1. 环境配置
1.1 训练环境和onnx(电脑端执行)
#使用conda创建一个python环境 conda create -n torch python=3.9 #激活环境 conda activate torch #安装yolov8 pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple #onnx安装 pip install onnx -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2 导出onnx和rknn环境(电脑端执行)
安装toolkit2-1.5.2
下载链接:
链接:百度网盘 请输入提取码
提取码:abcf
下载后对应的文件为 onxx2rknn
下载后,创建一个conda环境,python使用3.6
#创建rknn环境 conda create -n yolov8-export python=3.6 #激活环境 conda activate yolov8-export #进入下载的文件夹 安装依赖库,保证每个都能安装上,如果有安装不上的,-i后面换别的源地址进行安装 pip install -r requirements_cp36-1.5.2.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #都安装完以后安装rknn_toolkit,还是进入百度云下载的文件夹 pip install rknn_toolkit2-1.5.2+b642f30c-cp36-cp36m-linux_x86_64.whl
1.3 rk3588上opencv编译(板卡上执行)
编译好的动态库我放到了百度云盘中路径为 opencv4_install,如果板子是rk3588,系统为ubuntu20.04应该是可以用起来的。如果不是的话,可能需要自己编译一下,步骤如下:
参考链接 ubuntu在arm平台下编译安装opencv(亲测可用)_opencv arm-CSDN博客
1.3.1 下载opencv源码
opencv: Release OpenCV 4.4.0 · opencv/opencv · GitHub
opencv_contrib: https://github.com/opencv/opencv_contrib/releases/tag/4.4.0
我已经放到了百度云上,在1.2节的百度云中,对应文件为opencv4.4
下载后放在到板卡上
1.3.2 开始编译(板卡上执行)
解压opencv和opencv-contrib 代码,在板卡上新建一个opencv4_install文件夹,用于安装opencv,再进入解压后的opencv4.4.0文件夹, 新建文件夹 build,进入build文件夹,打开终端执行以下命令
注意:
- CMAKE_INSTALL_PREFIX 这个路径改成自己实际的绝对安装地址
- OPENCV_EXTRA_MODULES_PATH 这个路径换成自己实际的解压后的contrib的绝对地址
- 下面的OFF,ON表示库是否编译,因为用到的库不多,基本就是图像和视频相关,所以我把别的都关闭了
- 其中BUILD_SHARED_LIBS表示是否编译为动态库,我关闭后,变成静态库,使用的时候一直报错,所以我还是使用的动态库去链接,有懂的大佬请指教一下
cmake -D CMAKE_BUILD_TYPE=Release \ -D CMAKE_INSTALL_PREFIX=/home/forlinx/opencv/opencv4_install \ -D OPENCV_EXTRA_MODULES_PATH=//home/forlinx/opencv/opencv_contrib-4.4.0/modules \ -D BUILD_opencv_python3=OFF \ -D PYTHON3_EXECUTABLE=$(which python3) \ -D PYTHON3_INCLUDE_DIR=$(python3 -c "from distutils.sysconfig import get_python_inc; print(get_python_inc())") \ -D PYTHON3_PACKAGES_PATH=$(python3 -c "from distutils.sysconfig import get_python_lib; print(get_python_lib())") \ -D WITH_GTK_2_X=ON \ -D BUILD_SHARED_LIBS=ON \ -D WITH_OPENGL=OFF \ -D BUILD_opencv_python3=OFF \ -D BUILD_opencv_apps=OFF \ -D BUILD_TESTS=OFF \ -D BUILD_TESTS=0FF \ -D BUILD_opencv_calib3d=OFF \ -D BUILD_opencv_flann=OFF \ -D BUILD_opencv_stitching=OFF \ -D BUILD_opencv_ts=OFF \ -D BUILD_opencv_feature2d=OFF \ -D BUILD_opencv_superres=OFF \ -D BUILD_opencv_ononfree=OFF \ -D BUILD_opencv_gpu=OFF \ -D BUILD_opencv_stereo=OFF \ -D INSTALL_PYTHON_EXAMPLES=OFF \ -D BUILD_opencv_python3=OFF \ -D BUILD_IPP=OFF \ -D BUILD_TBB=OFF \ -D BUILD_opencv_java=OFF \ -D BUILD_JAVA=OFF \ -D BUILD_DOCS=0FF .
