = "homsDemoGrpcClientManager")
@ConditionalOnProperty(name = {"nacos.server"})
public AbstractGrpcClientManager<HomsDemoGrpcClient> nacosManager(
@Value("${nacos.server}") String nacosServer) throws Exception {
NacosGrpcClientManager<HomsDemoGrpcClient> manager =
new NacosGrpcClientManager<>(HomsDemoGrpcClient.class,
nacosServer, HomsDemoConstant.SERVICE_NAME);
manager.init();
return manager;
}
}
如上所示:
-
nacos的server地址由yaml中配置
-
serviceName由client包中的常量文件HomsDemoConstant提供(即homs-demo)
为了让上述自动配置自动生效,我们还需要添加META-INF/spring.factories文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.coder4.homs.demo.configuration.HomsDemoGrpcClientManagerConfiguration
最后,我们来实验一下服务发现的效果
-
启动Server进程,检查Nacos上,应当出现了自动注册的RPC服务。
-
开发客户端驱动的项目,引用上述client包、配置yaml中的nacos服务地址
-
最后,在客户端驱动项目中,通过Autowired自动装配,代码类似:
@Autowired
private AbstractGrpcClientManager<HomsDemoGrpcClient> homsClientManager;
// Usage
homsClientManager.getClient().ifPresent(client -> client.add(1, 2));
如果一切顺利,会自动发现nacos上已经注册的服务实例,并成功执行rpc调用。
Spring Boot集成配置中心
Nacos不仅提供了服务的注册与发现,也提供了配置管理的功能。
本节,我们继续使用Nacos,基于其配置管理的功能,实现微服务的配置中心。
首先,我们在Nacos上,新建两个配置:
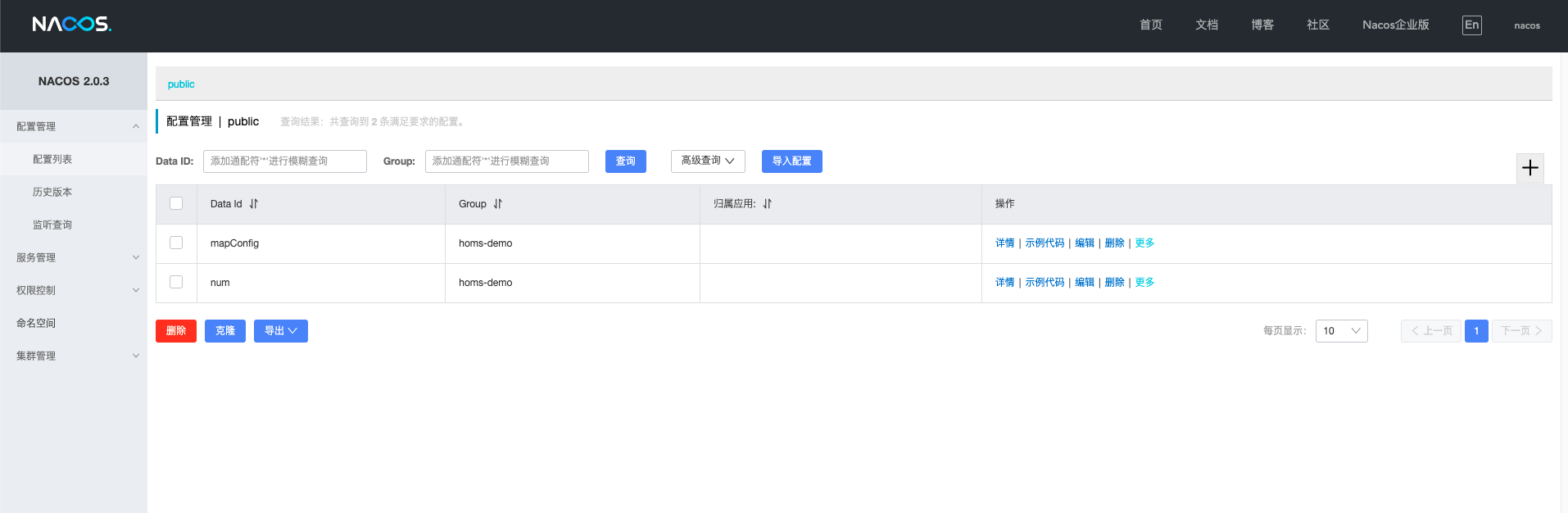
如上图所示:
-
Nacos提供了dataId、group两个字段,用于区分不同的配置
-
我们在group字段填充微服务的名称,例如homs-demo
-
我们在dataId字段填写配置的key
-
Nacos的支持简单的类型检验,例如json、数值、字符串等,但只限于前端校验,存储后多统一为字符串类型
有了配置后,我们来实现Nacos配置管理的驱动部分:
public interface NacosConfigService {
Optional<String> getConfig(String serviceName, String key);
void onChange(String serviceName, String key, Consumer<Optional<String>> consumer);
}
package com.coder4.homs.demo.server.service.impl;
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.config.listener.Listener;
import com.alibaba.nacos.api.exception.NacosException;
import com.coder4.homs.demo.server.service.spi.NacosConfigService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.Optional;
import java.util.concurrent.Executor;
import java.util.function.Consumer;
/**
* @author coder4
*/
@Service
public class NacosConfigServiceImpl implements NacosConfigService{
private static final Logger LOG = LoggerFactory.getLogger(NacosConfigServiceImpl.class);
@Value("${nacos.server}")
private String nacosServer;
private ConfigService configService;
@PostConstruct
public void postConstruct() throws NacosException {
configService = NacosFactory
.createConfigService(nacosServer);
}
@Override
public Optional<String> getConfig(String serviceName, String key) {
try {
return Optional.ofNullable(configService.getConfig(key, serviceName, 5000));
} catch (NacosException e) {
LOG.error("nacos get config exception for " + serviceName + " " + key, e);
return Optional.empty();
}
}
@Override
public void onChange(String serviceName, String key, Consumer<Optional<String>> consumer) {
try {
configService.addListener(key, serviceName, new Listener() {
@Override
public Executor getExecutor() {
return null;
}
@Override
public void receiveConfigInfo(String configInfo) {
consumer.accept(Optional.ofNullable(configInfo));
}
});
} catch (NacosException e) {
LOG.error("nacos add listener exception for " + serviceName + " " + key, e);
throw new RuntimeException(e);
}
}
}
上述驱动部分,主要实现了两个功能:
-
通过getConfig方法,同步拉取配置
-
通过onChange方法,添加异步监听器,当配置发生改变时,会执行回调
配置的自动注解与更新
我们希望实现一个更加“易用”的配置中心,期望具有如下特性:
-
通过注解的方式,自动将类中的字段"绑定"到远程Nacos配置中心对应字段上,并自动初始化。
-
当Nacos配置更新后,本地同步进行修改。
-
支持类型的自动转换
第一步,我们声明注解:
package com.coder4.homs.demo.server.annotation;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({ElementType.FIELD, ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface HSConfig {
String name() default "";
String serviceName() default "";
}
上述关键字段的用途是:
-
name,远程fdc指定的配置名称,可选,若未填写则使用注解应用的原始字段名。
-
serviceName,远程fdc指定的服务名称,可选,若未填写则使用当前本地服务名。
接着,我们借助BeanPostProcessor,来对打了HSConfig注解的字段,进行值注入。
package com.coder4.homs.demo.server.processor;
import com.alibaba.nacos.common.utils.StringUtils;
import com.coder4.homs.demo.server.HsReflectionUtils;
import com.coder4.homs.demo.server.annotation.HSConfig;
import com.coder4.homs.demo.server.service.spi.NacosConfigService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.aop.support.AopUtils;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
import org.springframework.core.Ordered;
import org.springframework.data.util.ReflectionUtils.AnnotationFieldFilter;
import org.springframework.util.ReflectionUtils;
import org.springframework.util.ReflectionUtils.FieldFilter;
import java.lang.reflect.Field;
import java.util.Optional;
/**
* @author coder4
*/
public class HsConfigFieldProcessor implements BeanPostProcessor, Ordered {
private static final Logger LOG = LoggerFactory.getLogger(HsConfigFieldProcessor.class);
private static final FieldFilter HS_CONFIG_FIELD_FILTER = new AnnotationFieldFilter(HSConfig.class);
private NacosConfigService nacosConfigService;
private String serviceName;
public HsConfigFieldProcessor(NacosConfigService service, String serviceName) {
this.nacosConfigService = service;
this.serviceName = serviceName;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
Class targetClass = AopUtils.getTargetClass(bean);
ReflectionUtils.doWithFields(
targetClass, field -> processField(bean, field), HS_CONFIG_FIELD_FILTER);
return bean;
}
private void processField(Object bean, Field field) {
HSConfig valueAnnotation = field.getDeclaredAnnotation(HSConfig.class);
// 优先注解,其次本地代码
String key = StringUtils.defaultIfEmpty(valueAnnotation.name(), field.getName());
String serviceName = StringUtils.defaultIfEmpty(valueAnnotation.serviceName(), this.serviceName);
Optional<String> valueOp = nacosConfigService.getConfig(serviceName, key);
try {
if (!valueOp.isPresent()) {
LOG.error("nacos config for serviceName = {} key = {} is empty", serviceName, key);
}
HsReflectionUtils.setField(bean, field, valueOp.get());
// Future Change
nacosConfigService.onChange(serviceName, key, valueOp2 -> {
try {
HsReflectionUtils.setField(bean, field, valueOp2.get());
} catch (IllegalAccessException e) {
LOG.error("nacos config for serviceName = {} key = {} exception", e);
}
});
} catch (IllegalAccessException e) {
LOG.error("setField for " + field.getName() + " exception", e);
throw new RuntimeException(e.getMessage());
}
}
@Override
public int getOrder() {
return LOWEST_PRECEDENCE;
}
}
上述代码比较复杂,我们逐步讲解:
-
构造函数传入nacosConfigService用于操作nacos配置管理接口
-
构造函数传入的serviceName做为默认的服务名
-
postProcessBeforeInitialization方法,会在Bean构造前执行,通过ReflectionUtils来过滤所有打了@HsConfig注解的字段,逐一处理,流程如下:
-
首先获取要绑定的服务名、字段名,遵循注解优于本地的顺序
-
调用nacosServer拉取当前配置,并通过HsReflectionUtils工具的反射的注入到字段中。
-
添加回调,以便未来更新时,及时修改本地变量。
-
HsReflectionUtils中涉及类型的自动转换,代码如下:
package com.coder4.homs.demo.server.utils;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.lang.reflect.Field;
/**
* @author coder4
*/
public class HsReflectionUtils {
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
public static void setField(Object bean, Field field, String valueStr) throws IllegalAccessException {
field.setAccessible(true);
Class fieldType = field.getType();
if (fieldType == Integer.TYPE || fieldType == Integer.class) {
field.set(bean, Integer.parseInt(valueStr));
} else if (fieldType == Long.TYPE || fieldType == Long.class) {
field.set(bean, Long.parseLong(valueStr));
} else if (fieldType == Short.TYPE || fieldType == Short.class) {
field.set(bean, Short.parseShort(valueStr));
} else if (fieldType == Double.TYPE || fieldType == Double.class) {
field.set(bean, Double.parseDouble(valueStr));
} else if (fieldType == Float.TYPE || fieldType == Float.class) {
field.set(bean, Float.parseFloat(valueStr));
} else if (fieldType == Byte.TYPE || fieldType == Byte.class) {
field.set(bean, Byte.parseByte(valueStr));
} else if (fieldType == Boolean.TYPE || fieldType == Boolean.class) {
field.set(bean, Boolean.parseBoolean(valueStr));
} else if (fieldType == Character.TYPE || fieldType == Character.class) {
if (valueStr == null || valueStr.isEmpty()) {
throw new IllegalArgumentException("can't parse char because value string is empty");
}
field.set(bean, valueStr.charAt(0));
} else if (fieldType.isEnum()) {
field.set(bean, Enum.valueOf(fieldType, valueStr));
} else {
try {
field.set(bean, OBJECT_MAPPER.readValue(valueStr, fieldType));
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("can't parse json because exception");
}
}
}
}
上述代码中,针对field的类型逐一判断,针对八大基本类型,直接parse,针对复杂类型,使用json反序列化的方式注入。
自动配置的使用
有了上述的基础后,我们还需要添加自动配置类,让其生效:
package com.coder4.homs.demo.server.configuration;
import com.coder4.homs.demo.constant.HomsDemoConstant;
import com.coder4.homs.demo.server.processor.HsConfigFieldProcessor;
import com.coder4.homs.demo.server.service.spi.NacosConfigService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author coder4
*/
@Configuration
public class HsConfigProcessorConfiguration {
@Bean
@ConditionalOnMissingBean(HsConfigFieldProcessor.class)
public HsConfigFieldProcessor fieldProcessor(@Autowired NacosConfigService configService) {
return new HsConfigFieldProcessor(configService, HomsDemoConstant.SERVICE_NAME);
}
}
使用时非常简单:
@Service
public class HomsDemoConfig {
@HSConfig
private int num;
@HSConfig(name = "mapConfig")
private Map<String, String> map;
@PostConstruct
public void postConstruct() {
System.out.println(num);
System.out.println(map);
}
}
只需要添加HSConfig注解,即可完成远程配置的自动注入、绑定、更新。
Spring Boot集成熔断、限流、降级
在引入resilience4j之前,我们先来讨论下服务稳定性的三大法宝。
-
降级:在有限资源情况下,为了应对超负荷流量,适当放弃一些功能,以保证服务的整体稳定性。例如:双十一大促时,关闭个性化推荐。
-
限流:为了应对突发流量,只允许一部分请求通过,放弃其余请求。例如:当前服务忙,请稍后再试。
-
熔断:这个概念最早源于物理学。
-
在电路中,若电流过大,熔断器(保险丝 / 空气开关)会发生熔断,切断线路,以保证用电安全。
-
在微服务架构中,若服务调用发生大量错误(超时),可以直接将微服务降级,以保证服务的整体稳定性。
-
Resillence4j是一款轻量级、易用的"容错框架",提供了保证稳定性所需的几大基础组件:
-
Retry:重试
-
Circuit Breaker:基于Ring Buffer的熔断器,根据失败率/次数,自动切换熔断器的开关状态。
-
Rate Limiter:基于AtomicReference + 状态机 实现的限流器
-
Time Limiter:基于限时Future / CompletationStage的时限器
-
Bulk Head:基于信号量 / 线程池的壁仓隔离。
-
Cache / Fallback:为上述组件提供降级时的包装函数
Resillence4j支持Java、注解等多种使用方法,我们这里选用最方便的Spring Boot注解方法。
Circuit Breaker
首先来看一下熔断器,它内置了如下三种状态:
-
CLOSE:初始状态,熔断器关闭,服务正常运行。
-
OPEN:发生大量错误后,熔断器打开,直接返回降级结果,不再调用真实服务逻辑。
-
HALF OPEN:OPEN一段时间后,小流量放开访问,看真实逻辑部分是否恢复正常。如果恢复,会切换到CLOSE状态。
老规矩,先添加依赖:
implementation 'io.github.resilience4j:resilience4j-all:1.7.1'
implementation 'io.github.resilience4j:resilience4j-spring-boot2:1.7.1'
说明如下:
-
由于后续几个组件都会使用,我们这里直接使用了all,你可以根据实际情况,裁剪需要的组件。
-
spring-boot:添加了对应的注解和自动配置。
熔断器的配置如下:
resilience4j:
circuitbreaker:
instances:
getUserById:
registerHealthIndicator: true
slidingWindowSize: 100
failureRateThreshold: 50
说明如下:
-
熔断器名称是getUserById
-
滑动窗口大小100
-
失败(熔断)阀值是50%
代码用法如下:
@Override
@CircuitBreaker(name = "getUser", fallbackMethod = "getUserByIdFallback")
public Optional<User> getUserById(long id) {
// Mock a failure
if (ThreadLocalRandom.current().nextInt(100) < 90) {
throw new RuntimeException("mock failure");
}
return userRepository.getUser(id);
}
public Optional<User> getUserByIdFallback(long id, Throwable e) {
LOG.error("enter fallback for getUserById", e);
return Optional.empty();
}
在上述代码中,我们以90%的概率模拟了随机异常。
当熔断发生时,会使用getUserByIdFallback中的降级结果。
执行几次后,会出现类似如下的错误日志,熔断器已成功开启。
2021-10-09 01:34:32.156 ERROR 2214 --- [o-8080-exec-144] c.c.h.d.s.service.impl.UserServiceImpl : enter fallback for getUserById
io.github.resilience4j.circuitbreaker.CallNotPermittedException: CircuitBreaker 'getUser' is OPEN and does not permit further calls
at io.github.resilience4j.circuitbreaker.CallNotPermittedException.createCallNotPermittedException(CallNotPermittedException.java:48) ~[resilience4j-circuitbreaker-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.internal.CircuitBreakerStateMachine$OpenState.acquirePermission(CircuitBreakerStateMachine.java:696) ~[resilience4j-circuitbreaker-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.internal.CircuitBreakerStateMachine.acquirePermission(CircuitBreakerStateMachine.java:206) ~[resilience4j-circuitbreaker-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.CircuitBreaker.lambda$decorateCheckedSupplier$82a9021a$1(CircuitBreaker.java:70) ~[resilience4j-circuitbreaker-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.CircuitBreaker.executeCheckedSupplier(CircuitBreaker.java:834) ~[resilience4j-circuitbreaker-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.configure.CircuitBreakerAspect.defaultHandling(CircuitBreakerAspect.java:188) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.configure.CircuitBreakerAspect.proceed(CircuitBreakerAspect.java:135) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.configure.CircuitBreakerAspect.lambda$circuitBreakerAroundAdvice$6edadc33$1(CircuitBreakerAspect.java:118) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.fallback.DefaultFallbackDecorator.lambda$decorate$52452fd9$1(DefaultFallbackDecorator.java:36) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.circuitbreaker.configure.CircuitBreakerAspect.circuitBreakerAroundAdvice(CircuitBreakerAspect.java:118) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at sun.reflect.GeneratedMethodAccessor127.invoke(Unknown Source) ~[na:na]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_291]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_291]
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:634) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:624) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:72) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:175) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:750) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:97) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:750) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:692) [spring-aop-5.3.9.jar:5.3.9]
at com.coder4.homs.demo.server.service.impl.UserServiceImpl$$EnhancerBySpringCGLIB$$19b58f1b.getUserById(<generated>) [main/:na]
at com.coder4.homs.demo.server.web.logic.impl.UserLogicImpl.getUserById(UserLogicImpl.java:51) [main/:na]
at com.coder4.homs.demo.server.web.ctrl.UserController.getById(UserController.java:36) [main/:na]
at sun.reflect.GeneratedMethodAccessor113.invoke(Unknown Source) ~[na:na]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_291]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_291]
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:197) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:141) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:106) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:895) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:808) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1064) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:963) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:898) [spring-webmvc-5.3.9.jar:5.3.9]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:655) [tomcat-embed-core-9.0.50.jar:4.0.FR]
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883) [spring-webmvc-5.3.9.jar:5.3.9]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:764) [tomcat-embed-core-9.0.50.jar:4.0.FR]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:228) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) [tomcat-embed-websocket-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal(WebMvcMetricsFilter.java:96) [spring-boot-actuator-2.5.3.jar:2.5.3]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:382) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1723) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) [tomcat-embed-core-9.0.50.jar:9.0.50]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [na:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [na:1.8.0_291]
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) [tomcat-embed-core-9.0.50.jar:9.0.50]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_291]
Bulkhead & TimeLimiter
下面我们来看一下实线器,即限定必须在X时间内执行完毕,否则抛出异常。
Resillence4j的TimeLimiter设计中,并没有内置线程池,而是要业务代码自行处理。我们可以结合Bulkhead的线程池模式一同使用,首先配置如下:
resilience4j:
thread-pool-bulkhead:
instances:
getUserByName:
maxThreadPoolSize: 100
coreThreadPoolSize: 50
queueCapacity: 200
timelimiter:
instances:
getUserByName:
timeoutDuration: 1s
cancelRunningFuture: true
如上所述,我们配置了线程池,并设置时限为1秒。
接着看一下用法:
@Override
@Bulkhead(name = "getUserByName", type = Type.THREADPOOL)
@TimeLimiter(name = "getUserByName", fallbackMethod = "getUserByNameWithCompletableFutureFallback")
public CompletableFuture<Optional<User>> getUserByNameWithCompletableFuture(String name) {
// Mock timeout
Try.run(() -> Thread.sleep(ThreadLocalRandom.current().nextInt(2000)));
return CompletableFuture.completedFuture(userRepository.getUserByName(name));
}
public CompletableFuture<Optional<User>> getUserByNameWithCompletableFutureFallback(String name, Throwable e) {
LOG.error("enter fallback for getUserByNameFallback", e);
return CompletableFuture.completedFuture(Optional.empty());
}
我们模拟了随机超时时间,当超过1秒时,会自动抛出如下的降级异常,并走降级逻辑。
2021-10-09 01:53:32.637 ERROR 4890 --- [pool-7-thread-1] c.c.h.d.s.service.impl.UserServiceImpl : enter fallback for getUserByNameFallback
java.util.concurrent.TimeoutException: TimeLimiter 'getUserByName' recorded a timeout exception.