编译的时候,会报错误,缺一些依赖库,参照下面的链接进行解决
(注意需要按照这个这里的链接下载一系列文件
fatal error: boostdesc_bgm.i: No such file or directory · Issue #1301 · opencv/opencv_contrib · GitHub
搜索 leaf918, 把pitch文件下载下来,解压后,
把patch/boostdesc下的内容拷贝到 opencv-4.4.0/.cache/xfeatures2d/boostdesc/
把patch/vgg下面的内容拷贝到opencv-4.4.0/.cache/xfeatures2d/vgg/)
注意:这里缺少的文件我已经放到了百度云
patch文件我已经放到百度云opencv4.4/patch_文件夹下,可以下载放到对应位置后,在重新执行上述指令进行编译,直到无报错为止,再执行make指令进行编译
make -j8 #执行完后无报错 进行安装 sudo make install
编译成功后会生成以下文件
编译成功后,打开系统文件
#打开系统文件 vi /etc/profile #在最下面添加如下内容 export LD_LIBRARY_PATH=/opencv4_install/lib:$LD_LIBRARY_PATH export Opencv_DIR=/opencv4_install #上述路径要按照自己的绝对路径来写 #保存后重启板子
2. 训练部分(电脑端执行)
#下载yolov8官方代码 git clone https://github.com/ultralytics/ultralytics.git #切换分支 cd ultralytics git checkout a05edfbc27d74e6dce9d0f169036282042aadb97
2.1 训练脚本(电脑端执行)
- 我使用的是最轻量化的v8n模型, 所以第一行代码中使用的 yolov8n.yaml,训练时,工程会自动匹配yolov8n的模型,并使用yolov8n.pt作为预训练模型
- 因为我使用的自定义数据集,我是基于VisDrone数据加上了自己的数据制作的训练集,所以加载的是改造后的VisDrone.yaml文件 数据的转换这里不仔细写了,以后空了我再补充在这里,但是需要注意的是,我是二分类,所以需要修改两处地方,否则训练出来的模型是不正确的
2.2 修改配置(电脑端执行)
修改1:
代码路径: /ultralytics/cfg/models/v8/yolov8.yaml 第5行修改为自己训练集需要检测目标的类别数量
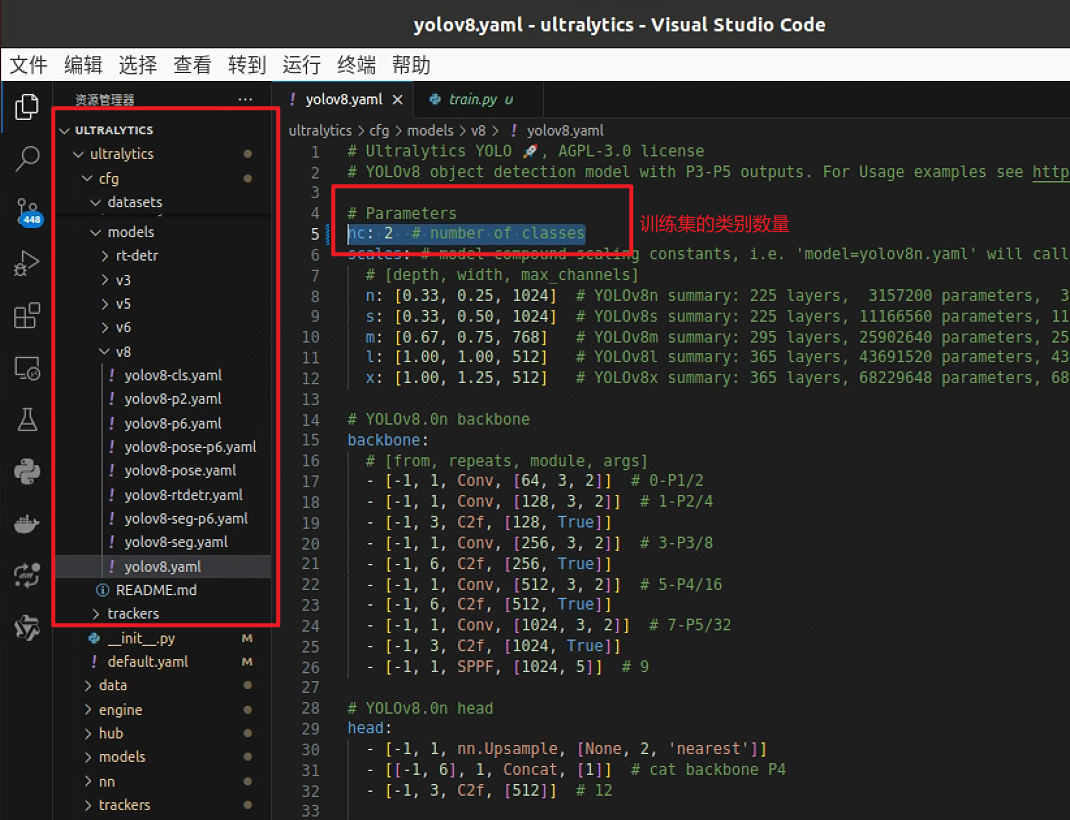
修改2:
/ultralytics/cfg/datasets/VisDrone.yaml中训练集、测试集、验证集的数据路径以及类别的label
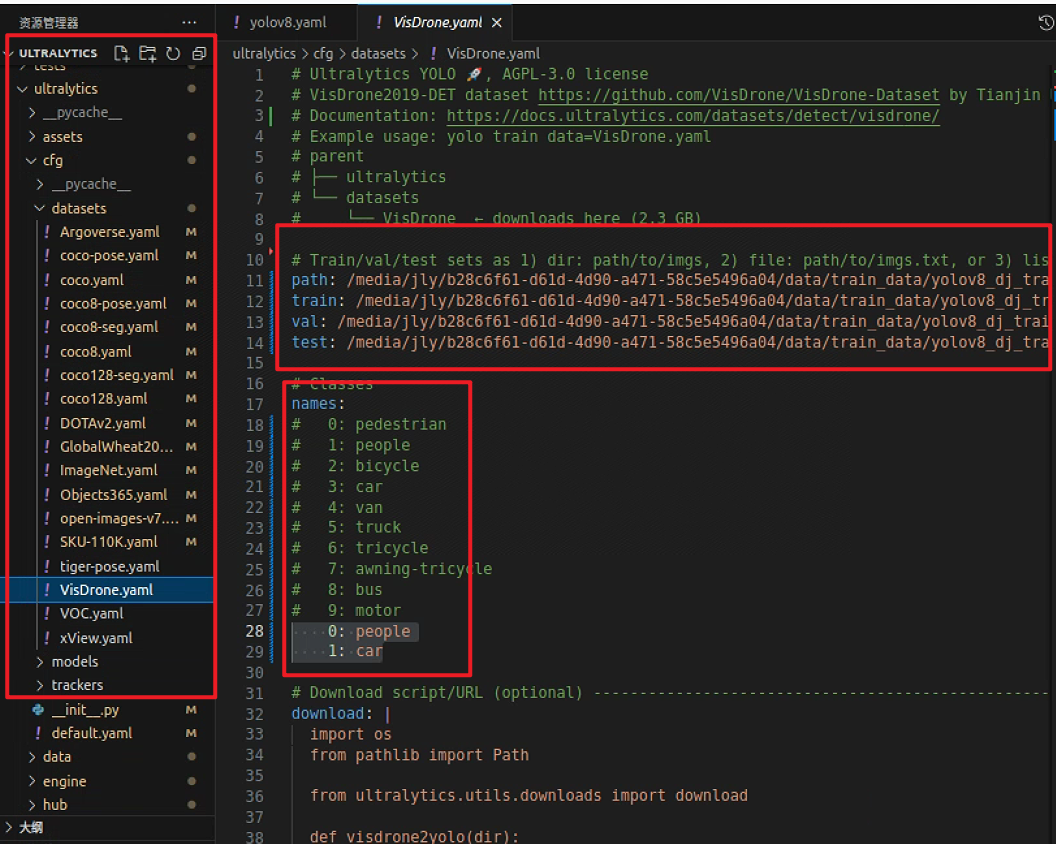