at io.github.resilience4j.timelimiter.TimeLimiter.createdTimeoutExceptionWithName(TimeLimiter.java:221) ~[resilience4j-timelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.timelimiter.internal.TimeLimiterImpl$Timeout.lambda$of$0(TimeLimiterImpl.java:185) ~[resilience4j-timelimiter-1.7.1.jar:1.7.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[na:1.8.0_291]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [na:1.8.0_291]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) [na:1.8.0_291]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) [na:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [na:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [na:1.8.0_291]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_291]
RateLimiter
最后我们来看一下限流器,配置如下:
resilience4j:
rateLimiter:
instances:
getUserByIdV2:
limitForPeriod: 1
limitRefreshPeriod: 500ms
timeoutDuration: 0
设置了每0.5秒限1个请求,用法如下:
@Override
@RateLimiter(name = "getUserByIdV2", fallbackMethod = "getUserByIdV2Fallback")
public Optional<User> getUserByIdV2(long id) {
return Optional.ofNullable(userMapper.getUser(id)).map(UserDO::toUser);
}
public Optional<User> getUserByIdV2Fallback(long id, Throwable e) {
LOG.error("getUserByIdV2 fallback exception", e);
return Optional.empty();
}
当快速访问两次接口后,会抛出如下的异常,并返回降级结果。
2021-10-09 14:00:13.564 ERROR 5598 --- [nio-8080-exec-8] c.c.h.d.s.service.impl.UserServiceImpl : getUserByIdV2 fallback exception
io.github.resilience4j.ratelimiter.RequestNotPermitted: RateLimiter 'getUserByIdV2' does not permit further calls
at io.github.resilience4j.ratelimiter.RequestNotPermitted.createRequestNotPermitted(RequestNotPermitted.java:43) ~[resilience4j-ratelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.RateLimiter.waitForPermission(RateLimiter.java:591) ~[resilience4j-ratelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.RateLimiter.lambda$decorateCheckedSupplier$9076412b$1(RateLimiter.java:213) ~[resilience4j-ratelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.RateLimiter.executeCheckedSupplier(RateLimiter.java:898) ~[resilience4j-ratelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.RateLimiter.executeCheckedSupplier(RateLimiter.java:884) ~[resilience4j-ratelimiter-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.configure.RateLimiterAspect.handleJoinPoint(RateLimiterAspect.java:179) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.configure.RateLimiterAspect.proceed(RateLimiterAspect.java:142) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.configure.RateLimiterAspect.lambda$rateLimiterAroundAdvice$749d37c4$1(RateLimiterAspect.java:125) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.fallback.DefaultFallbackDecorator.lambda$decorate$52452fd9$1(DefaultFallbackDecorator.java:36) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at io.github.resilience4j.ratelimiter.configure.RateLimiterAspect.rateLimiterAroundAdvice(RateLimiterAspect.java:125) ~[resilience4j-spring-1.7.1.jar:1.7.1]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_291]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_291]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_291]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_291]
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethodWithGivenArgs(AbstractAspectJAdvice.java:634) ~[spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.aspectj.AbstractAspectJAdvice.invokeAdviceMethod(AbstractAspectJAdvice.java:624) ~[spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.aspectj.AspectJAroundAdvice.invoke(AspectJAroundAdvice.java:72) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:175) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:750) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:97) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$CglibMethodInvocation.proceed(CglibAopProxy.java:750) [spring-aop-5.3.9.jar:5.3.9]
at org.springframework.aop.framework.CglibAopProxy$DynamicAdvisedInterceptor.intercept(CglibAopProxy.java:692) [spring-aop-5.3.9.jar:5.3.9]
at com.coder4.homs.demo.server.service.impl.UserServiceImpl$$EnhancerBySpringCGLIB$$cba2db53.getUserByIdV2(<generated>) [main/:na]
at com.coder4.homs.demo.server.web.logic.impl.UserLogicImpl.getUserByIdV2(UserLogicImpl.java:80) [main/:na]
at com.coder4.homs.demo.server.web.ctrl.UserController.getByIdV2(UserController.java:51) [main/:na]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_291]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_291]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_291]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_291]
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:197) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:141) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:106) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:895) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:808) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1064) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:963) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) [spring-webmvc-5.3.9.jar:5.3.9]
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:898) [spring-webmvc-5.3.9.jar:5.3.9]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:655) [tomcat-embed-core-9.0.50.jar:4.0.FR]
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883) [spring-webmvc-5.3.9.jar:5.3.9]
at javax.servlet.http.HttpServlet.service(HttpServlet.java:764) [tomcat-embed-core-9.0.50.jar:4.0.FR]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:228) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) [tomcat-embed-websocket-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal(WebMvcMetricsFilter.java:96) [spring-boot-actuator-2.5.3.jar:2.5.3]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201) [spring-web-5.3.9.jar:5.3.9]
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119) [spring-web-5.3.9.jar:5.3.9]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:190) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:163) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:382) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1723) [tomcat-embed-core-9.0.50.jar:9.0.50]
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) [tomcat-embed-core-9.0.50.jar:9.0.50]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [na:1.8.0_291]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [na:1.8.0_291]
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) [tomcat-embed-core-9.0.50.jar:9.0.50]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_291]
至此,我们已经熟悉了Resillence4j中的主要组件,并覆盖了yaml中的常见的配置。
更多配置选项,可以参考这篇文档。
由于篇幅限制,本文并未涉及Retry、Cache两大组件,推荐你阅读官方文档自行探索。
Spring Boot集成消息队列
Apache RocketMQ是由开源的轻量级消息队列,于2017年正式成为Apache顶级项目。
在分布式消息队列中间件领域,最热门的项目是Kafka和RocketMQ:
-
Kafka是较早开源的"消息处理平台",在写吞吐量上,有明显优势,更适合处理日志类消息。
-
RocketMQ借鉴了部分Kafka的设计思路,并对实时性、大分区数等方面进行了优化,较适合做为业务类的消息。
因此,本书选用RocketMQ做为业务类的消息队列。
安装并运行RocketMQ
RocketMQ的容器化比较落后,基本没有可用的镜像版本,我们采用手工单机部署的方式。
首先,下载最新版二进制文件,当前是4.9.1:
wget https://dlcdn.apache.org/rocketmq/4.9.1/rocketmq-all-4.9.1-bin-release.zip
完成后,解压缩:
unizp rocketmq-all-4.9.1-bin-release.zip
启动Name Server:
nohup sh bin/mqnamesrv &
tail -f ~/logs/rocketmqlogs/namesrv.log
最后启动Broker:
nohup sh bin/mqbroker -n 127.0.0.1:9876 &
tail -f ~/logs/rocketmqlogs/broker.log
如果启动成功,在上述两个日志中,会有如下的日志:
2021-10-12 4:30:02 INFO main - tls.client.keyPassword = null
2021-10-12 4:30:02 INFO main - tls.client.certPath = null
2021-10-12 4:30:02 INFO main - tls.client.authServer = false
2021-10-12 4:30:02 INFO main - tls.client.trustCertPath = null
2021-10-12 4:30:02 INFO main - Using JDK SSL provider
2021-10-12 4:30:03 INFO main - SSLContext created for server
2021-10-12 4:30:03 INFO main - Try to start service thread:FileWatchService started:false lastThread:null
2021-10-12 4:30:03 INFO NettyEventExecutor - NettyEventExecutor service started
2021-10-12 4:30:03 INFO FileWatchService - FileWatchService service started
2021-10-12 4:30:03 INFO main - The Name Server boot success. serializeType=JSON
2021-10-12 14:36:09 INFO brokerOutApi_thread_3 - register broker[0]to name server 127.0.0.1:9876 OK
2021-10-12 14:36:09 ERROR DiskCheckScheduledThread1 - Error when measuring disk space usage, file doesn't exist on this path: /Users/coder4/store/commitlog
2021-10-12 14:36:18 ERROR StoreScheduledThread1 - Error when measuring disk space usage, file doesn't exist on this path: /Users/coder4/store/commitlog
2021-10-12 14:36:19 ERROR DiskCheckScheduledThread1 - Error when measuring disk space usage, file doesn't exist on this path: /Users/coder4/store/commitlog
可以发现,NameServer是没有问题的,Broker报了一个"Error when measuring disk space usage"的错,这个是当前版本的Bug,不影响使用。
如果想退出服务,可以直接kill,或者执行:
sh bin/mqshutdown broker
sh bin/mqshutdown namesrv
RocketMQ架构简介
在集成RocketMQ之前,先介绍一下RocketMQ的基本架构:
-
NameServer:轻量级元信息服务,管理路由信息并提供对应的读写服务
-
Broker:支撑TOPIC和QUEUE的存储,支持Push和Pull两种协议,有容错、副本、故障恢复机制。
-
Producer:发布端服务,支持分布式部署,并向Broker集群发送
-
Consumer:消费端服务,同时支持Push和Pull协议。支持消费、广播、顺序消息等特性。
-
Topic:队列,用于区分不同消息。
-
Tag:同一个Topic下,可以设定不同Tag(例如前缀),通过Tag来过滤消息,只保留自己感兴趣的。
在使用Producer和Consumer时,需要指定消费组(Consumer Group),这是从Kafka中借鉴过来的机制。相同Consumer Group下的实例会共享同一个GroupId,会被认为是对等的、可负载均衡的。事件会随机分发给相同GroupId下的多个实例中。
在Spring Boot中集成RocketMQ
首先引入依赖:
implementation 'org.apache.rocketmq:rocketmq-client:4.9.1'
接着,我们创建生产者的抽象基类:
package com.coder4.homs.demo.server.mq;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendCallback;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import javax.annotation.PostConstruct;
import java.nio.charset.StandardCharsets;
/**
* @author coder4
*/
public abstract class BaseProducer<T> implements DisposableBean {
private final Logger LOG = LoggerFactory.getLogger(getClass());
abstract String getNamesrvAddr();
abstract String getProducerGroup();
abstract String getTopic();
abstract String getTag();
protected DefaultMQProducer producer;
private ObjectMapper objectMapper = new ObjectMapper();
public BaseProducer() {
producer = new
DefaultMQProducer(getProducerGroup());
}
@PostConstruct
public void postConstruct() {
producer.setNamesrvAddr(getNamesrvAddr());
try {
producer.start();
} catch (MQClientException e) {
LOG.error("producer start exception", e);
throw new RuntimeException(e);
}
}
@Override
public void destroy() throws Exception {
producer.shutdown();
}
protected Message buildMessage(String payload) {
return new Message(getTopic(),
getTag(),
payload.getBytes(StandardCharsets.UTF_8)
);
}
public void publish(T payload) {
try {
String val = objectMapper.writeValueAsString(payload);
producer.send(buildMessage(val));
LOG.info("publish success, topic = {}, tag = {}, msg = {}", getTopic(), getTag(), val);
} catch (Exception e) {
LOG.error("publish exception", e);
}
}
public void publishAsync(T payload) {
try {
String val = objectMapper.writeValueAsString(payload);
producer.send(buildMessage(val), new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
LOG.info("publishAsync success, topic = {}, tag = {}, msg = {}", getTopic(), getTag(), val);
}
@Override
public void onException(Throwable e) {
LOG.error("publish async exception", e);
}
});
} catch (Exception e) {
LOG.error("publishAsync exception", e);
}
}
}
如上所示:
-
nameServr、topic、tag由子类组成
-
我们在构造函数中,创建了Producer对象
-
postConstruct中:设定了NameServer地址,并启动producer
-
publish / publishAsync:发送消息,先根据topic和tag构造消息,然后调用同步 / 异步的接口发送。
-
destroy时,停止producer
接下来我们看下Consumer的基类:
/**
* @(#)BaseConsumer.java, 10月 12, 2021.
* <p>
* Copyright 2021 coder4.com. All rights reserved.
* CODER4.COM PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*/
package com.coder4.homs.demo.server.mq;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.util.CollectionUtils;
import javax.annotation.PostConstruct;
/**
* @author coder4
*/
public abstract class BaseConsumer<T> implements DisposableBean {
protected final Logger LOG = LoggerFactory.getLogger(getClass());
private static final int DEFAULT_BATCH_SIZE = 1;
private static final int MAX_RETRY = 1024;
abstract String getNamesrvAddr();
abstract String getConsumerGroup();
abstract String getTopic();
abstract String getTag();
abstract Class<T> getClassT();
abstract boolean process(T msg);
private ObjectMapper objectMapper = new ObjectMapper();
protected DefaultMQPushConsumer consumer;
public BaseConsumer() {
consumer = new
DefaultMQPushConsumer(getConsumerGroup());
}
@PostConstruct
public void postConstruct() {
consumer.setNamesrvAddr(getNamesrvAddr());
try {
consumer.subscribe(getTopic(), getTag());
} catch (MQClientException e) {
LOG.error("consumer subscribe exception", e);
throw new RuntimeException(e);
}
consumer.setConsumeMessageBatchMaxSize(DEFAULT_BATCH_SIZE);
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
if (CollectionUtils.isEmpty(msgs)) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
if (msgs.size() != DEFAULT_BATCH_SIZE) {
LOG.error("MessageListenerConcurrently callback msgs.size() != 1");
}
MessageExt msg = msgs.get(0);
if (msg.getReconsumeTimes() >= MAX_RETRY) {
LOG.error("reconsume exceed max retry times");
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
try {
if (process(objectMapper.readValue(new String(msg.getBody()), getClassT()))) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} else {
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
} catch (Exception e) {
LOG.error("process exception", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
});
try {
consumer.start();
} catch (MQClientException e) {
LOG.error("consumer start exception", e);
throw new RuntimeException(e);
}
}
@Override
public void destroy() throws Exception {
consumer.shutdown();
}
}
与Producer类似,topic、tag、namesrv由子类指定。
-
postConstruct:订阅了对应topic和tag的消息,并设定回掉函数,这里设定每批次最多拉取1个消息,以最简化处理失败的情况,你可以根据实际情况做出调整。
-
接受消息时,会调用子类的process进行处理,同时进行json的反序列化操作
接下来,我们来写一个Demo的生产者、消费者:
首先配置nameSrv:
# rocketmq
rocketmq.namesrv: 127.0.0.1:9876
接着,定义消息:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class DemoMessage {
private String msg;
private long ts;
}
然后是具体的Consumer和Producer:
package com.coder4.homs.demo.server.mq;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
/**
* @author coder4
*/
@Service
public class DemoConsumer extends BaseConsumer<DemoMessage> {
@Value("${rocketmq.namesrv}")
private String namesrv;
@Override
String getNamesrvAddr() {
return namesrv;
}
@Override
String getConsumerGroup() {
return "demo-consumer";
}
@Override
String getTopic() {
return "demo";
}
@Override
String getTag() {
return "*";
}
@Override
Class<DemoMessage> getClassT() {
return DemoMessage.class;
}
@Override
boolean process(DemoMessage msg) {
LOG.info("process msg = {}", msg);
return true;
}
}
package com.coder4.homs.demo.server.mq;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
/**
* @author coder4
*/
@Service
public class DemoProducer extends BaseProducer<DemoMessage> {
@Value("${rocketmq.namesrv}")
private String namesrv;
@Override
String getNamesrvAddr() {
return namesrv;
}
@Override
String getProducerGroup() {
return "demo-producer";
}
@Override
String getTopic() {
return "demo";
}
@Override
String getTag() {
return "*";
}
}
我们可以调用Producer发送一个消息,然后会收到如下的日志,说明消息已经被成功处理!
2021-10-12 8:01:37.340 INFO 6270 --- [MessageThread_1] c.c.homs.demo.server.mq.DemoConsumer : process msg = DemoMessage(msg=123, ts=1634032897315)
由于篇幅所限,我们只实战了基础的消息收发,推荐你根据文档继续探索其他内容,包括:[集群部署](Deployment - Apache RocketMQ)、[顺序消息](Order Message - Apache RocketMQ)、[广播消息](Broadcasting - Apache RocketMQ)等内容。
微服务开发下篇:日志、链路追踪、监控
随着微服务架构的流行,可观测性(Observability)的理念也逐渐升温。
可观测性是一个源于控制论的概念,映射到微服务架构中,主要指三个方面:
-
日志:微服务的进程产生日志,分散在各处,系统需要收集、归拢日志,并提供统一的日志查询、分析功能。
-
链路追踪:微服务调用关系错综复杂,如果某一个微服务发生故障,很有可能是来源上有的调用挂掉。通过链路追踪,可以轻松的定位和发现问题。
-
监控:监控系统收集物理机、微服务的各类指标(Metrics),从而反应系统运行情况。更进一步,可以通过图表的方式,可视化地展示需求。
本章,我们将围绕上述三点展开:
-
基于ElasticSearch + FileBeats + Kafka + FileBeats + Kibana的日志平台
-
基于SkyWalking的链路追踪系统
-
基于VictorialMetrics + Grafana的监控系统
经过本章的实战,微服务架构的可观测性将得到明显提升。
基于ELKFK打造日志平台
微服务的实例数众多,需要一个强大的日志日志平台,它应具有以下功能:
-
采集:从服务端进程(k8s的Pod中),自动收集日志
-
存储:将日志按照时间序列,存储在持久化的介质上,以供未来查找。
-
检索:根据关键词,时间等条件,方便地检索特定日志内容。
我们将基于ELKFK,打造自己的日志平台。
你可能听说过ELK,那么ELK后面加上的FK是什么呢?
F:Filebeat,轻量级的日志采集插件
K:Kafka,用户缓存日志
日志系统的架构图如下所示:
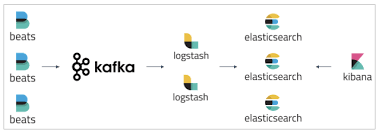
搭建Kafka
Kafka消耗的资源较多,一般多采用独立部署的方式。
这里为了演示方便,我们以单机版为例。
首先下载:
wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
接着,启动zk
bin/zookeeper-server-start.sh config/zookeeper.properties
最后,启动broker
bin/kafka-server-start.sh config/server.properties
我们来创建topic,供后续使用。
bin/kafka-topics.sh --create --topic k8s-log-homs --partitions 3 --replication-factor 1 --bootstrap-server localhost:9092k8s -> (FileBeat) -> kafka
部署FileBeat
有了Kafka之后,我们在Kubernets集群上部署FileBeat,自动采集日志并发送到Kafka的队列中,配置如下:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
paths:
- /var/log/containers/homs*.log
fields:
kafka_topic: k8s-log-homs
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
processors:
- add_cloud_metadata:
- add_host_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output:
kafka:
enabled: true
hosts: ["10.1.172.136:9092"]
topic: '%{[fields.kafka_topic]}'
max_message_bytes: 5242880
partition.round_robin:
reachable_only: true
keep-alive: 120
required_acks: 1
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.15.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
# should be the namespace where filebeat is running
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
labels:
k8s-app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---
配置较多,我们解释一下:
-
采集/var/log/containers目录下的homs*.log文件名的日志
-
将这些日志送到k8s-log-homs这个Kafka的topic中
-
配置Kafka的服务器地址
-
配置其他所需的权限
实际上,上述配置是在官方[原始文件](wget https://raw.githubusercontent.com/elastic/beats/7.15/deploy/kubernetes/filebeat-kubernetes.yaml)基础上修改的,更多配置可以参考[官方文档](Configure the Kafka output | Filebeat Reference [7.15] | Elastic)。
应用上述配置:
kubectl apply -f filebeat.yaml
然后我们查看Kafka收到的日志:
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic k8s-log-homs --from-beginning
符合预期:
...
{"@timestamp":"2021-11-15T03:18:26.487Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.15.2"},"stream":"stdout","message":"2021-11-15 03:18:26.486 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)","log":{"offset":1491,"file":{"path":"/var/log/containers/homs-start-deployment-6878f48fcc-65vcr_default_homs-start-server-d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f.log"}},"input":{"type":"container"},"agent":{"type":"filebeat","version":"7.15.2","hostname":"minikube","ephemeral_id":"335988de-a165-4070-88f1-08c3d6be7ba5","id":"850b6889-85e0-41c5-8a83-bce344b8b2ec","name":"minikube"},"ecs":{"version":"1.11.0"},"container":{"image":{"name":"coder4/homs-start:107"},"id":"d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f","runtime":"docker"},"kubernetes":{"pod":{"ip":"172.17.0.3","name":"homs-start-deployment-6878f48fcc-65vcr","uid":"7d925249-2a77-4c28-a462-001d189cdeaa"},"container":{"name":"homs-start-server"},"node":{"name":"minikube","uid":"faec4c1a-9188-408a-aeec-95b24aa47a88","labels":{"node-role_kubernetes_io/control-plane":"","node_kubernetes_io/exclude-from-external-load-balancers":"","kubernetes_io/hostname":"minikube","kubernetes_io/os":"linux","minikube_k8s_io/commit":"a03fbcf166e6f74ef224d4a63be4277d017bb62e","minikube_k8s_io/name":"minikube","minikube_k8s_io/updated_at":"2021_11_05T12_15_23_0700","node-role_kubernetes_io/master":"","beta_kubernetes_io/arch":"amd64","beta_kubernetes_io/os":"linux","minikube_k8s_io/version":"v1.22.0","kubernetes_io/arch":"amd64"},"hostname":"minikube"},"labels":{"app":"homs-start","pod-template-hash":"6878f48fcc"},"namespace_uid":"b880885d-c94a-4cf2-ba2c-1e4cb0d1a691","namespace_labels":{"kubernetes_io/metadata_name":"default"},"namespace":"default","deployment":{"name":"homs-start-deployment"},"replicaset":{"name":"homs-start-deployment-6878f48fcc"}},"orchestrator":{"cluster":{"url":"control-plane.minikube.internal:8443","name":"mk"}},"host":{"mac":["02:42:d5:27:3f:31","c6:64:9d:f9:89:7b","5a:b1:a0:66:ee:d3","46:41:6e:14:85:14","02:42:c0:a8:31:02"],"hostname":"minikube","architecture":"x86_64","os":{"kernel":"5.10.47-linuxkit","codename":"Core","type":"linux","platform":"centos","version":"7 (Core)","family":"redhat","name":"CentOS Linux"},"id":"1820c6c61258c329e88764d3dc4484f3","name":"minikube","containerized":true,"ip":["172.17.0.1","192.168.49.2"]}}
{"@timestamp":"2021-11-15T03:18:26.573Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.15.2"},"log":{"offset":2111,"file":{"path":"/var/log/containers/homs-start-deployment-6878f48fcc-65vcr_default_homs-start-server-d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f.log"}},"stream":"stdout","input":{"type":"container"},"host":{"id":"1820c6c61258c329e88764d3dc4484f3","containerized":true,"ip":["172.17.0.1","192.168.49.2"],"name":"minikube","mac":["02:42:d5:27:3f:31","c6:64:9d:f9:89:7b","5a:b1:a0:66:ee:d3","46:41:6e:14:85:14","02:42:c0:a8:31:02"],"hostname":"minikube","architecture":"x86_64","os":{"family":"redhat","name":"CentOS Linux","kernel":"5.10.47-linuxkit","codename":"Core","type":"linux","platform":"centos","version":"7 (Core)"}},"ecs":{"version":"1.11.0"},"agent":{"version":"7.15.2","hostname":"minikube","ephemeral_id":"335988de-a165-4070-88f1-08c3d6be7ba5","id":"850b6889-85e0-41c5-8a83-bce344b8b2ec","name":"minikube","type":"filebeat"},"message":"2021-11-15 03:18:26.573 INFO 1 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext","container":{"id":"d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f","runtime":"docker","image":{"name":"coder4/homs-start:107"}},"kubernetes":{"replicaset":{"name":"homs-start-deployment-6878f48fcc"},"node":{"name":"minikube","uid":"faec4c1a-9188-408a-aeec-95b24aa47a88","labels":{"node-role_kubernetes_io/control-plane":"","minikube_k8s_io/commit":"a03fbcf166e6f74ef224d4a63be4277d017bb62e","kubernetes_io/os":"linux","kubernetes_io/arch":"amd64","node_kubernetes_io/exclude-from-external-load-balancers":"","beta_kubernetes_io/arch":"amd64","beta_kubernetes_io/os":"linux","minikube_k8s_io/updated_at":"2021_11_05T12_15_23_0700","node-role_kubernetes_io/master":"","kubernetes_io/hostname":"minikube","minikube_k8s_io/name":"minikube","minikube_k8s_io/version":"v1.22.0"},"hostname":"minikube"},"namespace_labels":{"kubernetes_io/metadata_name":"default"},"namespace":"default","deployment":{"name":"homs-start-deployment"},"pod":{"ip":"172.17.0.3","name":"homs-start-deployment-6878f48fcc-65vcr","uid":"7d925249-2a77-4c28-a462-001d189cdeaa"},"labels":{"app":"homs-start","pod-template-hash":"6878f48fcc"},"container":{"name":"homs-start-server"},"namespace_uid":"b880885d-c94a-4cf2-ba2c-1e4cb0d1a691"},"orchestrator":{"cluster":{"url":"control-plane.minikube.internal:8443","name":"mk"}}}
{"@timestamp":"2021-11-15T03:18:27.470Z","@metadata":{"beat":"filebeat","type":"_doc","version":"7.15.2"},"input":{"type":"container"},"orchestrator":{"cluster":{"url":"control-plane.minikube.internal:8443","name":"mk"}},"agent":{"type":"filebeat","version":"7.15.2","hostname":"minikube","ephemeral_id":"335988de-a165-4070-88f1-08c3d6be7ba5","id":"850b6889-85e0-41c5-8a83-bce344b8b2ec","name":"minikube"},"stream":"stdout","message":"2021-11-15 03:18:27.470 INFO 1 --- [ main] com.homs.start.StartApplication : Started StartApplication in 3.268 seconds (JVM running for 3.738)","kubernetes":{"pod":{"name":"homs-start-deployment-6878f48fcc-65vcr","uid":"7d925249-2a77-4c28-a462-001d189cdeaa","ip":"172.17.0.3"},"container":{"name":"homs-start-server"},"labels":{"app":"homs-start","pod-template-hash":"6878f48fcc"},"node":{"labels":{"kubernetes_io/arch":"amd64","node_kubernetes_io/exclude-from-external-load-balancers":"","beta_kubernetes_io/arch":"amd64","kubernetes_io/hostname":"minikube","minikube_k8s_io/name":"minikube","minikube_k8s_io/version":"v1.22.0","kubernetes_io/os":"linux","minikube_k8s_io/commit":"a03fbcf166e6f74ef224d4a63be4277d017bb62e","minikube_k8s_io/updated_at":"2021_11_05T12_15_23_0700","node-role_kubernetes_io/control-plane":"","node-role_kubernetes_io/master":"","beta_kubernetes_io/os":"linux"},"hostname":"minikube","name":"minikube","uid":"faec4c1a-9188-408a-aeec-95b24aa47a88"},"namespace":"default","deployment":{"name":"homs-start-deployment"},"namespace_uid":"b880885d-c94a-4cf2-ba2c-1e4cb0d1a691","namespace_labels":{"kubernetes_io/metadata_name":"default"},"replicaset":{"name":"homs-start-deployment-6878f48fcc"}},"ecs":{"version":"1.11.0"},"host":{"os":{"codename":"Core","type":"linux","platform":"centos","version":"7 (Core)","family":"redhat","name":"CentOS Linux","kernel":"5.10.47-linuxkit"},"id":"1820c6c61258c329e88764d3dc4484f3","containerized":true,"ip":["172.17.0.1","192.168.49.2"],"mac":["02:42:d5:27:3f:31","c6:64:9d:f9:89:7b","5a:b1:a0:66:ee:d3","46:41:6e:14:85:14","02:42:c0:a8:31:02"],"hostname":"minikube","architecture":"x86_64","name":"minikube"},"log":{"offset":2787,"file":{"path":"/var/log/containers/homs-start-deployment-6878f48fcc-65vcr_default_homs-start-server-d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f.log"}},"container":{"image":{"name":"coder4/homs-start:107"},"id":"d37b0467d097c00bd203089a97df371cdbacc156493f6b2d995b80395caf516f","runtime":"docker"}}
重启deployment
kubectl rollout restart deployment homs-start-deployment
启动ElasticSearch
#!/bin/bash
NAME="elasticsearch"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/elasticsearch"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--env discovery.type=single-node \
-p 9200:9200 \
-p 9300:9300 \
--detach \
--restart always \
docker.elastic.co/elasticsearch/elasticsearch:7.15.2
启动ElasticSearch
在配置LogStash前,我们先要启动最终的存储,即ElasticSearch。
为了演示方便,我们使用单机模式启动:
#!/bin/bash
NAME="elasticsearch"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/elasticsearch"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--env discovery.type=single-node \
-p 9200:9200 \
-p 9300:9300 \
--detach \
--restart always \
docker.elastic.co/elasticsearch/elasticsearch:7.15.2
你可以通过curl命令,检查启动是否成功:
curl 127.0.0.1:9200
{
"name" : "elasticsearch",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "yxLELfOmT9OXPXxjh7g7Nw",
"version" : {
"number" : "7.15.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c",
"build_date" : "2021-11-04T14:04:42.515624022Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
温馨提示:默认情况是没有用户名、密码的,用于生产环境时请务必开启。
启动Logstash
首先,配置logstash.conf,将其放到pipeline子目录下:
input {
kafka {
bootstrap_servers => ["10.1.172.136:9092"]
group_id => "k8s-log-homs-logstash"
topics => ["k8s-log-homs"]
codec => json
}
}
filter {
if [message] =~ "\tat" {
grok {
match => ["message", "^(\tat)"]
add_tag => ["stacktrace"]
}
}
grok {
match => [ "message",
"%{TIMESTAMP_ISO8601:logtime}%{SPACE}%{LOGLEVEL:level}%{SPACE}(?<logmessage>.*)"
]
}
date {
match => [ "logtime" , "yyyy-MM-dd HH:mm:ss.SSS" ]
}
#mutate {
# remove_field => ["message"]
#}
}
output {
elasticsearch {
hosts => "http://10.1.172.136:9200"
user =>"elastic"
password =>""
index => "k8s-log-homs-%{+YYYY.MM.dd}"
}
}
这里,我们使用了grok来拆分message字段,你可以在使用[在线工具](Test grok patterns)验证规则。
接着,我们启动logstash
#!/bin/bash
NAME="logstash"
PUID="1000"
PGID="1000"
VOLUME="$(pwd)/pipeline"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--volume "$VOLUME":/usr/share/logstash/pipeline \
--detach \
--restart always \
docker.elastic.co/logstash/logstash:7.15.2
上述直接挂载了前面配置的pipeline目录。
Kibana
最后,我们启动kibana:
#!/bin/bash
NAME="kibana"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--env "ELASTICSEARCH_HOSTS=http://10.1.172.136:9200" \
-p 5601:5601 \
--detach \
--restart always \
docker.elastic.co/kibana/kibana:7.15.2
如果一切顺利,你会看到如图所示的日志:
至此,我们已经成功搭建了自己的日志平台。
基于SkyWalking的链路追踪系统
链路追踪提供了分布式调用链路的还原、统计、分析等功能,是提升微服务诊断效率的重要环节。
本节,我们将基于SkyWalking搭建链路追踪系统。
SkyWalking是一款开源的APM(Application Performance Monitor)工具,以Java Agent + 插件化的方式运行。2019年其从孵化器毕业,正式成为Apache的顶级项目。
单机实验
我们首先跑通单机版的链路追踪。
SkyWalking支持多种后台存储,这里我们选用ElasticSearch:
#!/bin/bash
NAME="elasticsearch"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/elasticsearch"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--env discovery.type=single-node \
--volume "$VOLUME:/usr/share/elasticsearch/data" \
-p 9200:9200 \
-p 9300:9300 \
--detach \
--restart always \
docker.elastic.co/elasticsearch/elasticsearch:7.15.2
接着,我们启动SkyWalking的后台服务:
#!/bin/bash
NAME="skywalking"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-e SW_STORAGE=elasticsearch7 \
-e SW_STORAGE_ES_CLUSTER_NODES="10.1.172.136:9200" \
-p 12800:12800 \
-p 11800:11800 \
--detach \
--restart always \
apache/skywalking-oap-server:8.7.0-es7
最后,启动SkyWalking的UI服务:
#!/bin/bash
NAME="skywalkingui"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-e SW_OAP_ADDRESS="http://10.1.172.136:12800" \
-p 8080:8080 \
--detach \
--restart always \
apache/skywalking-ui:8.7.0
上述,我们让容器直接使用了Host Net:10.1.172.136。
下一步,我们下载最新版的Java Agent,其支持的框架可以在[这里](Tracing and Tracing based Metrics Analyze Plugins | Apache SkyWalking)查看。
解压后,我们直接使用java命令行运行:
java -javaagent:./skywalking-agent/skywalking-agent.jar -Dskywalking.agent.service_name=homs-start -Dskywalking.collector.backend_service=10.1.172.136:11800 -jar ./homs-start-0.0.1-SNAPSHOT.jar
如上所示:
-
服务名字:homs-start
-
SkyWalking后台服务地址:10.1.172.136:11800
启动成功后,我们尝试访问端口:
curl "127.0.0.1:8080"
查看SkyWalking的UI,可以发现,已经统计到了链路追踪!
Kubernets中部署SkyWalking
在Kubernets环境中,我们倾向只部署无状态服务,以便拓展。
而对于SkyWaling Server这种服务,会占用较大性能,且没有太多需要扩展的场景,因此我们维持其外部部署方式,不上k8s。
回顾下之前的内容,我们的homs-start是通过Docker镜像的方式启动的Pod和Deployment。
我们需要对其进行改造,添加initContainer,注入Java Agent:
apiVersion: apps/v1
kind: Deployment
metadata:
name: homs-start-deployment
labels:
app: homs-start
spec:
selector:
matchLabels:
app: homs-start
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: homs-start
spec:
volumes:
- name: skywalking-agent
emptyDir: {}
containers:
- name: homs-start-server
image: coder4/homs-start:107
ports:
- containerPort: 8080
volumeMounts:
- name: skywalking-agent
mountPath: /skywalking
env:
- name: JAVA_TOOL_OPTIONS
value: -javaagent:/skywalking/agent/skywalking-agent.jar
- name: SW_AGENT_NAME
value: homs-start
- name: SW_AGENT_COLLECTOR_BACKEND_SERVICES
value: 10.1.172.136:11800
resources:
requests:
memory: 500Mi
initContainers:
- name: agent-container
image: apache/skywalking-java-agent:8.8.0-java8
volumeMounts:
- name: skywalking-agent
mountPath: /agent
command: [ "/bin/sh" ]
args: [ "-c", "cp -R /skywalking/agent /agent/" ]
如上所示:
-
这里我们没有额外制作agent的镜像,而是使用了官方的最新版
-
我们添加了全局的临时Volume:skywalking-agent
-
添加了initContainer:agent-container,主要负责启动时拷贝agent的jar包
-
在启动homs-start-server时需要设定一些环境变量参数
启动成功后,我们尝试登录minikube访问服务:
minikube ssh
Last login: Tue Nov 16 07:54:28 2021 from 192.168.49.1
docker@minikube:~$ curl "172.17.0.3:8080"
{"timestamp":"2021-11-16T07:55:08.669+00:00","status":404,"error":"Not Found","path":"/"}
然后查看SkyWalking的UI,也能成功记录到最新追踪请求!
至此,我们已经搭建了最基本的链路追踪系统,其还有很大的优化空间:
-
官方agent镜像中包含了全量插件,你应当根据实际需要剪裁
-
微服务中会有某些缺乏Agent插件的场景,需要自行定制插件
-
不仅agent,服务的jar包其实也是可以通过initContainer来拷贝的,这可以进一步压缩镜像体积。
上述优化,做为课后作业,留给喜欢挑战的你吧:-)
基于MicroMeter实现应用监控指标
提到“监控”(Moniter),你的第一反应是什么?
是老传统监控软件Zabbix、Nagios?还是近几年火爆IT圈的Promethos?
别急着比较系统,这篇文章,我们先聊聊应用监控指标。
顾名思义,“应用监指标”就是根据监控需求,在我们的应用系统中预设埋点,并支持与监控系统对接。
典型的监控项如:接口请求次数、接口响应时间、接口报错次数....
我们将介绍MicroMeter开源项目,并使用它实现Spring MVC的应用监控指标。
MicroMeter简介
Micrometer是社区最流行的监控项项目之一,它提供了一个抽象、强大、易用的抽象门面接口,可以轻松的对接包括Prometheus、JMX等在内的近20种监控系统。它的作用和Slf4j类似,只不过它关注的不是日志,而是应用指标(application metrics)。
自定义应用监控项初探
下面,我们来开始micrometer之旅。
由于网上关于micrometer对接Prometheus的文章已经很多了,这里我特意选择了JMX。
通过JMX Bean暴露的监控项,你可以轻松的对接Zabbix等老牌监控系统。
这里提醒的是JMX不支持类似Prometheus的层级结构,而只支持一级结构(tag会被打平),具体可以参见官方文档。当然,这在代码实现上是完全透明的。
首先,我们新建一个简单的Spring Boot项目,并引入pom文件:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-jmx</artifactId>
<version>1.8.7</version>
</dependency>
然后开发如下的Spring MVC接口:
package com.coder4.homs.micrometer.web;
import com.coder4.homs.micrometer.web.data.UserVO;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
@RestController
public class UserController {
@Autowired
private MeterRegistry meterRegistry;
private Counter COUNTER_GET_USER;
@PostConstruct
public void init() {
COUNTER_GET_USER = meterRegistry.counter("app_requests_method_count", "method", "UserController.getUser");
}
@GetMapping(path = "/users/{id}")
public UserVO getUser(@PathVariable int id) {
UserVO user = new UserVO();
user.setId(id);
user.setName(String.format("user_%d", id));
COUNTER_GET_USER.increment();
return user;
}
}
在上面的代码中:
-
我们实现了UserController这个REST接口,他之中的/users/{id}可以获取用户。
-
UserController注册了一个Counter,Counter由名字和tag组成,用过Prometheus的应该很熟悉这种套路了。
-
每次请求时,会将上述Counter加一操作。
我们来测试一下,执行2次
curl "127.0.0.1:8080/users/1"
{"id":1,"name":"user_1"}
然后打开本地的jconsole,可以发现JMX Bean暴露出了了metrics、gauge等分类,我们打开"metrics/app_requests_method_..."这个指标,点击进去,可以发现具体的值也就是2。
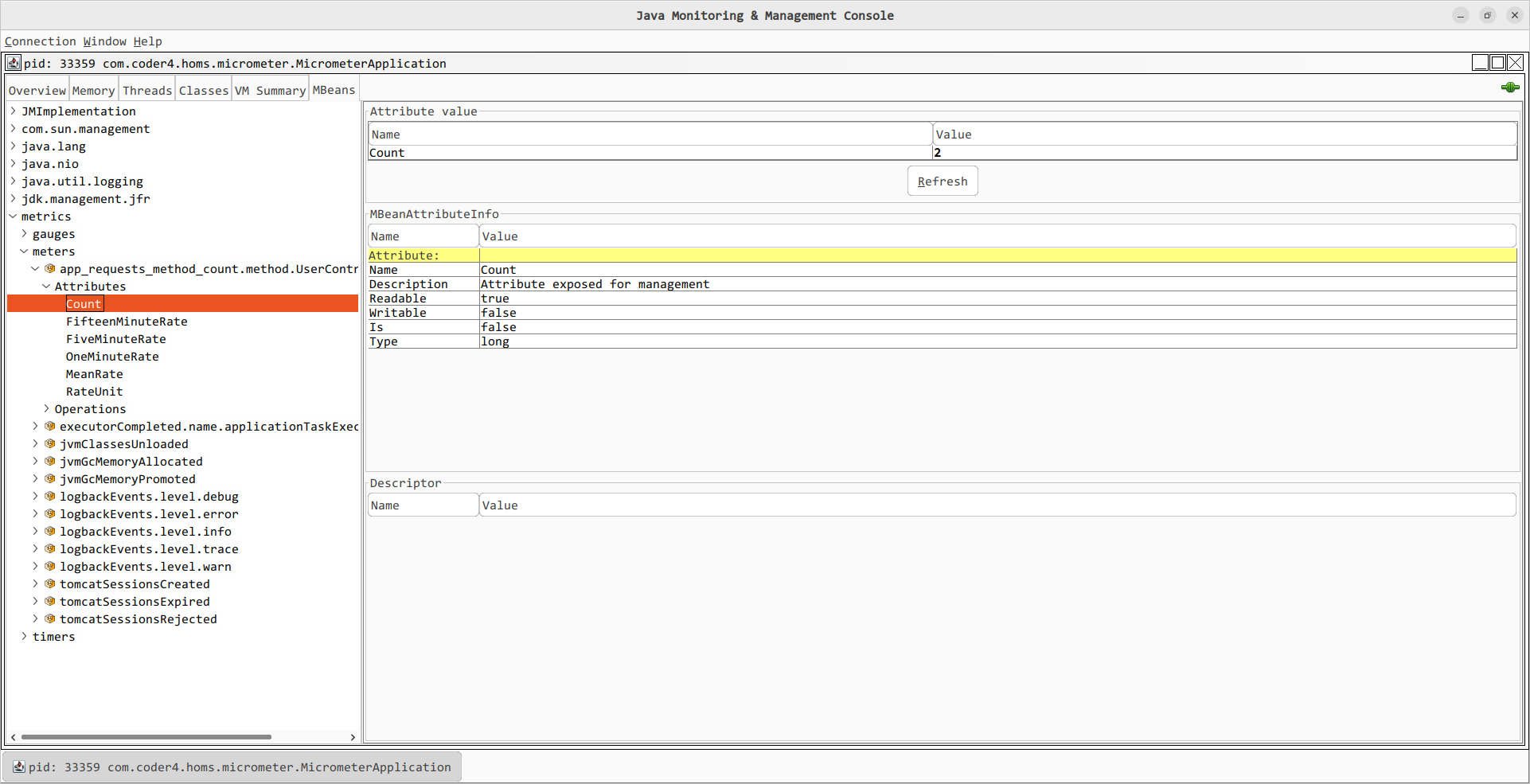
借助拦截器批量统计监控项目
上述代码可以实现功能,但是你应该发现了,实现起来很繁琐,如果我们有10个接口,那岂不是要写很多无用代码?