这里修改为自己对应数据的路径和类别,否则跑出来是错误的。
3. pt转onnx(电脑端执行)
将第二部分修改后的训练代码(修改后的两个配置文件版本),复制一份出来,然后将文件名字改为 ultralytics-export
下载百度云里面的git修改项,路径为 pt2onnx/enpei.modify.patch,将该文件拷贝到 ultralytics-expot文件夹内

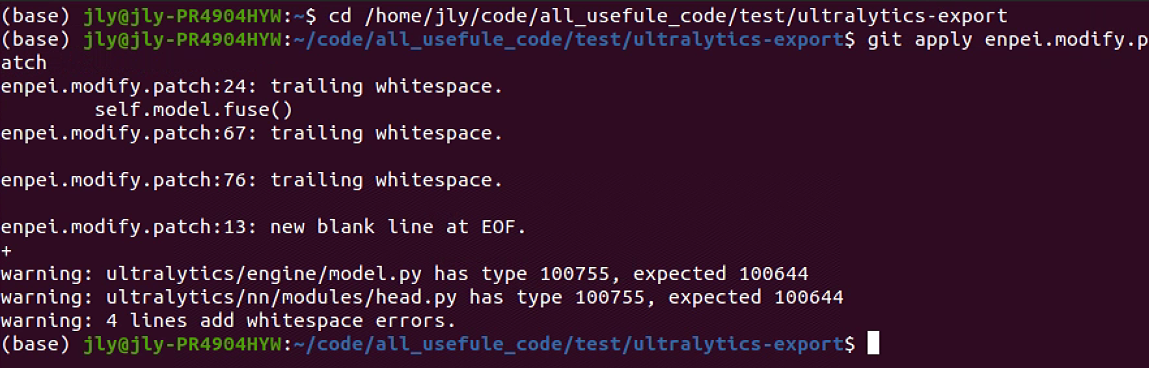
#进入ultralytics-export文件,进行代码修改 cd ultraytics-export #应用patch文件进行代码修改 git apply enpei.modify.patch
执行完后如图所示
此时代码已经修改完成,并且在文件下多了一个export_onnx.py文件, 再在ultralytics-export下新建一个文件夹叫 weights,将第2步中的训练好的最优模型best.pt 文件拷贝到weights文件夹下,
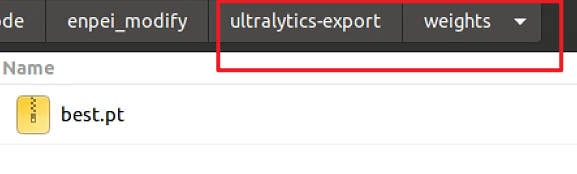
打开export_onnx.py文件,如果使用的别的版本v8模型,需要修改对应的模型配置文件
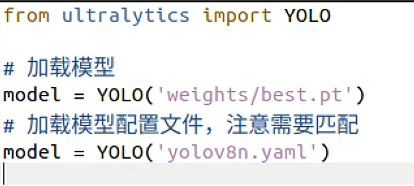
然后打开终端,执行下面的命令进行导出
#激活导出onnx环境 conda activate torch #进入ultralytics-export文件夹 cd ultralytics-export #开始转换 python export_onnx.py