相信你已经想到了,可以用类似AOP (切面编程)的思路,解决问题。
不过针对Spring MVC这个场景,使用AOP有点“大炮打蚊子”的感觉,我们可以使用拦截器实现。
首先自定义拦截器的自动装配:
package com.coder4.homs.micrometer.configure;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class MeterConfig implements WebMvcConfigurer {
@Bean
public MeterInterceptor getMeterInterceptor() {
return new MeterInterceptor();
}
@Override
public void addInterceptors(InterceptorRegistry registry){
registry.addInterceptor(getMeterInterceptor())
.addPathPatterns("/**")
.excludePathPatterns("/error")
.excludePathPatterns("/static/*");
}
}
上面代码很简单,就是新增了新的拦截器MeterInterceptor。
我们看下拦截器做了什么:
package com.coder4.homs.micrometer.configure;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.DistributionSummary;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Optional;
public class MeterInterceptor implements HandlerInterceptor {
@Autowired
private MeterRegistry meterRegistry;
private ThreadLocal<Long> tlTimer = new ThreadLocal<>();
private static Optional<String> getMethod(HttpServletRequest request, Object handler) {
if (handler instanceof HandlerMethod) {
return Optional.of(String.format("%s_%s_%s", ((HandlerMethod) handler).getBeanType().getSimpleName(),
((HandlerMethod) handler).getMethod().getName(), request.getMethod()));
} else {
return Optional.empty();
}
}
private void recordTimeDistribution(HttpServletRequest request, Object handler, long ms) {
Optional<String> methodOp = getMethod(request, handler);
if (methodOp.isPresent()) {
DistributionSummary.builder("app_requests_time_ms")
.tag("method", methodOp.get())
.publishPercentileHistogram()
.register(meterRegistry)
.record(ms);
}
}
public Optional<Counter> getCounterOfTotalCounts(HttpServletRequest request, Object handler) {
Optional<String> methodOp = getMethod(request, handler);
if (methodOp.isPresent()) {
return Optional.of(meterRegistry.counter("app_requests_total_counts", "method",
methodOp.get()));
} else {
return Optional.empty();
}
}
public Optional<Counter> getCounterOfExceptionCounts(HttpServletRequest request, Object handler) {
Optional<String> methodOp = getMethod(request, handler);
if (methodOp.isPresent()) {
return Optional.of(meterRegistry.counter("app_requests_exption_counts", "method",
methodOp.get()));
} else {
return Optional.empty();
}
}
public Optional<Counter> getCounterOfRespCodeCounts(HttpServletRequest request, HttpServletResponse response,
Object handler) {
Optional<String> methodOp = getMethod(request, handler);
if (methodOp.isPresent()) {
return Optional.of(meterRegistry.counter(String.format("app_requests_resp%d_counts", response.getStatus()),
"method", methodOp.get()));
} else {
return Optional.empty();
}
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
tlTimer.set(System.currentTimeMillis());
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// record time
recordTimeDistribution(request, handler, System.currentTimeMillis() - tlTimer.get());
tlTimer.remove();
// total counts
getCounterOfTotalCounts(request, handler).ifPresent(counter -> counter.increment());
// different response code count
getCounterOfRespCodeCounts(request, response, handler).ifPresent(counter -> counter.increment());
if (ex != null) {
// exception counts
getCounterOfExceptionCounts(request, handler).ifPresent(counter -> counter.increment());
}
}
}
代码有点长,解释一下:
-
自动注入MeterRegistry,老套路了
-
getCounterOfXXX几个方法,通过request、handler来生成具体的监控项名称和标签,形如:app_requests_method_count.method.UserController.getUser。
-
preHandle中预设了ThreadLocal的定时器
-
recordTimeDistribution使用了Distribution,这是一个可以统计百分位的MicroMeter组件,类似Prometheus的histogram功能的你应该能秒懂。
-
afterCompletion根据前面定时器,计算本次请求时间,并记录到Distributon中。
-
afterCompletion记录总请求数、分resp.code的请求数、出错请求数。
我们打开jconsole看下:
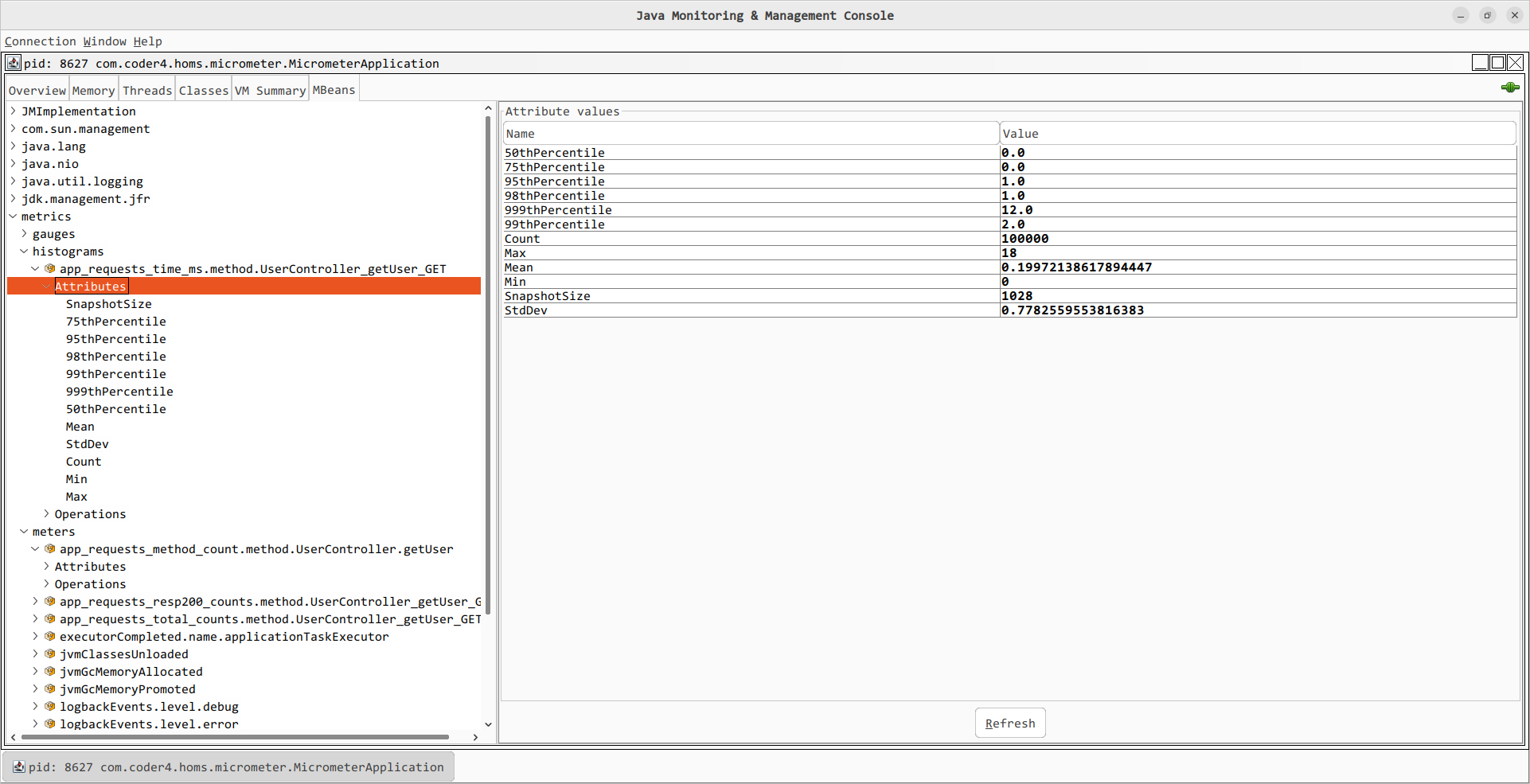
在之前meters的基础上,新增了histogram分类,里面会详细记录请求时间,比如我这里做了一些本地压测后,.99时间是12ms,.95时间是1ms。
在上面的基础上稍做修改,就可以投入使用了。
感兴趣的话,你可以探索如何对Dubbo、gRPC等RPC接口进行应用程序监控项。
本篇文章的代码,我放到了homs-micrometer这个github项目中,感兴趣的话可以查阅。
基于VictoriaMetrics + Grafana的监控系统
监控(Monitor)与度量(Metrics)是可观测性的重要环节。
在本节中,我们将使用VirtorialMetrics构建自己的监控系统。
提到监控系统的工具,你可能会想到老牌的Zabbix、Nagios,也可能听说过新星的Prometheus。
Prometheus是一个开源的监控系统,凭借开放的生态环境、云原生等特性,逐步成为了微服务架构下的事实标准。
然而,由于Prometheus设计初期并没有考虑存储扩展性,因此当监控的metrics升高到每秒百万级别后,会出现较为明显的性能瓶颈。
VictoriaMetrics是进来快速崛起的开源监控项目,其在设计之处就支持水平拓展,并且兼容了Prometheus的协议,可以应对日益增长的metrics需求。
Grafana是一款开源的可视化分析工具,通过丰富的仪表盘,让用户能够更直观的理解Metrics。
本节,我们将基于Victoria-Metrics + Grafana搭建监控系统。
安装VictoriaMetrics
在下面的章节,我们将演示搭建vm的single版本,由于VM出色的性能,single已经足以应对中小企业的监控需求。你可以根据实际的需要,[部署集群版本](HA monitoring setup in Kubernetes via VictoriaMetrics Cluster · VictoriaMetrics)。
首先添加helm源
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
helm search repo vm/
NAME CHART VERSION APP VERSION DESCRIPTION
vm/victoria-metrics-agent 0.7.34 v1.69.0 Victoria Metrics Agent - collects metrics from ...
vm/victoria-metrics-alert 0.4.14 v1.69.0 Victoria Metrics Alert - executes a list of giv...
vm/victoria-metrics-auth 0.2.33 1.69.0 Victoria Metrics Auth - is a simple auth proxy ...
vm/victoria-metrics-cluster 0.9.12 1.69.0 Victoria Metrics Cluster version - high-perform...
vm/victoria-metrics-k8s-stack 0.5.9 1.69.0 Kubernetes monitoring on VictoriaMetrics stack....
vm/victoria-metrics-operator 0.4.2 0.20.3 Victoria Metrics Operator
vm/victoria-metrics-single 0.8.12 1.69.0 Victoria Metrics Single version - high-performa...
我们查看所有可配置的参数选项:
helm show values vm/victoria-metrics-single > values.yaml
将其修改为如下设置:
server:
persistentVolume:
enabled: false
accessModes:
- ReadWriteOnce
annotations: {}
storageClass: ""
existingClaim: ""
matchLabels: {}
mountPath: /storage
subPath: ""
size: 16Gi
scrape:
enabled: true
configMap: ""
config:
global:
scrape_interval: 15s
scrape_configs:
- job_name: victoriametrics
static_configs:
- targets: [ "localhost:8428" ]
- job_name: "kubernetes-apiservers"
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
- job_name: "kubernetes-nodes"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [ __meta_kubernetes_node_name ]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/$1/proxy/metrics
- job_name: "kubernetes-nodes-cadvisor"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [ __meta_kubernetes_node_name ]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor
metric_relabel_configs:
- action: replace
source_labels: [pod]
regex: '(.+)'
target_label: pod_name
replacement: '${1}'
- action: replace
source_labels: [container]
regex: '(.+)'
target_label: container_name
replacement: '${1}'
- action: replace
target_label: name
replacement: k8s_stub
- action: replace
source_labels: [id]
regex: '^/system\.slice/(.+)\.service$'
target_label: systemd_service_name
replacement: '${1}'
如上所述:
-
我们禁用了PV,这将默认使用local的emptydir。建议你在生产环境,根据需要自行配置可自动装配的存储插件。
-
从Kubernetes集群抓取信息,并做了一些label上的转化。
-
如果你熟悉Prometheus的话,会发现上述配置和Prometheus基本是兼容的。
安装vmsingle:
helm install vmsingle vm/victoria-metrics-single -f ./values.yaml -n vm
W1117 14:46:54.020279 26203 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W1117 14:46:54.066766 26203 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: vmsingle
LAST DEPLOYED: Wed Nov 17 14:46:53 2021
NAMESPACE: vm
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The VictoriaMetrics write api can be accessed via port 8428 on the following DNS name from within your cluster:
vmsingle-victoria-metrics-single-server.vm.svc.cluster.local
Metrics Ingestion:
Get the Victoria Metrics service URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace vm -l "app=server" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace vm port-forward $POD_NAME 8428
Write url inside the kubernetes cluster:
http://vmsingle-victoria-metrics-single-server.vm.svc.cluster.local:8428/api/v1/write
Read Data:
The following url can be used as the datasource url in Grafana::
http://vmsingle-victoria-metrics-single-server.vm.svc.cluster.local:8428
上述的Read Data地址,后续需要用的,请复制、保存好。 部署成功后,我们查看下Pod,运行成功:
kubectl get pods
default vmsingle-victoria-metrics-single-server-0 1/1 Running 0 59s
安装Grafana
首先,依然是添加helm源:
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
接下来,自定义参数并安装:
cat <<EOF | helm install my-grafana grafana/grafana -f -
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: victoriametrics
type: prometheus
orgId: 1
url: http://vmsingle-victoria-metrics-single-server.default.svc.cluster.local:8428
access: proxy
isDefault: true
updateIntervalSeconds: 10
editable: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
victoriametrics:
gnetId: 10229
revision: 21
datasource: victoriametrics
kubernetes:
gnetId: 14205
revision: 1
datasource: victoriametrics
EOF
在上述配置中,我们添加了默认的数据源,使用前面创建好的VM地址。
接着,我们获取Grafana的密码:
kubectl get secret --namespace default my-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
SOnFX4CdrlyG5JACyBedk9mJk7btMz8cXjk7ZiOZ
然后代理端口到本地
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=my-grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
访问http://127.0.0.1:3000,使用admin / 前面的密码。
如果一切顺利,会发现已经有Kubernetes集群的数据了:
至此,我们搭建了基础的监控系统,你还可以做的更好:
-
添加PV,让数据可以真正持久化
-
部署分布式的版本
-
在微服务中,暴露一些自定义监控指标,并将其抓取到VM的存储中
容器与编排系统
最热门的容器方案 - Docker - 诞生于2013年。借助Namespace、cgroup、rootfs三大核心技术,Docker给软件开发、运维都来了颠覆性的体验。
随着容器技术的普及,容器依赖、跨主机通信的需求日益显著。Kubernetes很好的解决了跨主机通信的问题,将容器管理集群化,容器编排系统化,并成为了容器编排系统的事实标准。
本章将围绕Kubernetes展开,包括:
-
探索容器技术的意义
-
通过案例快速入门Kubernetees
-
基于Keepalived,搭建高可用的Kubernetes集群
-
介绍ingress等集群对外暴露的方式
从集装箱到容器
容器化是一种全新的交付方式,它把应用及运行环境,整体打包成一个的镜像,从而保证了运行环境的统一。
容器也是一种轻量级的隔离技术,在保证文件系统、网络、CPU等基础隔离的基础上,拥有更快的启动速度,更小的资源开销。
还记得我们在第一章指出的微服务缺点么?运维难度、上线速度。这些都可以通过容器 / 容器编排技术得到管理。可以说,微服务架构的落地,离不开容器技术。
从集装箱革命到运维革命
这是著名的容器开源项目Docker的logo:
![]()
你有没有注意到蓝色鲸鱼背上的东西呢?
没错,是集装箱。
尽管货物的海运已经出现了几百年,但直到20世纪中叶,货物运输依然是一种劳动力密集型工作。码头雇佣了数以万计的工人,将货物从岸上搬运到船舱中。由于货物的种类繁多,体积不一、传送带、铲车都不能根本的解决问题,货物装卸依然大量依赖人工,而且装卸时间大量占用了港口时间,装卸价格居高不下。
20世纪50年代开始,集装箱逐渐走向商用的舞台。货物在岸上按照整齐的规格码放整齐,从而可以封装进集装箱。而装卸货物只需要机械来搬运集装箱即可,极大提高了港口的装卸效率。
集装箱革命使得货物的装卸成本从5美元/吨骤降到16美分/吨,节约了97%......
而以docker为代表的容器化项目的崛起,也推进了运维圈的另一场“革命”:容器就是集装箱,货物则是运行于容器中的,各式应用。
容器技术的出现,根本性的解决了如下的技术难题:
-
运行环境的标准化:为了让应用程序在生产机上跑起来,经常安装不同操作系统版本,不同版本的依赖软件库、环境配置......这些过程非常繁琐,还经常会由于版本的细微差异,和开发环境不一致,出现“这个程序本地好好的,放到服务器上就崩溃”这类情况。容器可以使用统一的描述语言(如Dockerfile),快速构建出完全相同的、标准化环境,从而解决运行环境的问题。
-
隔离化:如果都部署在一台物理机上,很可能会发生包、依赖冲突,导致无法运维,而容器可以为运行在同一台物理机上的应用程序,创建不同的隔离环境(文件系统、网络、物理资源等)。
docker是最成功的容器化项目之一,但并不是唯一的选项,这里列举几个强有力的竞争者:
-
rkt container:由RedHat主导的容器化项目,改进了Docker隔离模型的许多缺陷,具有更好的安全性能。
-
kata container:轻量级的定制化虚拟机(VM),具有比肩容器化的技术,以及VM级别的隔离性。
从容器到容器编排
容器解决了运行环境标准化、隔离化的问题,但随着容器数量的不断提升增长,如何管理他们成为了一个新问题。
容器编排指的是:自动化容器的部署、管理、扩展和联网。
除了规模化,容器编排还面临以下问题:
它解决了以下问题:
-
应用不是孤立的,容器的运行也会有依赖关系,如何进行管理?
-
如何在不影响业务运行的前提下,升级容器(内的应用)?
-
如何在容器应用挂掉的时候,自动恢复故障?
-
如何管理容器的本地存储?
如今,Kubernetes已经成为容器编排领域的事实标准,它的特性有:
-
滚动升级、回滚:支持渐进式的升级应用镜像版本,并可轻松地回滚到之前的版本。
-
服务发现、负载均衡:内置了基于DNS / VIP的负载均衡机制。
-
异构存储:CSI机制,支持云存储、NFS、Ceph等多种方式。
-
密钥、配置存储:密码、配置等信息的存储。
-
灵活的资源分配:支持多种资源保证方式,最大限度利用资源。
-
批量任务:支持后台离线、批量任务。
-
水平自动扩展:快速扩所容能力,支持人工 / 负载自适应
-
健康、恢复:内置多种健康检查、自恢复机制
-
拓展性:提供了多个扩展点,在不改变k8s代码的前提下,轻松拓展功能
纸上得来终觉浅,简单的介绍是远不够的。
在下一节,我们将使用一个例子,快速入门Kubernetes。
快速入门Kubernetes
安装篇
我们以Ubuntu为例,介绍Kubernetes基础工具的安装,若你使用其他操作系统,可以参考官方文档。
首先安装kubectl:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubectl
接着,我们安装minikube,这是一个用于本地学习和测试的kubernetes集群:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube_latest_amd64.deb
sudo dpkg -i minikube_latest_amd64.deb
启动minikube
第一次启动Minikube,需要下载虚拟机、对应镜像,时间回稍长一些。
minikube start
成功后,我们看下状态:
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
如果需要关机,可以暂停 / 恢复minikube集群
minikube pause
minikube resume
如果想重置minikube集群,可以使用删除后重新启动
minikube delete
部署你的第一个服务
我们在minikube上部署一台nginx
kubectl create deployment my-nginx --image=nginx:stable
稍等片刻后,我们看下,已经创建成功:
kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx-7bc876dc4b-r5zqr 1/1 Running 0 22s
我们查看下pod的信息,特别是IP
kubectl describe pod my-nginx-7bc876dc4b-r5zqr | grep IP
IP: 172.17.0.3
我们尝试访问一下,发现无法成功:
curl "http://172.17.0.3"
这是因为,minikube的网络环境,与我们本机是相互隔离的,我们需要先登录到minikube内,然后再尝试:
minikube ssh
curl "http://172.17.0.3"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 612 100 612 0 0 597k 0 --:--:-- --:--:-- --:--:-- 597k
成功!
下面,我们退出minikube集群环境,尝试对nginx部署扩容:
kubectl scale deployment my-nginx --replicas=5
deployment.apps/my-nginx scaled
稍等片刻后,我们查看,发现扩容成功:
kubectl get pod
NAME READY STATUS RESTARTS AGE
my-nginx-7bc876dc4b-226g9 1/1 Running 0 60s
my-nginx-7bc876dc4b-872v2 1/1 Running 0 60s
my-nginx-7bc876dc4b-fvnwf 1/1 Running 0 60s
my-nginx-7bc876dc4b-fzr8s 1/1 Running 0 60s
my-nginx-7bc876dc4b-r5zqr 1/1 Running 1 5m36s
如何在mini集群外(例如我们本地)访问nginx呢?
可以为上述deployment,暴露外部的LoadBalancer:
kubectl expose deployment my-nginx --type=LoadBalancer --port=80
我们看一下状态,会发现外部的IP是"pending"
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 67m
my-nginx LoadBalancer 10.104.5.62 <pending> 80:30229/TCP 37s 8m18s
需要启用minikube的隧道,来分配"外部IP",这里的外部是相对于minikube而言的,实际上是我们本机网络的IP。
minikube tunnel
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 67m
my-nginx LoadBalancer 10.104.5.62 127.0.0.1 80:30229/TCP 24s
9m25s
启动隧道后,发现暴露到了127.0.0.1的80端口上,我们试一下:
curl "http://127.0.0.1:80"
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
minikube也提供了可视化的Dashboard:
minikube dashboard --url
http://127.0.0.1:59352/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/
在浏览器中打开上述连接,可以进入Web版的Dashboard,如下图所示:
至此,你已经通过在minikube上的实战演练,掌握了kubernetes的基本用法。
在实际生产环境中,建议你搭建真实的分布式集群,不要使用minikube,我将在后续章节,介绍高可用k8s集群的部署。
搭建Kubernetes集群
在本章的前几节,我们在minikube集群上,实战了很多内容,是时候搭建真正的集群了。
本节,我们将借助kubeadm的帮助,搭建准生产级的k8s集群。
关于"准生产"的含义,我们先放下不表。
以下的集群搭建假设你使用Ubuntu的发行版,20.04,需要3台机器(可以是物理服务器,也可以是虚拟机,以下我们都简称机器)。
如果你不是Ubuntu,请自行替换部分安装命令,很简单。
1 调整系统参数
我们需要调整一些系统参数,以方便后续集群的搭建。
lsmod | grep br_netfilter
br_netfilter
sysctl net.bridge.bridge-nf-call-iptables
net.bridge.bridge-nf-call-iptables = 1
sysctl net.bridge.bridge-nf-call-ip6tables
net.bridge.bridge-nf-call-ip6tables = 1
swapoff -a
说明如下:
-
需要开启netfilter
-
调整对应内核参数如上
-
关闭swap,建议你同步修改fstab(保证重启后生效)
2 安装Docker
首先安装Docker
sudo apt-get update && sudo apt-get install -y apt-transport-https
sudo apt install -y docker.io
sudo systemctl start docker
sudo systemctl enable docker
接着,调整Docker默认组权限
# 将自己添加到docker组中
sudo groupadd docker
sudo gpasswd -a ${USER} docker
# 重启后重新load下权限
sudo service docker restart
newgrp - docker
最后,调整以下Docker的默认参数:
sudo vim /etc/docker/daemon.json
{
"registry-mirrors": [ "https://registry.docker-cn.com" ],
"exec-opts": ["native.cgroupdriver=systemd"]
}
以上调整包含两部分:
-
换成了docker的国内源,稳定但是速度并不快
-
替换了cgroups驱动,这个主要是Ubuntu等几个发行版的问题,可以参考这篇文章
以上操作完成后,我们重启Docker服务:
sudo service docker restart
3 安装Kubernetes相关二进制文件
由于众所周知的原因,直接使用Google的apt仓库是不行的,我们直接用aliyun的(暂时没有focal的,这里沿用xenial的)。
sudo /etc/apt/source/xxx
deb http://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
sudo apt-get update
如果提示错误,自行import一下GPG key即可,请自行搜索。
sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni
最后启动
sudo systemctl status kubelet
如果是Run的状态是正常的,如果是Stopped,请查看日志,自行解决。
4 安装Kubernetes所需要的镜像文件
Kubernets在启动时,会拉取大量了gcr.io上的容器镜像。
由于众所周知的原因,这些国内是无法访问的。
我们可以先将镜像离线下载到本地,再继续安装。
先看一眼需要哪些镜像,这里需要设定版本,我们用当前最新版1.22.1:
kubeadm config images list --kubernetes-version v1.22.1
k8s.gcr.io/kube-apiserver:v1.22.1
k8s.gcr.io/kube-controller-manager:v1.22.1
k8s.gcr.io/kube-scheduler:v1.22.1
k8s.gcr.io/kube-proxy:v1.22.1
k8s.gcr.io/pause:3.5
k8s.gcr.io/etcd:3.5.0-0
k8s.gcr.io/coredns/coredns:v1.8.4
这里我们使用阿里云的国内镜像,我这里使用awk的方式提供执行命令,你可以将输出结果直接黏贴到shell中执行。
第一步,拉取镜像:
kubeadm config images list --kubernetes-version v1.22.1 | awk -F "/" '{print "docker pull registry.aliyuncs.com/google_containers/"$NF""}'
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.22.1
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.22.1
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.22.1
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.22.1
docker pull registry.aliyuncs.com/google_containers/pause:3.5
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.0-0
# 最后这个要稍微特殊处理下
docker pull coredns/coredns:1.8.4
第二步,镜像tag重命名:(原因:我们换了镜像,一些前缀和tag会不对):
kubeadm config images list --kubernetes-version v1.22.1 | awk -F "/" '{print "docker tag registry.aliyuncs.com/google_containers/"$2" k8s.gcr.io/"$NF""}'
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.22.1 k8s.gcr.io/kube-apiserver:v1.22.1
docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.22.1 k8s.gcr.io/kube-controller-manager:v1.22.1
docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.22.1 k8s.gcr.io/kube-scheduler:v1.22.1
docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.22.1 k8s.gcr.io/kube-proxy:v1.22.1
docker tag registry.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
docker tag registry.aliyuncs.com/google_containers/etcd:3.5.0-0 k8s.gcr.io/etcd:3.5.0-0
# 特殊处理
docker tag coredns/coredns:1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
第三步,删除重命名之前的废弃tag:
kubeadm config images list --kubernetes-version v1.22.1 | awk -F "/" '{print "docker rmi registry.aliyuncs.com/google_containers/"$2""}'
docker rmi registry.aliyuncs.com/google_containers/kube-apiserver:v1.22.1
docker rmi registry.aliyuncs.com/google_containers/kube-controller-manager:v1.22.1
docker rmi registry.aliyuncs.com/google_containers/kube-scheduler:v1.22.1
docker rmi registry.aliyuncs.com/google_containers/kube-proxy:v1.22.1
docker rmi registry.aliyuncs.com/google_containers/pause:3.5
docker rmi registry.aliyuncs.com/google_containers/etcd:3.5.0-0
# 特殊处理
docker rmi coredns/coredns:1.8.4
最后,让我们确认下本地有哪些镜像:
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.22.1 f30469a2491a 3 weeks ago 128MB
k8s.gcr.io/kube-proxy v1.22.1 36c4ebbc9d97 3 weeks ago 104MB
k8s.gcr.io/kube-controller-manager v1.22.1 6e002eb89a88 3 weeks ago 122MB
k8s.gcr.io/kube-scheduler v1.22.1 aca5ededae9c 3 weeks ago 52.7MB
k8s.gcr.io/etcd 3.5.0-0 004811815584 3 months ago 295MB
k8s.gcr.io/coredns/coredns v1.8.4 8d147537fb7d 3 months ago 47.6MB
k8s.gcr.io/pause 3.5 ed210e3e4a5b 6 months ago 683kB
5 初始化集群
上述准备操作,需要在3台机器都执行。
当准备妥当后,我们要初始化集群了,选择一台机器做为主节点(Master),我们假设这台的地址是192.168.6.91:
sudo kubeadm init --kubernetes-version v1.22.1 --apiserver-advertise-address=192.168.6.91 --pod-network-cidr=10.6.0.0/16
上述的参数要解释下:
-
集群版本1.22.1
-
api主控服务器的地址192.168.6.91
-
pod网络的地址是10.6.0.0/16,这里强制指定了,后面我们设定网络插件时会用。
上述执行成功后,会有一个提示,类似如下,复制出来,后面要用到:
...
kubeadm join 10.3.96.3:6443 --token w1zh7w.l6chof87e113m8u7 --discovery-token-ca-cert-hash sha256:5c010cce4123abcf6c48fd98f8559b33c1efc80742270d7493035a92adf53602
...
我们初始化配置:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果一切顺利,我们安装网络插件,这里以Weave为例:
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
至此,主节点(Master)就配置完成了,我们继续配置其他节点。
6 其他节点加入集群
在其他节点上,执行前面记录的kubeadm join命令,都执行后,等一会,回到Master节点上,集群已经ready:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s1 Ready master 2m v1.14.3
k8s2 Ready <none> 40s v1.14.3
k8s3 Ready <none> 28s v1.14.3
7 测试和重置
我们部署一个nginx的pod
kubectl run nginx --image=nginx
在某一台机器上测试:
kubectl describe pod nginx | grep ip
10.6.0.194
curl "10.6.0.194"
成功!
至此,我们完成了“准生产集群”的搭建,这里准生产的意思是:他已经具备了集群特性,但还不具备高可用的能力,我们会在下一节介绍Kubernetes集群的高可用。
搭建Kubernetes高可用集群
在上一节,我们介绍了Kubernetes集群的搭建,我们说这是一个“准生产”级别的集群。
原因是,他不支持高可用。
设想下,假设Master节点挂掉,会出现什么情况?
由于只有一个主节点,所以集群会直接瘫痪。
本节,我们将借助KeepAlived搭建一个高可用的集群。
我们需要4台机器(物理机 or 虚拟机均可)。假设,这4台机器的IP分别为:
-
h1:192.168.1.12
-
h2:192.168.1.10
-
h3:192.168.1.9
-
h4:192.168.1.16
同时我们需要一个不冲突的VIP(Virtual IP),当发生主备切换时,KeepAlive会让VIP从主Master切换到备Master上。
注意,如果你使用云主机,由于网络安全性的原因,是无法自由使用云主机的,需要单独HAVIP(高可用VIP),申请地址如下:[腾讯云](腾讯云运营活动 - 腾讯云),[阿里云](阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台)。
这里假设你已经有了可用的VIP,其地址为192.168.1.8。
1 部署KeepAlived
这里我们选用h1、h2做为Master节点的主机和备机。
则需要在这两台机器上安装keepalived
yum install -y keepalived
两台机器的配置文件分别如下:
h1:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_apiserver {
script "</dev/tcp/127.0.0.1/6443"
interval 1
weight -2
}
vrrp_instance VI-kube-master {
state MASTER # 定义节点角色
interface eth0 # 网卡名称
virtual_router_id 68
priority 100
dont_track_primary
advert_int 3
authentication {
auth_type PASS
auth_pass mypass
}
unicast_src_ip 192.168.1.12 #当前ECS的ip
unicast_peer {
192.168.1.10 #对端ECS的ip
}
virtual_ipaddress {
192.168.1.8 # havip
}
track_script {
check_apiserver
}
}
h2:
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_apiserver {
script "</dev/tcp/127.0.0.1/6443"
interval 1
weight -2
}
vrrp_instance VI-kube-master {
state BACKUP # 定义节点角色
interface eth0 # 网卡名称
virtual_router_id 68
priority 99
dont_track_primary
advert_int 3
unicast_src_ip 192.168.1.10 #当前ECS的ip
authentication {
auth_type PASS
auth_pass mypass
}
unicast_peer {
192.168.1.12 #对端ECS的ip
}
virtual_ipaddress {
192.168.1.8 # havip
}
track_script {
check_apiserver
}
}
解释如下:
-
h1做为主机,state是MASTER,h2备机,状态为BACKUP
-
h1和h2通过unicast方式发现,互相设置了unicast_peer为对方的IP
-
virtual_ipaddress中设置了相同的VIP地址
-
检查是否可用使用了check_apiserver这个方法,他会检查TCP端口的6443是否开启。这实际是Kubernetes的API Server地址。
配置完成后,记得重启两台机器的keepalived服务。
systemctl enable keepalived
service keepalived start
2 准备Kubernetes环境
这里与上一节的准备工作完全一致,不再赘述。
请参考《搭建Kubernetes集群》一节中的步骤2~4。
注意这里是4台机器都要安装。
3 启动主节点
我们首先在h1上操作,命令如下:
kubeadm init --kubernetes-version v1.22.1 --control-plane-endpoint=192.168.1.8:6443 --apiserver-advertise-address=192.168.1.8 --pod-network-cidr=10.6.0.0/16 --upload-certs
说明如下:
-
这里的control-plane-endpoint / apiserver-advertise-address填写的是VIP地址,会被VIP转发流量到h1 or h2上(取决于谁的状态是MASTER)
-
upload-certs:自动上传证书,高可用集群需要
执行成功后,结果如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.1.8:6443 --token ydkjeh.zu9qthjssivlyrqy \
--discovery-token-ca-cert-hash sha256:87d31b2fb17002f23dce01054c4877b133c15e3a1ed639e8f63b247f61609f8d \
--control-plane --certificate-key 23474fd4262f1bf8849c5cea160fd3309621f79460266c43dfca1d7cc390f1af
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.8:6443 --token ydkjeh.zu9qthjssivlyrqy \
--discovery-token-ca-cert-hash sha256:87d31b2fb17002f23dce01054c4877b133c15e3a1ed639e8f63b247f61609f8d
上述有两个join命令,长的那个是master用的,短的是slave用的。
我们将h2和h3也以master方式加入(因为Kubernetes要求至少有两个Master存活,才能正常工作),也即在h2和h3上执行:
kubeadm join 192.168.1.8:6443 --token ydkjeh.zu9qthjssivlyrqy \
--discovery-token-ca-cert-hash sha256:87d31b2fb17002f23dce01054c4877b133c15e3a1ed639e8f63b247f61609f8d \
--control-plane --certificate-key 23474fd4262f1bf8849c5cea160fd3309621f79460266c43dfca1d7cc390f1af
4 启动普通节点
在h4上以slave身份加入
kubeadm join 192.168.1.8:6443 --token ydkjeh.zu9qthjssivlyrqy \
--discovery-token-ca-cert-hash sha256:87d31b2fb17002f23dce01054c4877b133c15e3a1ed639e8f63b247f61609f8d
5 安装网络插件
回到h1 or h2 or h3上执行(因为他们三个都是Master):
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 修改cidr匹配后
kubectl apply -f ./kube-flannel.yml
6 测试高可用
我们对h1执行关机
poweroff
然后查看h2上的keepalived日志,可以观察到切换:
9月 18 7:59:28 h2 Keepalived_vrrp[18653]: VRRP_Instance(VI-kube-master) Changing effective priority from 97 to 99
9月 18 8:03:22 h2 Keepalived_vrrp[18653]: VRRP_Instance(VI-kube-master) Transition to MASTER STATE
9月 18 8:03:25 h2 Keepalived_vrrp[18653]: VRRP_Instance(VI-kube-master) Entering MASTER STATE
9月 18 8:03:25 h2 Keepalived_vrrp[18653]: VRRP_Instance(VI-kube-master) setting protocol VIPs.
然后立即在h2上查看集群状态,全部正常:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
h1 Ready control-plane,master 6m16s v1.22.2
h2 Ready control-plane,master 5m51s v1.22.2
h3 Ready control-plane,master 4m52s v1.22.2
h4 Ready <none> 3m38s v1.22.2
再等一会后,发现h1挂掉了:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
h1 NotReady control-plane,master 6m16s v1.22.2
h2 Ready control-plane,master 5m51s v1.22.2
h3 Ready control-plane,master 4m52s v1.22.2
h4 Ready <none> 3m38s v1.22.2
至此,我们实现了Master的高可用!
7 测试高可用恢复
我们重启启动h1,稍等一会,发现一切正常!
kubectl get nodes
NAME STATUS ROLES AGE VERSION
h1 Ready control-plane,master 8m14s v1.22.2
h2 Ready control-plane,master 7m49s v1.22.2
h3 Ready control-plane,master 6m50s v1.22.2
h4 Ready <none> 5m36s v1.22.2
至此,你应该已经熟悉了Kubernetes集群高可用的搭建步骤。
这里提一个问题:我们将h1、h2、h3都是Master,但是只在h1和h2上设置了KeepAlived。
-
如果h3挂掉后,集群能正常工作么?
-
如果h3挂掉后,h2也挂掉了,集群还能正常工作么?
通过ingress暴露内部服务
在kubernetes集群中,有一个常见的需求:如何将内部服务暴露出来,供外部访问?
在快速入门Kubernetes一节中,我们使用了Service(Load Balancer)的方式,对外暴露了nginx服务。试想:如果我们有100个内部Deployment,能够使用LB的方式,对外暴露么?
如果你还有印象,LB的对外暴露,要占用一个独立的端口,当需要暴露的服务增多时,光是端口的占用和分配,就已经是一个头疼的问题了。
实际上,Kubernetes为我们提供了三种暴露内部服务的机制:
-
NodePort:在Kubernetes的所有节点上,开放一个端口,转发到内部具体的service上,与LoadBalancer相比,它不会绑定外网IP,多用于临时用途(如debug)
-
LoadBalancer:每个服务可以绑定一个外网IP、端口,当需要暴露的服务不多时,这是官方推荐的选择。
-
Ingress:像一个“智能路由器”,对外只暴露一个IP/端口,可以根据路径、头信息等变量,自动转发到内部的多个不同服务上。
本节,我们将介绍两种不同的Ingress,来实现“暴露内部多组服务这个需求”。
七层ingress
首先,我们来看一下Nginx Ingress Controller,这是一款较早退出的Ingress方案,基于Nginx实现了应用层(http)协议的暴露。
我们在上一节的基础上,添加另一组deployment:
kubectl create deployment my-httpd --image=httpd:2.4
kubectl scale deployment my-httpd --replicas=3
同时,我们将之前创建的ngxin,也缩容为3:
kubectl scale deployment my-nginx --replicas=3
kubectl get pods
NAME READY STATUS RESTARTS AGE
my-httpd-84bdf5b4d9-jjvwv 1/1 Running 0 46s
my-httpd-84bdf5b4d9-n269p 1/1 Running 0 16s
my-httpd-84bdf5b4d9-rw2kk 1/1 Running 0 16s
my-nginx-7bc876dc4b-226g9 1/1 Running 2 4h46m
my-nginx-7bc876dc4b-872v2 1/1 Running 2 4h46m
my-nginx-7bc876dc4b-fzr8s 1/1 Running 2 4h46m
接着,我们创建上述两个deployment的service:
kubectl expose deployment/my-nginx --port=80
kubectl expose deployment/my-httpd --port=80
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9m16s
my-httpd ClusterIP 10.102.22.9 <none> 80/TCP 4s
my-nginx ClusterIP 10.109.10.111 <none> 80/TCP 9s
在配置ingress之前,我们首先要启用ingress:
minikube addons enable ingress
如果你使用的是MacOS,可能会报错,此时需要一些额外的配置,请参考这个帖子。
接下来,我们创建ingress.yaml文件:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: homs-ingress
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
tls:
- hosts:
- homs.coder4.com
secretName: homs-secret
rules:
- host: homs.coder4.com
http:
paths:
- path: /my-nginx/?(.*)
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
- path: /my-httpd/?(.*)
pathType: Prefix
backend:
service:
name: my-httpd
port:
number: 80
解释一下:
-
我们定义了Nginx的Ingress,并使用了转发前清除前缀(rewrite-target配置)
-
定义了两个不同的前缀my-nginx和my-httpd,通过前缀指向内部服务
-
同时支持了http和https解析,但https是自签证书,所以后面我们只用http
然后创建它:
kubectl apply -f ./ingress.yaml
稍等一会,ingress的IP分配成功后如下所示:
kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
homs-ingress <none> homs.coder4.com 192.168.64.3 80, 443 34s
如上所示,“192.168.64.3”就是分配的ingressIP,但我们需要用DNS访问它,这里,我使用nip.io这个黑魔法来避免需要修改hosts的问题,即修改上述yaml中的host为“192.168.64.3.nip.io”。
我们登录到minikube集群内部,尝试访问:
curl -kL "http://192.168.64.3.nip.io/my-httpd"
<html><body><h1>It works!</h1></body></html>
curl -kL "http://192.168.64.3.nip.io/my-nginx"
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
如上,我们成功的用prefix的路径(my-nginx / my-httpd),访问了两个不同的内部service!
修改转发前缀
在上述的配置中,我们实现了多服务的转发,但准法后的location存在一些问题,我们换一个service验证一下:
kubectl create deployment service1 --image=mendhak/http-https-echo:23
kubectl create deployment service2 --image=mendhak/http-https-echo:23
对外暴露服务:
kubectl expose deployment/service1 --port=8080
kubectl expose deployment/service2 --port=808
修改一下ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: homs-ingress
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
tls:
- hosts:
- homs.coder4.com
secretName: homs-secret
rules:
- host: homs.coder4.com
http:
paths:
- path: /service1/?(.*)
pathType: Prefix
backend:
service:
name: service1
port:
number: 8080
- path: /service2/?(.*)
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
登录到minikube后curl:
{
"path": "/",
"headers": {
"host": "192.168.64.11.nip.io",
"x-request-id": "7a00b30a5d4fd4c084d2bcfbfd44f636",
"x-real-ip": "192.168.64.11",
"x-forwarded-for": "192.168.64.11",
"x-forwarded-host": "192.168.64.11.nip.io",
"x-forwarded-port": "443",
"x-forwarded-proto": "https",
"x-scheme": "https",
"user-agent": "curl/7.76.0",
"accept": "*/*"
},
"method": "GET",
"body": "",
"fresh": false,
"hostname": "192.168.64.11.nip.io",
"ip": "192.168.64.11",
"ips": [
"192.168.64.11"
],
"protocol": "https",
"query": {},
"subdomains": [
"11",
"64",
"168",
"192"
],
"xhr": false,
"os": {
"hostname": "service2-5686d4f68c-4vz7d"
},
"connection": {}
}
观察上述输出,发现转发后的location被重定向了,如果我们的服务想收到完整的请求,如何实现呢?
我们可以修改ingress配置,在路径上添加一段分组匹配,如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: homs-ingress
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1$2
nginx.ingress.kubernetes.io/app-root: /service1
spec:
tls:
- hosts:
- homs.coder4.com
secretName: homs-secret
rules:
- host: 192.168.64.11.nip.io
http:
paths:
- path: /(service1/?)(.*)
pathType: Prefix
backend:
service:
name: service1
port:
number: 8080
- path: /(service2/?)(.*)
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
生效后,再次curl:
curl -kL "http://192.168.64.11.nip.io/service2"
{
"path": "/service2",
"headers": {
"host": "192.168.64.11.nip.io",
"x-request-id": "b5759cf6f47d0ed713142178ddea4f96",
"x-real-ip": "192.168.64.11",
"x-forwarded-for": "192.168.64.11",
"x-forwarded-host": "192.168.64.11.nip.io",
"x-forwarded-port": "443",
"x-forwarded-proto": "https",
"x-scheme": "https",
"user-agent": "curl/7.76.0",
"accept": "*/*"
},
"method": "GET",
"body": "",
"fresh": false,
"hostname": "192.168.64.11.nip.io",
"ip": "192.168.64.11",
"ips": [
"192.168.64.11"
],
"protocol": "https",
"query": {},
"subdomains": [
"11",
"64",
"168",
"192"
],
"xhr": false,
"os": {
"hostname": "service2-5686d4f68c-4vz7d"
},
"connection": {}
}
成功!
Nginx Ingress也支持通过不同的Host来区分不同Service,也支持nginx的部分自定义配置,推荐你阅读[官方ingress例子](Introduction - NGINX Ingress Controller)。
四层ingress
在上述两个例子中,我们实现了7层http协议的暴露 & 转发,ingress也支持4层的TCP协议。
为了防止影响,我们首先重置集群,并重新启用ingress。
minikube delete
minikube start
minikube addons enable ingress
接着,创建一个TCP的服务,我们以redis为例:
kubectl create deployment redis --image=redis:6
kubectl expose deployment/redis --port=6379
接着,我们创建映射关系,TCP的ingress是通过ConfigMap额外配置的。
apiVersion: v1
kind: ConfigMap
metadata:
name: tcp-services
namespace: ingress-nginx
data:
6379: "default/redis:6379"
最后,我们将端口映射,修改到ingress上:
kubectl edit service -n ingress-nginx ingress-nginx-controller
在规则处添加如下代码:
- name: redis
port: 6379
protocol: TCP
targetPort: 6379
这里我们并没有填写nodePort,这是系统会自动分配的,不用我们手动处理。
保存成功后,我们尝试通过ingress的端口连接:
kubectl get services --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 35m
default redis ClusterIP 10.109.20.237 <none> 6379/TCP 33m
ingress-nginx ingress-nginx-controller NodePort 10.110.48.51 <none> 80:30958/TCP,443:32737/TCP,6379:32765/TCP 34m
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.103.12.249 <none> 443/TCP 34m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 35m
我们本地使用redis连接:
redis-cli -h $(minikube ip) -p 32765
> info
info
# Server
redis_version:6.2.6
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:1527eab61b27d3bf
redis_mode:standalone
os:Linux 4.19.182 x86_64
arch_bits:64
multiplexing_api:epoll
.....
成功!