执行完会在终端显示 done! 并且在weights文件夹下生成对应onnx文件,就表示转换成功
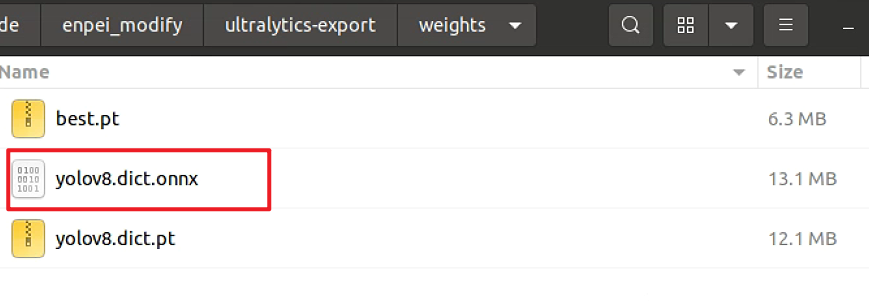
4. onnx转rknn(电脑端执行)
导出工具在百度云下载的文件夹中,路径为onnx2rknn/convert_rknn, 下载后把导出的yolov8.dict.onnx拷贝到该文件夹下
#激活第一步中rknn环境 conda activate toolkit-152-py36 #进入转换工具准备转换 cd convert_rknn python convert_rknn.py
终端就开始量化转换,如图所示:
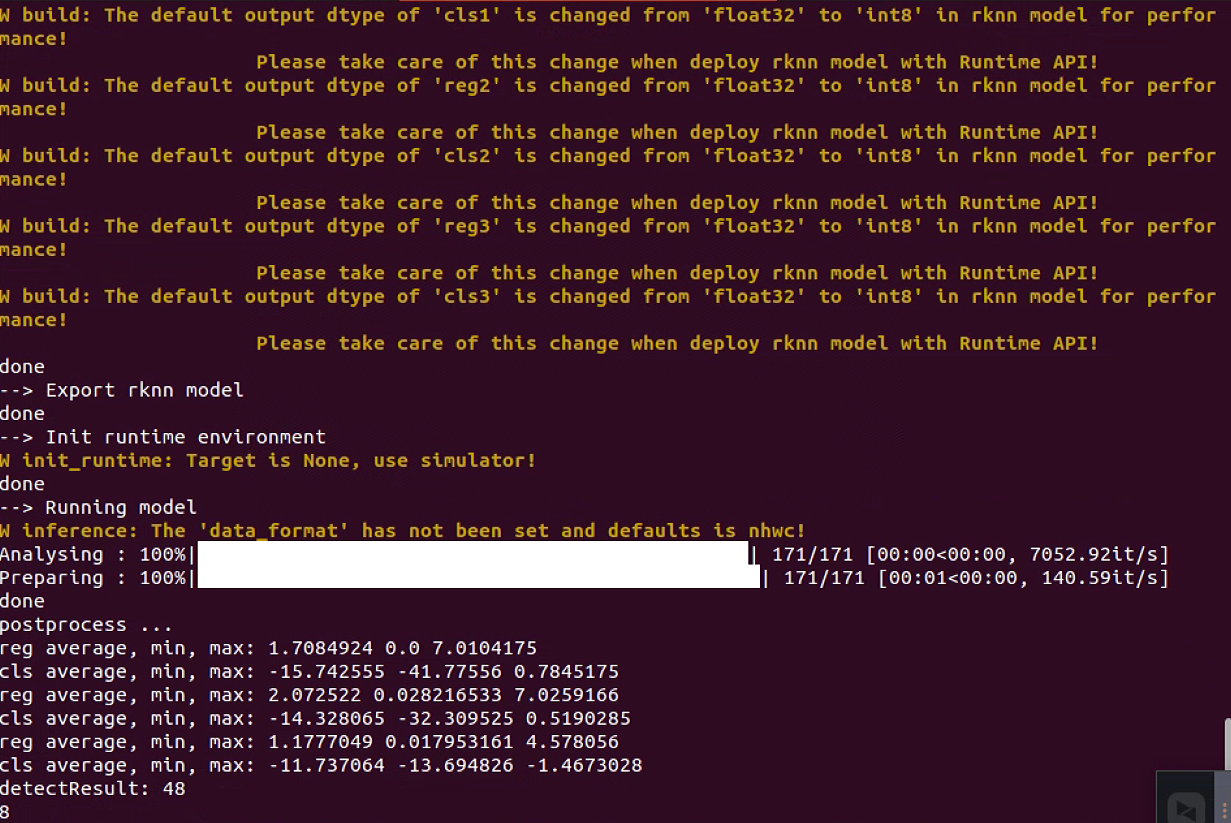
看到该界面就表示转换完成,可以在convert_rknn文件夹下看到多出来一个 yolov8.int.rknn模型和一个 test_rknn_results.jpg的推理结果,如果test_rknn_results.jpg的推理结果大致没啥问题,那么表示rknn转换无误了。

5. rk3588部署(板卡端执行)
c++推理代码放到百度云盘地址 rk3588_cplus中的,我把zip和没压缩的都上传上去了,避免下载有问题。此时我把第1.3部分中编译的opencv动态库放到了3rdparty里面的,所以需要修改一下CMakeLists.txt文件就基本可以跑起来了