至此,我们成功使用Ingress暴露了内部的TCP端口。
如果你仔细对比HTTP和TCP的Ingress,不难发现:
-
HTTP的Ingress更加实用,可以通过不同Host甚至不同Path,区分多个内部Service
-
TCP的Ingress相对来说,比较"凑合",虽然能够工作,但配置繁琐、还需要耗费多个端口,并不方便。
因此,再实际工作中,如果想从k8s集群外访问集群内的TCP服务,多采用网络打通的方式进行,我们将在后续章节介绍这一功能。
持续交付流水线
持续交付是敏捷开发的一种最佳实践,代码发生变更后,可以自动进行持续集成,测试,并部署到线上系统中。
持续交付贯穿了软件的开发、测试、发布等全生命周期,也是微服务架构的基石。
本节将借助Jenkins + 容器技术,打造自己的流水线,脉络是:
-
Jenkins的部署、插件、基本用法
-
Jenkins的Agent定制
-
基于Jenkins的交付流水线
-
交付流水线的改进
经过本章的实战,你将获得一套生产级别的持续交付流水线。
Jenkins搭建入门
Jenkins是一款开源、强大的持续集成工具,其前身是Hudson(商用软件)。
本节将介绍Jenkins的搭建。从架构上理解,Jenklins由两类角色组成:
-
Controller:主控节点,负责管理、配置工作,也称作Master节点。
-
Agent:执行具体作业的工作节点,也称作Slave节点,或者Executor节点。
严格来说,Master节点也可以执行具体作业,但是处于安全性考虑,不建议这样做。
Jeknins的启动与初始配置
首先启动Controller节点:
#!/bin/bash
NAME="jenkins"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/jenkins"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-v $VOLUME:/var/jenkins_home \
-p 8080:8080 \
-p 50000:50000 \
--detach \
--restart always \
jenkins/jenkins:lts-jdk11
如上所示,我们启动了jenkins的主控节点,并对外暴露了8080、5000两个端口。
我们在浏览器中打开如下链接:http://127.0.0.1:8080/
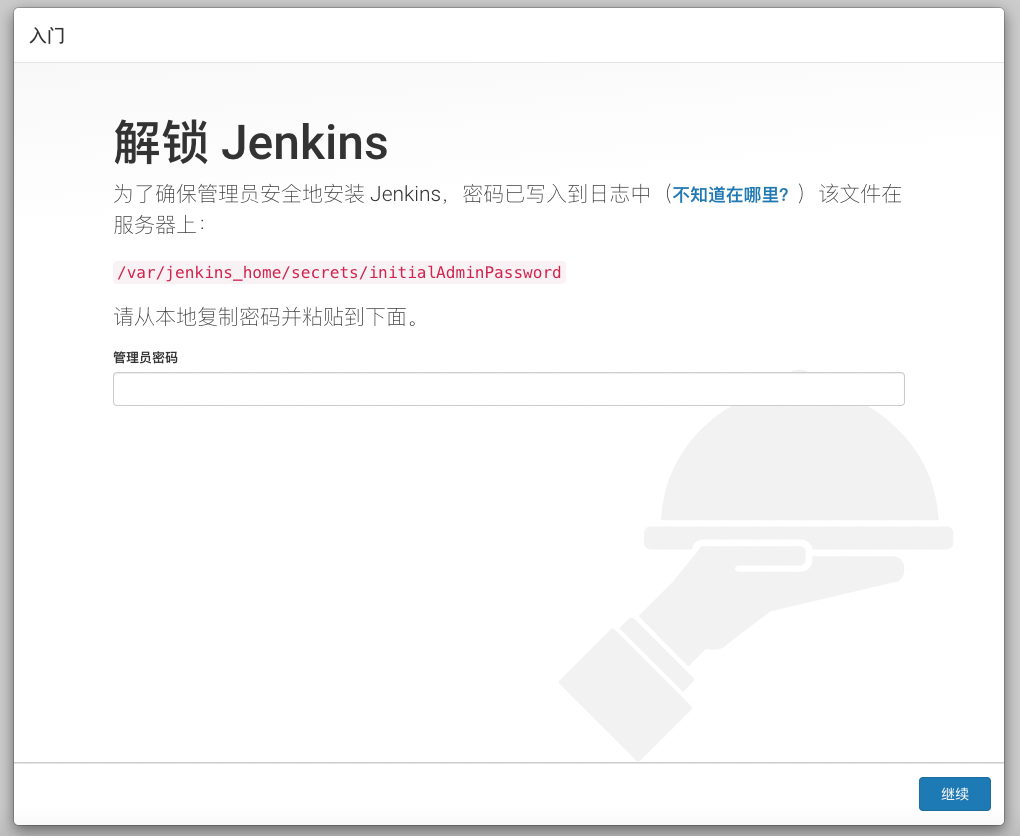
第一次启动会进行初始化,要求输入密码,我们使用如下命令查看:
docker logs -f jenkins
....
*************************************************************
*************************************************************
*************************************************************
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
9169c97282d64545b36bc96cf7c1aaab
This may also be found at: /var/jenkins_home/secrets/initialAdminPassword
*************************************************************
*************************************************************
*************************************************************
2021-11-04 03:15:53.502+0000 [id=49] INFO h.m.DownloadService$Downloadable#load: Obtained the updated data file for hudson.tasks.Maven.MavenInstaller
2021-11-04 03:15:53.502+0000 [id=49] INFO hudson.util.Retrier#start: Performed the action check updates server successfully at the attempt #1
2021-11-04 03:15:53.517+0000 [id=49] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$0: Finished Download metadata. 36,815 ms码
如上中间部分,即初始密码。
输入初始密码后,会要求安装创建,建议至少安装下述插件:
-
Gradle:用于Java项目的打包和编译
-
Pipeline:用户开发流水线作业
-
Git:用于代码拉取
-
SSH Build Agents
-
Kubernetes:用于在Kubernetes集群上启动Slave节点
-
Kubernetes CLI:用于执行远程Kubernetes的二进制文件
安装完插件后,需要创建初始管理员账号。
Jeknins的Agent节点配置
启动Controller节点后,我们着手配置Slave节点,这里也有多种选项:
-
启动固定数量的Slave节点
-
按需启动,用完释放
-
上述两种方案的混合
考虑到并发性、资源利用率,我们选用方案2:在Kubernetes集群上,按需启动Slave容器,执行完毕后销毁。
首先,我们需要登录到Kubernetes集群的Master节点上,查看已有的证书信息。
cd ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: /Users/coder4/.minikube/ca.crt
extensions:
- extension:
last-update: Thu, 04 Nov 2021 11:23:17 CST
provider: minikube.sigs.k8s.io
version: v1.22.0
name: cluster_info
server: https://127.0.0.1:52058
name: minikube
contexts:
- context:
cluster: minikube
extensions:
- extension:
last-update: Thu, 04 Nov 2021 11:23:17 CST
provider: minikube.sigs.k8s.io
version: v1.22.0
name: context_info
namespace: default
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /Users/coder4/.minikube/profiles/minikube/client.crt
client-key: /Users/coder4/.minikube/profiles/minikube/client.key
如上,共包含了3个证书/密钥:ca.crt、client.crt、client.key。
我们使用他们创建新的凭据,供Jenkins使用:
openssl pkcs12 -export -out ./kube-jenkins.pfx -inkey ./client.key -in ./client.crt -certfile ./ca.crt
上述创建过程会要求输入密码,请记牢后续会用到。
此外,上述文件中的ca.crt后面会再次用到。
在Jenkins上配置Kubernetes集群之前,我们假设以下信息:
-
10.1.172.136:Jenkins所在的物理机节点
-
https://127.0.0.1:52058:Kubernetes集群的api server地址
由于我当前使用的minikube,不难发现,minikube的api server只在本地开了端口,并没有监听到物理机上,因此网段是不通的,所以我们先使用socat进行端口映射。
socat TCP4-LISTEN:6443,fork TCP4:127.0.0.1:52058
如上,经过映射后,所有打到本机的公网IP(10.1.172.136)、端口6443上的流量,会被自动转发到52058上。
接下来,我们着手在Jenkins上添加Kubernetes的集群配置。
Manage Jenkins -> Manage Nodes and Clouds -> Configure Clouds -> Add a new cloud -> Kubernetes
截图如下:
其中核心配置如下:
-
名称:自选必填,这里选了kubernetes
-
Kuberenetes地址:https://10.1.172.136:6443
-
Kubernetes 服务证书 key:输入上文中ca.crt中的信息,注意换行问题。
-
凭据:上传上述生成的kube-jenkins.pfx,同时输入密码
-
Jenkins地址:http://10.1.172.136:8080
上述天禧后,点击"连接测试",如果一切正常,你会发现如下报错:

这是因为我们经过转发后,host与证书中的并不匹配。
我们修改下Jenkins的docker启动脚本,添加hosts参数:
--add-host kubernetes:10.1.172.136
重启Jenkins后,将上述位置的"Kuberenetes地址"修改为"https://kubernetes:6443",再次重试连接,一切会成功。
记得保存所有配置。
测试任务
我们配置一个测试任务:
新建任务 -> 流水线
代码如下:
podTemplate {
node(POD_LABEL) {
stage('Run shell') {
sh 'echo hello world'
}
}
}
保存后,点击"立即构建",运行结果如下:
Started by user admin
[Pipeline] Start of Pipeline
[Pipeline] podTemplate
[Pipeline] {
[Pipeline] node
Created Pod: kubernetes default/test-4-xsc01-4292c-4rkrz
[Normal][default/test-4-xsc01-4292c-4rkrz][Scheduled] Successfully assigned default/test-4-xsc01-4292c-4rkrz to minikube
[Normal][default/test-4-xsc01-4292c-4rkrz][Pulled] Container image "jenkins/inbound-agent:4.3-4-jdk11" already present on machine
[Normal][default/test-4-xsc01-4292c-4rkrz][Created] Created container jnlp
[Normal][default/test-4-xsc01-4292c-4rkrz][Started] Started container jnlp
Agent test-4-xsc01-4292c-4rkrz is provisioned from template test_4-xsc01-4292c
---
apiVersion: "v1"
kind: "Pod"
metadata:
annotations:
buildUrl: "http://10.1.172.136:8080/job/test/4/"
runUrl: "job/test/4/"
labels:
jenkins: "slave"
jenkins/label-digest: "802a637918cdcb746f1931e3fa50c8f991b59203"
jenkins/label: "test_4-xsc01"
name: "test-4-xsc01-4292c-4rkrz"
spec:
containers:
- env:
- name: "JENKINS_SECRET"
value: "********"
- name: "JENKINS_AGENT_NAME"
value: "test-4-xsc01-4292c-4rkrz"
- name: "JENKINS_NAME"
value: "test-4-xsc01-4292c-4rkrz"
- name: "JENKINS_AGENT_WORKDIR"
value: "/home/jenkins/agent"
- name: "JENKINS_URL"
value: "http://10.1.172.136:8080/"
image: "jenkins/inbound-agent:4.3-4-jdk11"
name: "jnlp"
resources:
limits: {}
requests:
memory: "256Mi"
cpu: "100m"
volumeMounts:
- mountPath: "/home/jenkins/agent"
name: "workspace-volume"
readOnly: false
nodeSelector:
kubernetes.io/os: "linux"
restartPolicy: "Never"
volumes:
- emptyDir:
medium: ""
name: "workspace-volume"
Running on test-4-xsc01-4292c-4rkrz in /home/jenkins/agent/workspace/test
[Pipeline] {
[Pipeline] stage
[Pipeline] { (Run shell)
[Pipeline] sh
+ echo hello world
hello world
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
Finished: SUCCESS
至此,我们已经成功配置了基础的Jenkins,并成功在Kubernetes集群上执行了一次构建任务。
Jenkins定制Agent
上一节,我们实现了最简单的打包任务,在这一节,我们将定制所需的打包环境,为CD流水线做准备。
手动连接Agent
在上一节,我们使用了Kubernetes集群启动新的Slave节点,你可以沿着这条路,继续集成所需的环境,不再展开。
在本节,我们将切换另一种思路,使用手动启动&连接的方式。
首先,在Jenkins中添加一个Agent,路径是:Manage Jenkins -> Manage Nodes and Clouds -> New Node。
关键参数如下:
name:自选,这里e1
Number of executors:在这台机器上的并发执行任务数,这里选默认的2
Remote root directory:默认执行目录,这里选/home/jenkins/ateng
Labels:自选,这里executor,可以用它对Executor分组(如测试、线上等)
Launch method:Launch agent by connecting it to the master,即我们手动连接
保存后,点击进去后,能看到如下提示:
Run from agent command line:
java -jar agent.jar -jnlpUrl http://127.0.0.1:8080/computer/e1/jenkins-agent.jnlp -secret b057970bf978f53a8f945d470ac644e44c945e4b7259b216f703dedb95d0cac9 -workDir "/home/jenkins/agent"
Run from agent command line, with the secret stored in a file:
echo b057970bf978f53a8f945d470ac644e44c945e4b7259b216f703dedb95d0cac9 > secret-file
java -jar agent.jar -jnlpUrl http://127.0.0.1:8080/computer/e1/jenkins-agent.jnlp -secret @secret-file -workDir "/home/jenkins/agent"
如上所示,我们需要用上述的Secret来连接Controller(主控)节点。
我们通过Docker启动Executor节点,如下:
#!/bin/bash
NAME="jenkins_e1"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--name $NAME \
--env PUID=$PUID \
--env PGID=$PGID \
--detach \
--init jenkins/inbound-agent \
-workDir=/home/jenkins/agent \
-url http://10.1.172.136:8080 \
b057970bf978f53a8f945d470ac644e44c945e4b7259b216f703dedb95d0cac9 \
e1
温馨提示:上述的workDir需要与Jenkins中的配置保持一致。
当启动成功后,能看到节点上线了,如下图所示:
为了不调度到Controller节点,我们可以将其上的执行数量设置为0。
随后,我们尝试修改任务,如下所示:
pipeline {
agent any
stages {
stage('Test') {
steps {
sh 'echo hello world'
}
}
}
}
如果一起顺利,其会成功地在e1完成执行!
定制Executor的环境
从上述例子中,不难理解:真正的打包任务,是在Executor中执行的。
如果我们的打包流程需要用到git、Java、Gradle、Kubernetes的话,我们也需要将这些集成到Executor中。
我们基于Jenkins的官方基础镜像进行定制,Dockerfile如下:
FROM jenkins/inbound-agent:latest-jdk8
ENV GRADLE_VERSION=7.2
ENV K8S_VERSION=v1.22.3
# tool
USER root
RUN apt-get update && \
apt-get install -y curl unzip docker-ce docker-ce-cli && \
apt-get clean
# gradle
RUN curl -skL -o /tmp/gradle-bin.zip https://services.gradle.org/distributions/gradle-$GRADLE_VERSION-bin.zip && \
mkdir -p /opt/gradle && \
unzip -q /tmp/gradle-bin.zip -d /opt/gradle && \
ln -sf /opt/gradle/gradle-$GRADLE_VERSION/bin/gradle /usr/local/bin/gradle
RUN chown -R 1001:0 /opt/gradle && \
chmod -R g+rw /opt/gradle
# kubectl
RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/$K8S_VERSION/bin/linux/amd64/kubectl
RUN chmod +x ./kubectl
RUN mv ./kubectl /usr/local/bin
USER jenkins
如上所示:
- 我们基于inbound-agent进行定制,这是官方的默认的Agent基础镜像
- 随后,我们使用apt安装curl、unzip等基础工具
- 接着,我们安装gradle、kubectl等二进制文件
- 最后恢复默认的运行环境
制作镜像
docker build -t "coder4/jenkins-my-agent" .
制作时间会比较长
再次打包
pipeline {
agent {label 'executor'}
stages {
stage('git') {
steps {
sh "echo todo"
}
}
stage('gradle') {
steps {
sh "gradle -v"
}
}
stage('k8s') {
steps {
withKubeConfig([credentialsId: "60a8e9d2-0212-4ff4-aa98-f46fced97121",serverUrl: "https://kubernetes:6443"]) {
sh "kubectl get nodes"
}
}
}
}
}
需要指出的是:上述'k8s'阶段,使用的凭据,是我们在 Jenkins搭建入门一节中生成的证书+凭据。
运行结果
Started by user admin
[Pipeline] Start of Pipeline
[Pipeline] node
Running on e1 in /home/jenkins/agent/workspace/test
[Pipeline] {
[Pipeline] stage
[Pipeline] { (git)
[Pipeline] sh
+ git version
git version 2.30.2
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (gradle)
[Pipeline] sh
+ gradle -v
Welcome to Gradle 7.2!
Here are the highlights of this release:
- Toolchain support for Scala
- More cache hits when Java source files have platform-specific line endings
- More resilient remote HTTP build cache behavior
For more details see https://docs.gradle.org/7.2/release-notes.html
------------------------------------------------------------
Gradle 7.2
------------------------------------------------------------
Build time: 2021-08-17 09:59:03 UTC
Revision: a773786b58bb28710e3dc96c4d1a7063628952ad
Kotlin: 1.5.21
Groovy: 3.0.8
Ant: Apache Ant(TM) version 1.10.9 compiled on September 27 2020
JVM: 1.8.0_302 (Temurin 25.302-b08)
OS: Linux 5.10.47-linuxkit amd64
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (k8s)
[Pipeline] withKubeConfig
[Pipeline] {
[Pipeline] sh
+ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 6h58m v1.21.2
[Pipeline] }
[kubernetes-cli] kubectl configuration cleaned up
[Pipeline] // withKubeConfig
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] End of Pipeline
Finished: SUCCESS
Jenkins实现Kubernetes部署流水线
在Agent定制环境准备好后,我们将构建完整的部署流水线。
根据我们选用的技术栈,部署流水线划分为如下阶段:
-
checkout代码
-
gradle编译
-
构建Docker镜像、推送到镜像服务器
-
发布到Kubernetes中
在开始构建流水线前,我们还需要做一些准备工作。
准备工作
首先,我们需要创建一个新的Spring Boot项目homs-start,用于流水线的演示。
这里使用Sping Boot Starter直接生成的,代码放到了Gitee托管,参考这里。
第二步,我们需要修改Jenskin的项目名,从test修改为homs-start。
接下来,我们需要在Jenkins上配置Gitee的ssh key凭据。
-
先确认已在Gitee上配置了公钥,并且保留了对应的私钥,参考这篇教程。
-
在Jenkins上配置Gitee的凭据,路径是:Jenkins -> Manage Jenkins -> Manage Credentials -> Global
-
SSH Username with private key,填入gitee的用户名和对应私钥,命名为GITEE
在流水线的步骤3中,我们需要打包一个新的镜像。
如果你还记得前两节的内容,应该知道我们的Agent实际是运行在Docker中的。
因此,我们的Agent需要具有"Docker Inside Docker"的能力,一般常见的有三种方法,可以参考[这篇文章](如何在Docker容器中运行Docker [3种方法] - 云+社区 - 腾讯云)。
本文中,我们选用socks挂载的模式,对Agent的镜像做一些改造,如下:
FROM jenkins/inbound-agent:latest-jdk8
ENV GRADLE_VERSION=7.2
ENV K8S_VERSION=v1.22.3
ENV DOCKER_CHANNEL stable
ENV DOCKER_VERSION 18.06.3-ce
# tool
USER root
RUN apt-get update && \
apt-get install -y curl unzip sudo && \
apt-get clean
# docker
RUN curl -fsSL "https://download.docker.com/linux/static/${DOCKER_CHANNEL}/x86_64/docker-${DOCKER_VERSION}.tgz" \
| tar -xzC /usr/local/bin --strip=1 docker/docker
# gradle
RUN curl -skL -o /tmp/gradle-bin.zip https://services.gradle.org/distributions/gradle-$GRADLE_VERSION-bin.zip && \
mkdir -p /opt/gradle && \
unzip -q /tmp/gradle-bin.zip -d /opt/gradle && \
ln -sf /opt/gradle/gradle-$GRADLE_VERSION/bin/gradle /usr/local/bin/gradle
RUN chown -R 1001:0 /opt/gradle && \
chmod -R g+rw /opt/gradle
# kubectl
RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/$K8S_VERSION/bin/linux/amd64/kubectl
RUN chmod +x ./kubectl
RUN mv ./kubectl /usr/local/bin
# add jenkins user to sudoer without password
RUN usermod -aG sudo jenkins
RUN echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers
USER jenkins
如上所述,我们对构建镜像的改动如下:
-
增加了docker二进制文件
-
对用户jenkins添加了sudo免密权限
运行脚本也需要做一些改造:
#!/bin/bash
NAME="jenkins_e1"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--name $NAME \
--env PUID=$PUID \
--env PGID=$PGID \
--add-host kubernetes:10.1.172.136 \
--volume /var/run/docker.sock:/var/run/docker.sock \
--detach \
--init coder4/jenkins-my-agent \
-workDir=/home/jenkins/agent \
-url http://10.1.172.136:8080 \
b057970bf978f53a8f945d470ac644e44c945e4b7259b216f703dedb95d0cac9 \
e1
运行脚本的主要是,挂载了/var/run/docker.sock到容器内。
运行后,我们以默认用户登录到容器内,查看docker是否可以正常使用:
jenkins@936e27b3c460:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
936e27b3c460 coder4/jenkins-my-agent "/usr/local/bin/jenk…" 6 seconds ago Up 4 seconds jenkins_e1
577db2106c7d jenkins/jenkins:lts-jdk11 "/sbin/tini -- /usr/…" 4 days ago Up About an hour 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 0.0.0.0:50000->50000/tcp, :::50000->50000/tcp jenkins
d44c3e421fb7 registry.cn-hangzhou.aliyuncs.com/google_containers/kicbase:v0.0.25 "/usr/local/bin/entr…" 5 days ago Up About an hour 127.0.0.1:50437->22/tcp, 127.0.0.1:50440->2376/tcp, 127.0.0.1:50442->5000/tcp, 127.0.0.1:50443->8443/tcp, 127.0.0.1:50441->32443/tcp minikube
注意,因为挂载的socks默认是root权限,这里需要使用sudo。
构建脚本
下面,我们按照流水线的步骤,构建脚本如下:
pipeline {
agent any
environment {
project = "coder4/homs-start"
}
stages {
stage('git') {
steps {
git credentialsId: 'GITEE', url: 'git@gitee.com:/'+ project + '.git', branch: 'master'
}
}
stage('gradle') {
steps {
sh "gradle build"
}
}
stage('docker image build') {
steps {
sh '''
# get right jar
jarPath=$(du -a ./build/libs/* | sort -n -r | head -n 1 | cut -f2-)
jarFile=$( echo ${jarPath##*/} )
# make Dockerfile
cat <<EOF > Dockerfile
FROM openjdk:8
COPY $jarPath $jarFile
ENTRYPOINT ["java","-jar","/$jarFile"]
EOF
# build Docker image
sudo docker build -t coder4/${JOB_NAME}:${BUILD_NUMBER} .
# push to docker hub
sudo docker push coder4/${JOB_NAME}:${BUILD_NUMBER}
'''
}
}
stage('k8s') {
steps {
withKubeConfig([credentialsId: "60a8e9d2-0212-4ff4-aa98-f46fced97121",serverUrl: "https://kubernetes:6443"]) {
sh "kubectl create deployment my-nginx --image=coder4/${JOB_NAME}:${BUILD_NUMBER}"
}
}
}
}
}
脚本比较长,我们分步解析:
-
git拉代码
-
这里直接使用的gitee的公开仓库,可以根据实际情况,替换为公司内的gitlab等私有仓库
-
GITEE的凭据,就是在准备工作中配置的那个
-
-
gradle编译
-
这里直接使用gradle build命令
-
编译好后,会在build/libs目录下,生成jar包
-
-
打包Docker镜像,上传镜像
-
首先选择build/libs下尺寸最大的jar包(一般是fat jar,可独立运行的那个)
-
基于openjdk8的基础镜像,添加打好的jar包,并设定启动为jar包
-
构建好镜像后,将其推送到镜像仓库。这里选用了Docker Hub共有仓库,你可以换用Harbor等私有仓库。
-
这里默认使用项目名做为镜像名,构建版本做为镜像版本号
-
-
在Kubernetes上部署
- 使用上面的镜像,创建一个deployment
保存上述JenkinsFile脚本后,点击部署,如果一切顺利,会部署成功,我们看一下部署结果:
kubectl get pods
NAME READY STATUS RESTARTS AGE
homs-start795f967dd6-7szxp 1/1 Running 0 57s
查看日志:
kubectl logs -f my-nginx-795f967dd6-7szxp
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.5.6)
2021-11-10 02:49:45.469 INFO 1 --- [ main] com.homs.start.StartApplication : Starting StartApplication using Java 1.8.0_312 on my-nginx-795f967dd6-7szxp with PID 1 (/homs-start-0.0.1-SNAPSHOT.jar started by root in /)
2021-11-10 02:49:45.473 INFO 1 --- [ main] com.homs.start.StartApplication : No active profile set, falling back to default profiles: default
2021-11-10 02:49:46.866 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2021-11-10 02:49:46.887 INFO 1 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2021-11-10 02:49:46.887 INFO 1 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.54]
2021-11-10 02:49:46.999 INFO 1 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2021-11-10 02:49:47.000 INFO 1 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1450 ms
2021-11-10 02:49:47.964 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2021-11-10 02:49:47.974 INFO 1 --- [ main] com.homs.start.StartApplication : Started StartApplication in 3.119 seconds (JVM running for 5.216)
如上所示,Pod中的Spring Boot进程已成功启动!
至此,我们已经完整地实现了全链路的部署流水线开发。
同时,上述流水线还有很大的改进空间,我们将在下一节继续优化流水线。
Jenkins优化Kubernetes部署流水线
在上一节,我们实现了全链路的部署流水线。
本节,我们将继续完善、优化部署水线。
Gradle加速
首先,在之前的定制Agent中,我们使用了Gradle(Maven)的默认仓库。
由于众所周知的原因,默认仓库的速度很慢、不稳定。
这回严重降低打包流水线的速度,我们对这一问题进行优化。
修改Agent的Dockerfile如下,增加Gradle仓库配置:
FROM jenkins/inbound-agent:latest-jdk8
ENV GRADLE_VERSION=7.2
ENV K8S_VERSION=v1.22.3
ENV DOCKER_CHANNEL stable
ENV DOCKER_VERSION 18.06.3-ce
# tool
USER root
RUN apt-get update && \
apt-get install -y curl unzip sudo && \
apt-get clean
# docker
RUN curl -fsSL "https://download.docker.com/linux/static/${DOCKER_CHANNEL}/x86_64/docker-${DOCKER_VERSION}.tgz" \
| tar -xzC /usr/local/bin --strip=1 docker/docker
# gradle
RUN curl -skL -o /tmp/gradle-bin.zip https://services.gradle.org/distributions/gradle-$GRADLE_VERSION-bin.zip && \
mkdir -p /opt/gradle && \
unzip -q /tmp/gradle-bin.zip -d /opt/gradle && \
ln -sf /opt/gradle/gradle-$GRADLE_VERSION/bin/gradle /usr/local/bin/gradle
RUN chown -R 1001:0 /opt/gradle && \
chmod -R g+rw /opt/gradle
# kubectl
RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/$K8S_VERSION/bin/linux/amd64/kubectl
RUN chmod +x ./kubectl
RUN mv ./kubectl /usr/local/bin
# add jenkins user to sudoer without password
RUN usermod -aG sudo jenkins
RUN echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers
# jenkins
USER jenkins
# gradle mirror
ENV GRADLE_CONFIG_DIR=/home/jenkins/.gradle
RUN mkdir ${GRADLE_CONFIG_DIR}
RUN echo "Ly8gcHJvamVjdAphbGxwcm9qZWN0c3sKICAgIHJlcG9zaXRvcmllcyB7CgltYXZlbkxvY2FsKCkKICAgICAgICBtYXZlbiB7IHVybCAnaHR0cHM6Ly9tYXZlbi5hbGl5dW4uY29tL3JlcG9zaXRvcnkvcHVibGljLycgfQogICAgICAgIG1hdmVuIHsgdXJsICdodHRwczovL21hdmVuLmFsaXl1bi5jb20vcmVwb3NpdG9yeS9qY2VudGVyLycgfQogICAgICAgIG1hdmVuIHsgdXJsICdodHRwczovL21hdmVuLmFsaXl1bi5jb20vcmVwb3NpdG9yeS9nb29nbGUvJyB9CiAgICAgICAgbWF2ZW4geyB1cmwgJ2h0dHBzOi8vbWF2ZW4uYWxpeXVuLmNvbS9yZXBvc2l0b3J5L2dyYWRsZS1wbHVnaW4vJyB9CiAgICAgICAgbWF2ZW4geyB1cmwgJ2h0dHBzOi8vaml0cGFjay5pby8nIH0KICAgIH0KfQoKLy8gcGx1Z2luCnNldHRpbmdzRXZhbHVhdGVkIHsgc2V0dGluZ3MgLT4KICAgIHNldHRpbmdzLnBsdWdpbk1hbmFnZW1lbnQgewogICAgICAgIC8vIFByaW50IHJlcG9zaXRvcmllcyBjb2xsZWN0aW9uCiAgICAgICAgLy8gcHJpbnRsbiAiUmVwb3NpdG9yaWVzIG5hbWVzOiAiICsgcmVwb3NpdG9yaWVzLmdldE5hbWVzKCkKCiAgICAgICAgLy8gQ2xlYXIgcmVwb3NpdG9yaWVzIGNvbGxlY3Rpb24KICAgICAgICByZXBvc2l0b3JpZXMuY2xlYXIoKQoKICAgICAgICAvLyBBZGQgbXkgQXJ0aWZhY3RvcnkgbWlycm9yCiAgICAgICAgcmVwb3NpdG9yaWVzIHsKCSAgICBtYXZlbkxvY2FsKCkKICAgICAgICAgICAgbWF2ZW4gewogICAgICAgICAgICAgICAgdXJsICJodHRwczovL21hdmVuLmFsaXl1bi5jb20vcmVwb3NpdG9yeS9ncmFkbGUtcGx1Z2luLyIKICAgICAgICAgICAgfQogICAgICAgIH0KICAgIH0KfQo=" | base64 --decode > ${GRADLE_CONFIG_DIR}/init.gradle
如上所示,在打包的最后环节:
-
添加.gradle目录
-
创建init.gradle脚本
-
由于Dockerfile的语法格式限制,我们将配置文件编码为Base64再写入
配置文件的原文如下:
// project
allprojects{
repositories {
mavenLocal()
maven { url 'https://maven.aliyun.com/repository/public/' }
maven { url 'https://maven.aliyun.com/repository/jcenter/' }
maven { url 'https://maven.aliyun.com/repository/google/' }
maven { url 'https://maven.aliyun.com/repository/gradle-plugin/' }
maven { url 'https://jitpack.io/' }
}
}
// plugin
settingsEvaluated { settings ->
settings.pluginManagement {
// Print repositories collection
// println "Repositories names: " + repositories.getNames()
// Clear repositories collection
repositories.clear()
// Add my Artifactory mirror
repositories {
mavenLocal()
maven {
url "https://maven.aliyun.com/repository/gradle-plugin/"
}
}
}
}
我们使用新镜像重启Agent,会发现编译环节由1分钟缩短到10秒内。
在之前构建的版本中,我们只考虑了部署,没有考虑升级情况。
可以修改JenkinsFile,采用"yaml + kubectl apply"的方式,让部署支持滚动升级。
pipeline {
agent any
environment {
project = "coder4/homs-start"
}
stages {
stage('git') {
steps {
git credentialsId: 'GITEE', url: 'git@gitee.com:/'+ project + '.git', branch: 'master'
}
}
stage('gradle') {
steps {
sh "gradle build"
}
}
stage('docker image build') {
steps {
sh '''
# get right jar
jarPath=$(du -a ./build/libs/* | sort -n -r | head -n 1 | cut -f2-)
jarFile=$( echo ${jarPath##*/} )
# make Dockerfile
cat <<EOF > Dockerfile
FROM openjdk:8
COPY $jarPath $jarFile
ENTRYPOINT ["java","-jar","/$jarFile"]
EOF
# build Docker image
sudo docker build -t coder4/${JOB_NAME}:${BUILD_NUMBER} .
# push to docker hub
sudo docker push coder4/${JOB_NAME}:${BUILD_NUMBER}
'''
}
}
stage('k8s') {
steps {
withKubeConfig([credentialsId: "60a8e9d2-0212-4ff4-aa98-f46fced97121",serverUrl: "https://kubernetes:6443"]) {
sh """
# prepare deployment yaml
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${JOB_NAME}-deployment
labels:
app: ${JOB_NAME}
spec:
selector:
matchLabels:
app: ${JOB_NAME}
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: ${JOB_NAME}
spec:
containers:
- name: ${JOB_NAME}-server
image: coder4/${JOB_NAME}:${BUILD_NUMBER}
ports:
- containerPort: 8080
"""
}
}
}
}
}
经过上述改造后,我们可以随时滚动升级新版本了。
支持回滚操作
在新版本发布后,可能会遇到故障,需要回滚的情况,这也需要流水线支持这一功能。
我们采用"Parameterized Project"的方式,来设定参数。
首先,修改当前项目的配置,勾选"This project is parameterized"。
接着,安装插件“Active Choice”,以便开启Groovy脚本的“动态参数”。
加下来,我们添加3个参数
- Active Choices Parameter,参数名"JobName"
代码、截图如下:
m = Thread.currentThread().toString() =~ /job\/(.*)\/build/
return [m[0][1]]
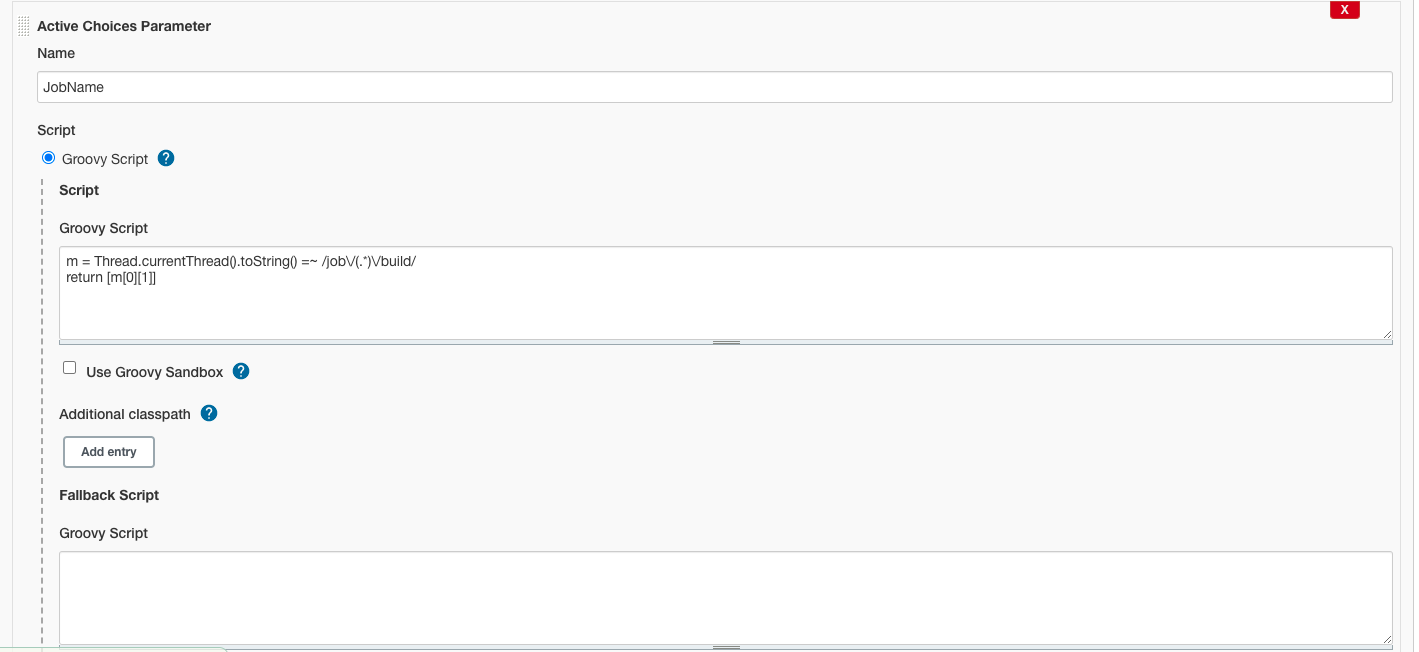
- Choose Parameter,参数名"Action",固定两个选项:Deploy、Rollback
代码和截图如下:
- Active Choices Reactive Parameter,参数名"RollbackVersion"
需要配置Referenced parameters为"Action,JobName"
代码和截图如下:
if (Action.equals('Deploy')) {
return []
} else {
return jenkins.model.Jenkins.instance.getJob(JobName).builds.findAll{ it.result == hudson.model.Result.SUCCESS }.collect{ "$it.number".toString() }
}
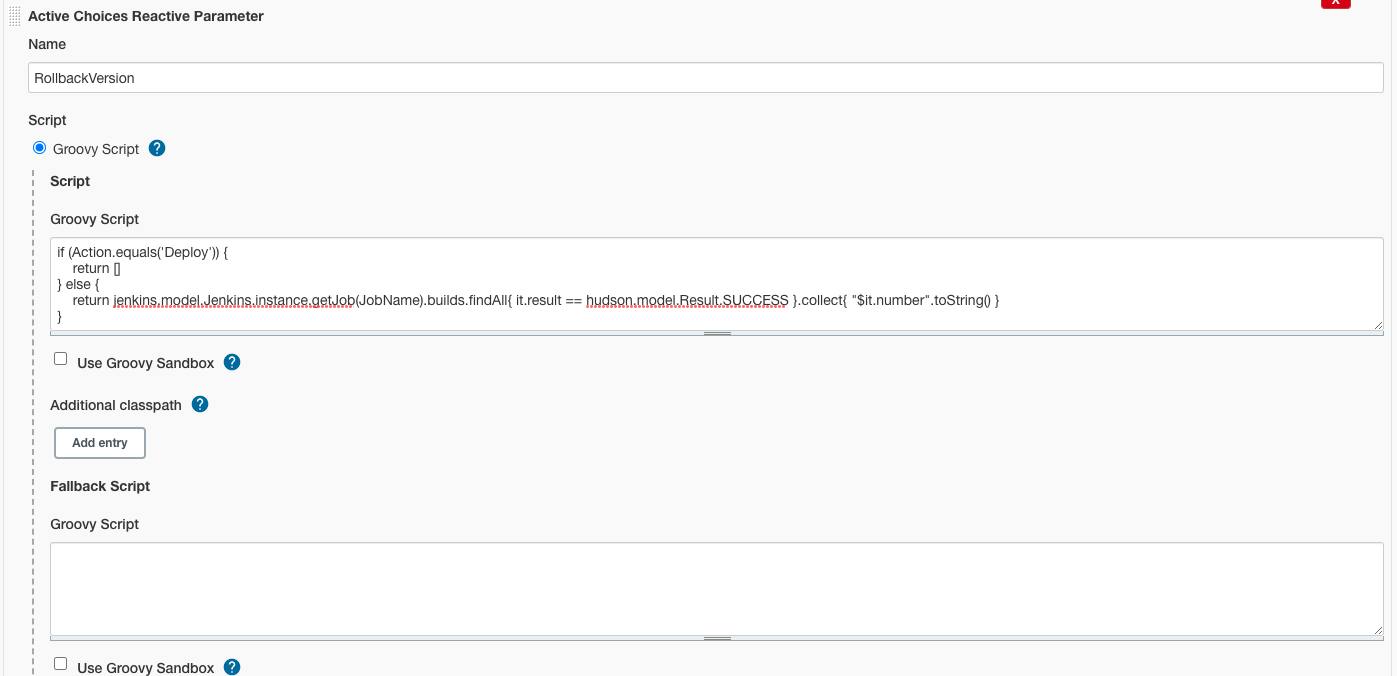
经过上述设置,我们的项目拥有了3个可输入参数,如下图所示:
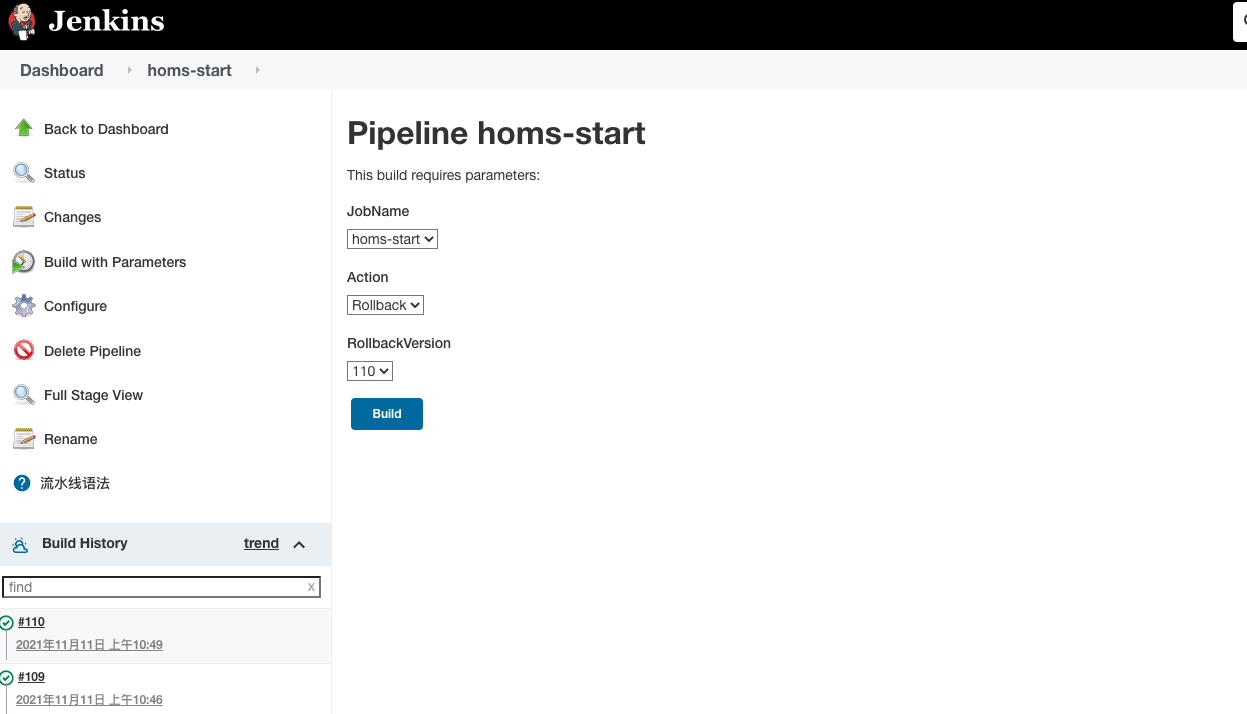
其中:
JobName:项目名
Action:决定了是部署 or 回滚
RollbackVersion:仅当回滚时生效,决定了要回滚到哪个版本
除此之外,我们还需要对JenkinsFile进行改造,如下:
pipeline {
agent any
stages {
stage('git') {
steps {
script {
if (params.Action.equals("Rollback")) {
echo "Skip in Rollback"
} else {
git credentialsId: 'GITEE', url: 'git@gitee.com:/coder4/'+ env.JOB_NAME + '.git', branch: 'master'
}
}
}
}
stage('gradle') {
steps {
script {
if (params.Action.equals("Rollback")) {
echo "Skip in Rollback"
} else {
sh "gradle build"
}
}
}
}
stage('docker image build') {
steps {
script {
if (params.Action.equals("Rollback")) {
echo "Skip in Rollback"
} else {
sh '''
# get right jar
jarPath=$(du -a ./build/libs/* | sort -n -r | head -n 1 | cut -f2-)
jarFile=$( echo ${jarPath##*/} )
# make Dockerfile
cat <<EOF > Dockerfile
FROM openjdk:8
COPY $jarPath $jarFile
ENTRYPOINT ["java","-jar","/$jarFile"]
EOF
# build Docker image
sudo docker build -t coder4/${JOB_NAME}:${BUILD_NUMBER} .