修改CMakeLists.txt文件第37行代码,把opencv的路径修改为自己板卡上的绝对路径
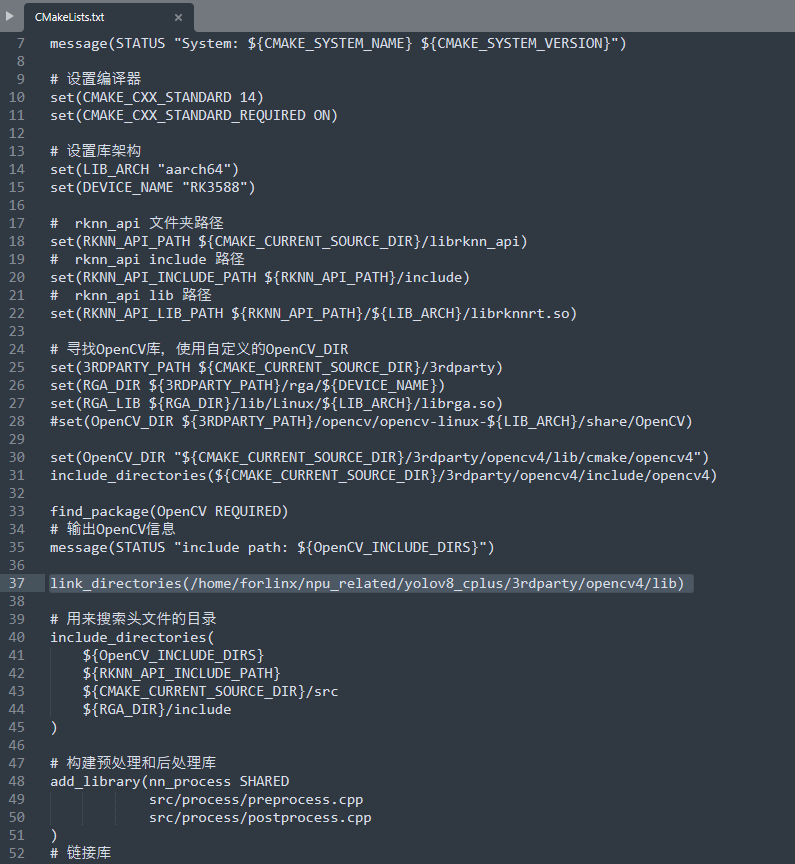
但是我感觉这句话是多余的,因为在第1.3.2步骤中,已经把动态库的地址写到了系统文件里
修改代码,文件/yolov8_cplus/src/postprocess.cpp中第 59 行代码,修改为自己需要检测类别的数量
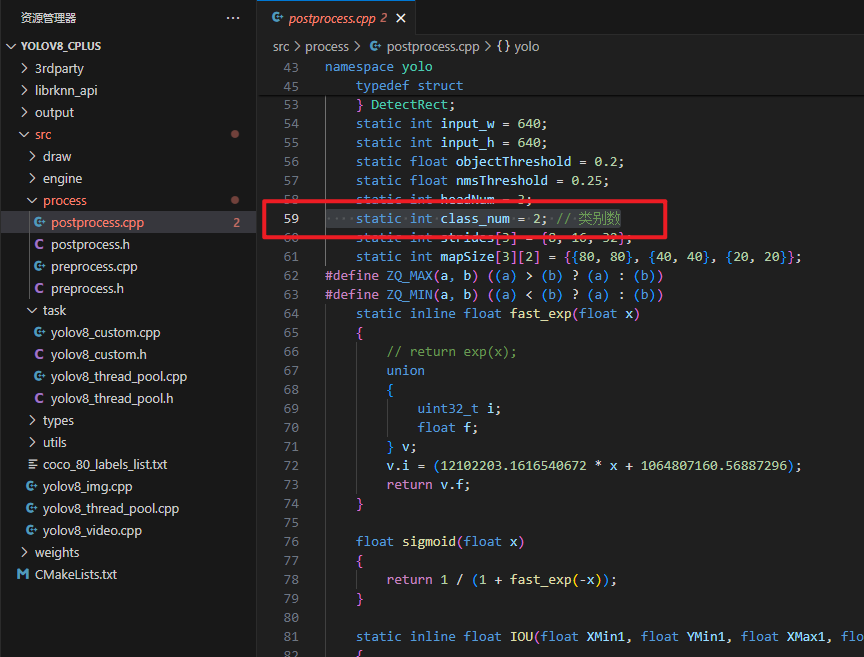
修改 标签文
进入文件src/task/yolov8_custom.cpp修改g_classes的类别为自己模型对应的类别
#开始编译 mkdir build && cd build #这里容易报opencv相关的错误,尝试自己解决一下,我编译动态库应该是可以用的 cmake .. #编译 make -j8
若一切顺利的话,这里在build文件下可以生成三个可执行文件
分别为yolov8_img 用于检测图像,yolov8_video 用于检测视频,yolov8_thread_pool用于线程池检测视频
#测试 ./yolov8_img [模型地址] [图像地址] ./yolob8_video [模型地址] [视频地址] [写1或者不写,写1表示将结果存下来,默认不存结果] ./yolov8_thread_pool [模型地址] [视频地址] [线程数]