# push to docker hub
sudo docker push coder4/${JOB_NAME}:${BUILD_NUMBER}
'''
}
}
}
}
stage('k8s') {
steps {
script {
env.DEPLOY_VERSION = params.Action.equals("Rollback") ? params.RollbackVersion : env.BUILD_NUMBER
withKubeConfig([credentialsId: "60a8e9d2-0212-4ff4-aa98-f46fced97121",serverUrl: "https://kubernetes:6443"]) {
sh """
echo "Kubernetes Deploy $JOB_NAME Version $DEPLOY_VERSION"
# prepare deployment yaml
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${JOB_NAME}-deployment
labels:
app: ${JOB_NAME}
spec:
selector:
matchLabels:
app: ${JOB_NAME}
replicas: 1
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: ${JOB_NAME}
spec:
containers:
- name: ${JOB_NAME}-server
image: coder4/${JOB_NAME}:${DEPLOY_VERSION}
ports:
- containerPort: 8080
"""
}
}
}
}
}
}
我们来试验一下成果,首先,执行新部署:执行成功,版本号111,耗时21s
kubectl describe pod homs-start-deployment-644677f984-bksl9
Name: homs-start-deployment-644677f984-bksl9
Namespace: default
Priority: 0
Node: minikube/192.168.49.2
Start Time: Thu, 11 Nov 2021 19:06:25 +0800
Labels: app=homs-start
pod-template-hash=644677f984
Annotations: <none>
Status: Running
IP: 172.17.0.4
IPs:
IP: 172.17.0.4
Controlled By: ReplicaSet/homs-start-deployment-644677f984
Containers:
homs-start-server:
Container ID: docker://279e11005931dfd8aa876134bb2441294a768766261aeb0bb88b5004047f5060
Image: coder4/homs-start:111
Image ID: docker-pullable://coder4/homs-start@sha256:526640caca84a10254e42ad12dd617eaf45c75c17b4ebb7731fe623509938e5c
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 11 Nov 2021 19:06:31 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-gkpv7 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-gkpv7:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 37s default-scheduler Successfully assigned default/homs-start-deployment-644677f984-bksl9 to minikube
Normal Pulling 37s kubelet Pulling image "coder4/homs-start:111"
Normal Pulled 31s kubelet Successfully pulled image "coder4/homs-start:111" in 5.781019732s
Normal Created 31s kubelet Created container homs-start-server
Normal Started 31s kubelet Started container homs-start-server
接下来,我们回滚到107版本,由于机器上有镜像,因此只耗时1s。
kubectl describe pod homs-start-deployment-5bf947768c-dt8w2
Name: homs-start-deployment-5bf947768c-dt8w2
Namespace: default
Priority: 0
Node: minikube/192.168.49.2
Start Time: Thu, 11 Nov 2021 18:49:22 +0800
Labels: app=homs-start
pod-template-hash=5bf947768c
Annotations: <none>
Status: Running
IP: 172.17.0.5
IPs:
IP: 172.17.0.5
Controlled By: ReplicaSet/homs-start-deployment-5bf947768c
Containers:
homs-start-server:
Container ID: docker://bc626494af343b6d56b707258e03a85ae668abb21dcc3ca2b72d6239e3b56b3d
Image: coder4/homs-start:107
Image ID: docker-pullable://coder4/homs-start@sha256:526640caca84a10254e42ad12dd617eaf45c75c17b4ebb7731fe623509938e5c
Port: 8080/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 11 Nov 2021 18:49:27 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dt7g2 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-dt7g2:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 16m default-scheduler Successfully assigned default/homs-start-deployment-5bf947768c-dt8w2 to minikube
Normal Pulling 16m kubelet Pulling image "coder4/homs-start:107"
Normal Pulled 16m kubelet Successfully pulled image "coder4/homs-start:107" in 3.365201023s
Normal Created 16m kubelet Created container homs-start-server
Normal Started 16m kubelet Started container homs-start-server
在本文中,我们围绕编译、镜像进行了优化,但这还远没有达到"完美"的程度。
我提一些思路,供大家参考:
-
docker镜像瘦身:打Dokcer镜像时,其实无需将jdk+ jar包一起打,可以只打jar包。在生成Deployment时,通过Pod的init container模式,将jar包拷贝进jdk的运行容器中,从而完成启动。
-
回滚版本选择优化:在前面的实现中,我们筛选了所有成功部署过的版本,将其做为可回滚的版本,但这其中的一部分,实际是通过"回滚"的方式部署成功的,在镜像仓库中,并没有与之对应的镜像版本。我们可以拉取镜像仓库中可用的版本,来实现回滚。
-
镜像版本优化:目前采用的是Job的"Build Version"做为镜像版本,可以再此基础上,追加Git版本号,以便区分代码拉取。
-
支持多分之:当前,我们默认用的是master分之,应当可以通过参数的方式,支持不同分之的修改。
-
JenkinsFile共享:目前的JenkinsFile是直接配置在项目中的,如果微服务项目很多,逐一配置势必很麻烦,可以通过 “Jenkins Shared Library”的方式,在多项目间共享脚本配置。
工具链
微服务架构的成功落地,离不开工具链的辅助。
本节将讨论与研发密切相关的工具链,包括
-
快速生成微服务的模板工具
-
Ldap及内网认证系统
-
基于Gitlab的私有代码平台
-
基于JFrog Artifactory的Maven私有仓库
-
基于Registry 2的Docker镜像私有仓库
如果你有好工具推荐,请提Issue告诉我 : - )
Jenkins搭建入门
Jenkins是一款开源、强大的持续集成工具,其前身是Hudson(商用软件)。
本节将介绍Jenkins的搭建。从架构上理解,Jenklins由两类角色组成:
-
Controller:主控节点,负责管理、配置工作,也称作Master节点。
-
Agent:执行具体作业的工作节点,也称作Slave节点,或者Executor节点。
严格来说,Master节点也可以执行具体作业,但是处于安全性考虑,不建议这样做。
Jeknins的启动与初始配置
首先启动Controller节点:
#!/bin/bash
NAME="jenkins"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/jenkins"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-v $VOLUME:/var/jenkins_home \
-p 8080:8080 \
-p 50000:50000 \
--detach \
--restart always \
jenkins/jenkins:lts-jdk11
如上所示,我们启动了jenkins的主控节点,并对外暴露了8080、5000两个端口。
我们在浏览器中打开如下链接:http://127.0.0.1:8080/
第一次启动会进行初始化,要求输入密码,我们使用如下命令查看:
docker logs -f jenkins
....
*************************************************************
*************************************************************
*************************************************************
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
9169c97282d64545b36bc96cf7c1aaab
This may also be found at: /var/jenkins_home/secrets/initialAdminPassword
*************************************************************
*************************************************************
*************************************************************
2021-11-04 03:15:53.502+0000 [id=49] INFO h.m.DownloadService$Downloadable#load: Obtained the updated data file for hudson.tasks.Maven.MavenInstaller
2021-11-04 03:15:53.502+0000 [id=49] INFO hudson.util.Retrier#start: Performed the action check updates server successfully at the attempt #1
2021-11-04 03:15:53.517+0000 [id=49] INFO hudson.model.AsyncPeriodicWork#lambda$doRun$0: Finished Download metadata. 36,815 ms码
如上中间部分,即初始密码。
输入初始密码后,会要求安装创建,建议至少安装下述插件:
-
Gradle:用于Java项目的打包和编译
-
Pipeline:用户开发流水线作业
-
Git:用于代码拉取
-
SSH Build Agents
-
Kubernetes:用于在Kubernetes集群上启动Slave节点
-
Kubernetes CLI:用于执行远程Kubernetes的二进制文件
安装完插件后,需要创建初始管理员账号。
Jeknins的Agent节点配置
启动Controller节点后,我们着手配置Slave节点,这里也有多种选项:
-
启动固定数量的Slave节点
-
按需启动,用完释放
-
上述两种方案的混合
考虑到并发性、资源利用率,我们选用方案2:在Kubernetes集群上,按需启动Slave容器,执行完毕后销毁。
首先,我们需要登录到Kubernetes集群的Master节点上,查看已有的证书信息。
cd ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: /Users/coder4/.minikube/ca.crt
extensions:
- extension:
last-update: Thu, 04 Nov 2021 11:23:17 CST
provider: minikube.sigs.k8s.io
version: v1.22.0
name: cluster_info
server: https://127.0.0.1:52058
name: minikube
contexts:
- context:
cluster: minikube
extensions:
- extension:
last-update: Thu, 04 Nov 2021 11:23:17 CST
provider: minikube.sigs.k8s.io
version: v1.22.0
name: context_info
namespace: default
user: minikube
name: minikube
current-context: minikube
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /Users/coder4/.minikube/profiles/minikube/client.crt
client-key: /Users/coder4/.minikube/profiles/minikube/client.key
如上,共包含了3个证书/密钥:ca.crt、client.crt、client.key。
我们使用他们创建新的凭据,供Jenkins使用:
openssl pkcs12 -export -out ./kube-jenkins.pfx -inkey ./client.key -in ./client.crt -certfile ./ca.crt
上述创建过程会要求输入密码,请记牢后续会用到。
此外,上述文件中的ca.crt后面会再次用到。
在Jenkins上配置Kubernetes集群之前,我们假设以下信息:
-
10.1.172.136:Jenkins所在的物理机节点
-
https://127.0.0.1:52058:Kubernetes集群的api server地址
由于我当前使用的minikube,不难发现,minikube的api server只在本地开了端口,并没有监听到物理机上,因此网段是不通的,所以我们先使用socat进行端口映射。
socat TCP4-LISTEN:6443,fork TCP4:127.0.0.1:52058
如上,经过映射后,所有打到本机的公网IP(10.1.172.136)、端口6443上的流量,会被自动转发到52058上。
接下来,我们着手在Jenkins上添加Kubernetes的集群配置。
Manage Jenkins -> Manage Nodes and Clouds -> Configure Clouds -> Add a new cloud -> Kubernetes
截图如下:
其中核心配置如下:
-
名称:自选必填,这里选了kubernetes
-
Kuberenetes地址:https://10.1.172.136:6443
-
Kubernetes 服务证书 key:输入上文中ca.crt中的信息,注意换行问题。
-
凭据:上传上述生成的kube-jenkins.pfx,同时输入密码
-
Jenkins地址:http://10.1.172.136:8080
上述天禧后,点击"连接测试",如果一切正常,你会发现如下报错:
这是因为我们经过转发后,host与证书中的并不匹配。
我们修改下Jenkins的docker启动脚本,添加hosts参数:
--add-host kubernetes:10.1.172.136
重启Jenkins后,将上述位置的"Kuberenetes地址"修改为"https://kubernetes:6443",再次重试连接,一切会成功。
记得保存所有配置。
测试任务
我们配置一个测试任务:
新建任务 -> 流水线
代码如下:
podTemplate {
node(POD_LABEL) {
stage('Run shell') {
sh 'echo hello world'
}
}
}
保存后,点击"立即构建",运行结果如下:
Started by user admin
[Pipeline] Start of Pipeline
[Pipeline] podTemplate
[Pipeline] {
[Pipeline] node
Created Pod: kubernetes default/test-4-xsc01-4292c-4rkrz
[Normal][default/test-4-xsc01-4292c-4rkrz][Scheduled] Successfully assigned default/test-4-xsc01-4292c-4rkrz to minikube
[Normal][default/test-4-xsc01-4292c-4rkrz][Pulled] Container image "jenkins/inbound-agent:4.3-4-jdk11" already present on machine
[Normal][default/test-4-xsc01-4292c-4rkrz][Created] Created container jnlp
[Normal][default/test-4-xsc01-4292c-4rkrz][Started] Started container jnlp
Agent test-4-xsc01-4292c-4rkrz is provisioned from template test_4-xsc01-4292c
---
apiVersion: "v1"
kind: "Pod"
metadata:
annotations:
buildUrl: "http://10.1.172.136:8080/job/test/4/"
runUrl: "job/test/4/"
labels:
jenkins: "slave"
jenkins/label-digest: "802a637918cdcb746f1931e3fa50c8f991b59203"
jenkins/label: "test_4-xsc01"
name: "test-4-xsc01-4292c-4rkrz"
spec:
containers:
- env:
- name: "JENKINS_SECRET"
value: "********"
- name: "JENKINS_AGENT_NAME"
value: "test-4-xsc01-4292c-4rkrz"
- name: "JENKINS_NAME"
value: "test-4-xsc01-4292c-4rkrz"
- name: "JENKINS_AGENT_WORKDIR"
value: "/home/jenkins/agent"
- name: "JENKINS_URL"
value: "http://10.1.172.136:8080/"
image: "jenkins/inbound-agent:4.3-4-jdk11"
name: "jnlp"
resources:
limits: {}
requests:
memory: "256Mi"
cpu: "100m"
volumeMounts:
- mountPath: "/home/jenkins/agent"
name: "workspace-volume"
readOnly: false
nodeSelector:
kubernetes.io/os: "linux"
restartPolicy: "Never"
volumes:
- emptyDir:
medium: ""
name: "workspace-volume"
Running on test-4-xsc01-4292c-4rkrz in /home/jenkins/agent/workspace/test
[Pipeline] {
[Pipeline] stage
[Pipeline] { (Run shell)
[Pipeline] sh
+ echo hello world
hello world
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
Finished: SUCCESS
至此,我们已经成功配置了基础的Jenkins,并成功在Kubernetes集群上执行了一次构建任务。
基于LDAP的内网统一认证
对于任何公司而言,一套“内部通用”的统一认证系统是必不可少的。
请注意两个关键字:内部、通用。
-
内部:认证系统只在公司内部关联的系统使用,并且需要关联具体的员工信息,如:工号、用户名、邮箱等。
-
通用:这套系统不是只提供验证,还要和其他系统共享认证,例如:项目管理系统、版本控制系统、发布系统等等。
在本书中,我们选取LDAP(Lightweight Directory Access Protocol)做为统一认证工具。
LDAP是一个开放的,中立的,工业标准的应用协议,通过IP协议提供访问控制和维护分布式信息的目录信息。
由于LDAP出现的年代比较久远(1993),也并非专门为公司认证设计的,因此其易用性较差。我们选用LDAP Account Manager做为辅助管理工具。
部署open-ldap服务
我们选用开源的open-ldap做为服务端,进行部署:
#!/bin/bash
NAME="openldap"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/openldap/"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--volume "$VOLUME:/data/openldap/" \
-e PUID=$PUID \
-e PGID=$PGID \
-e LDAP_TLS=false \
-e LDAP_DOMAIN=coder4.com \
-e LDAP_ADMIN_PASSWORD=admin123 \
-e LDAP_CONFIG_PASSWORD=config123 \
-e LDAP_READONLY_USER=true \
-e LDAP_READONLY_USER_USERNAME=readonly \
-e LDAP_READONLY_USER_PASSWORD=readonly123 \
-p 389:389 \
-p 636:636 \
--detach \
--restart always \
osixia/openldap:1.5.0
如上所示:
-
关闭了TLS加密,在生产环境中,建议配置证书并打开它
-
域名:coder4.com,可以根据需要自行更改,会影响用户的后缀
-
管理员密码:admin123,请根据需要自行更改
-
配置用户密码:config123,请根据需要自行更改
-
只读用户:readonly/readlony123,可自行更改
启动成功后,我们校验下初始化的几个用户:
首先是admin,你会发现用户是通过逗号分割、分组的,你要适用ldap的这种表示方法。
ldapwhoami -h 127.0.0.1 -p 389 -D "cn=admin,dc=coder4,dc=com" -w admin123
dn:cn=admin,dc=coder4,dc=com
接下来是readonly
ldapwhoami -h 127.0.0.1 -p 389 -D "cn=readonly,dc=coder4,dc=com" -w readonly123
dn:cn=readonly,dc=coder4,dc=com
最后,我们添加两个组织结构,研发部rd和人力资源部hr:
version: 1
# rd org
dn: ou=rd,dc=coder4,dc=com
objectClass: top
objectClass: organizationalUnit
ou: rd
# hr org
dn: ou=hr,dc=coder4,dc=com
objectClass: top
objectClass: organizationalUnit
ou: hr
执行添加动作:
ldapadd -c -h 127.0.0.1 -p 389 -w admin123 -D "cn=admin,dc=coder4,dc=com" -f ./org.ldif
启用Ldap Account Manager
我们通过Docker运行LAM,如下:
#!/bin/bash
NAME="lam"
PUID="1000"
PGID="1000"
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
-e PUID=$PUID \
-e PGID=$PGID \
-e LDAP_DOMAIN=coder4.com \
-e LDAP_SERVER=ldap://10.1.172.136:389 \
-e LDAP_USER=cn=admin,dc=coder4,dc=com \
-e LAM_PASSWORD=lam123 \
-p 8080:80 \
--detach \
--restart always \
ldapaccountmanager/lam:7.7
解释下上述配置:
-
域名:与前面openldap服务的配置相关联
-
ldap服务器:前面ldap服务的地址
-
user:管理员用户名,不用输入密码
-
LAM密码:是部分管理功能所需要的密码,请根据需要自行修改
启动成功后,我们访问http://127.0.0.1:8080,出现如下登录界面:
输入前面admin的密码,即可完成登录。
进入后,可以发现氛围User / Group两个主要的Tab。
-
User:用户的增删改
-
Group:用户组的增删改
我们首先修改下User功能默认的配置。打开右上角Tools -> Profile Editor -> User,这里设置为:
-
LDAP suffix:rd > coder4 > com
-
Automatically add this extension: false
接着,我们需要添加一个Posix组,Groups -> New Group -> Unix Group
-
Suffix:coder4 > com
-
Group name:user
最后,我们尝试添加一个用户,Users -> New User,在如下界面中填写:
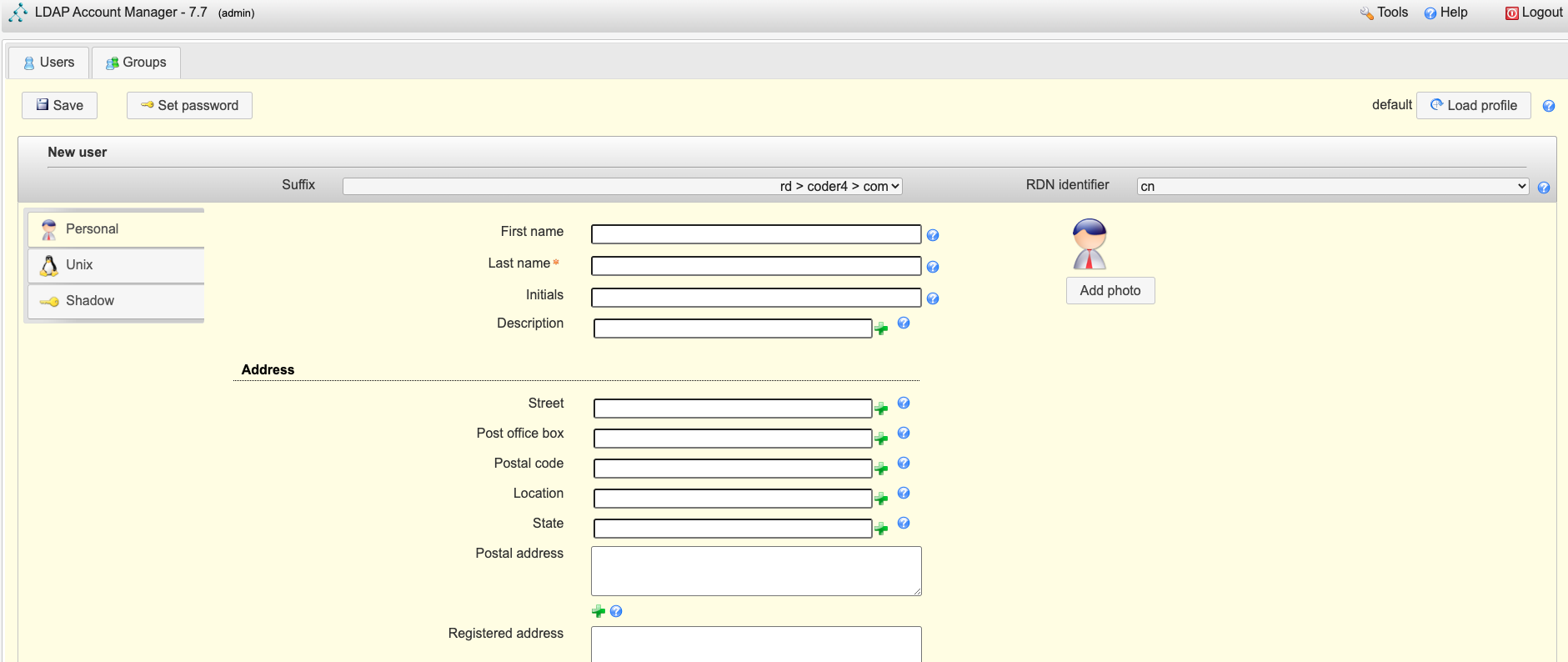
-
Last name: zhangsan
-
Suffix:rd > coder4 > com
-
RDN identifier:cn
-
Password:123456
-
Unix Primary Group:user
点击Save保存后,我们验证一下:
ldapwhoami -h 127.0.0.1 -p 389 -D "cn=zhangsan,ou=rd,dc=coder4,dc=com" -w 123456
dn:cn=zhangsan,ou=rd,dc=coder4,dc=com
成功!
如果你想看组织的全貌,可以进入:Tools -> TreeView:
至此,我们已经成功搭建了基于ldap的内网统一验证。然而,本节只是一个起点,在后续搭建的系统中,我们都会接入ldap认证系统。
使用Registry2搭建Docker私有仓库
在打造持续交付流水线一章中,在部署前,需要先打包Docker镜像,并上传到DockerHub镜像仓库。
DockerHub是由Docker推出的共有镜像仓库,使用广泛,但存在一下问题:
-
由于众所周知的原因,从国内访问速度较慢
-
对公网所有用户可见,存在泄密风险
-
存在泄露风险
因此,搭建私有的容器镜像仓库,十分必要。
本节,我们将基于Docker官方的registry2,搭建私有镜像仓库。
启动
我们用Docker启动Docker镜像仓库:-)
#!/bin/bash
NAME="registry2"
PUID="1000"
PGID="1000"
VOLUME="$HOME/docker_data/registry2"
mkdir -p $VOLUME
docker ps -q -a --filter "name=$NAME" | xargs -I {} docker rm -f {}
docker run \
--hostname $NAME \
--name $NAME \
--volume $VOLUME:/var/lib/registry \
--env REGISTRY_STORAGE_DELETE_ENABLED=true \
--env PUID=$PUID \
--env PGID=$PGID \
-p 5000:5000 \
--detach \
--restart always \
registry:2
如上所示,我们添加了允许删除镜像的配置。
启动成功后,镜像仓库运行在 http://127.0.0.1:5000 地址上。
由于我们未启用https证书校验,因此需要在客户端上配置:
/etc/docker/daemon.json中添加一行
"insecure-registries":["10.1.172.136:5000","127.0.0.1:5000"],
上传镜像
打tag
docker tag 7aa22139eca1 127.0.0.1:5000/jenkins-my-agent:latest
上传,成功!
docker push 127.0.0.1:5000/jenkins-my-agent:latest
The push refers to repository [127.0.0.1:5000/jenkins-my-agent]
25af0e804bd9: Pushed
d481382bb71b: Pushed
9a0d9a003e42: Pushed
d90590887490: Pushed
2e10e3c8baa6: Pushed
260e081d58bf: Pushed
545b9645e192: Pushed
ed0f1dee792d: Pushed
ebb837d412f9: Pushed
b80c59a58a8e: Pushed
953a3e11bab6: Pushed
833c84c9f2ea: Pushed
7a45298bdd53: Pushed
62a747bf1719: Pushed
latest: digest: sha256:3b7ebd6948da5d7d9267e02b58698c3046e940f565eab9687243aaa8727ace29 size: 3266
我们查询下历史版本,这里发现有一个latest的版本了
curl "127.0.0.1:5000/v2/jenkins-my-agent/tags/list"
{"name":"jenkins-my-agent","tags":["latest"]}
尝试删除镜像,成功!
registry='localhost:5000'
name='jenkins-my-agent'
curl -v -sSL -X DELETE "http://${registry}/v2/${name}/manifests/$(
curl -sSL -I \
-H "Accept: application/vnd.docker.distribution.manifest.v2+json" \
"http://${registry}/v2/${name}/manifests/$(
curl -sSL "http://${registry}/v2/${name}/tags/list" | jq -r '.tags[0]'
)" \
| awk '$1 == "Docker-Content-Digest:" { print $2 }' \
| tr -d $'\r' \
)"
至此,我们成功搭建了私有镜像。以下是拓展练习,留给你来实现:
-
启用https证书(自签)
-
支持每个容器保留最近5个tag
-
将打造持续交付流水线中的镜像仓库,替换为私有仓库