1 使用spacy做简单nlp任务
需要先下载模型,这里下了中文模型,更多可以参考模型列表
python -m spacy download zh_core_web_lg
分析:
import spacy
nlp = spacy.load('zh_core_web_lg')
doc = nlp(u'有一个老师是很幸福的,可以有学习机会,有做比较的机会。如果从这些角度来说我是果粉呢,也不为过。')
for token in doc:
print(token.text, token.pos_, token.dep_)
输出:
有 VERB dep 一个 NUM dep 老师 NOUN nsubj 是 VERB cop 很 ADV advmod 幸福 VERB ccomp 的 PART discourse , PUNCT punct 可以 VERB aux:modal 有 VERB ROOT 学习 NOUN compound:nn 机会 NOUN dobj , PUNCT punct 有 VERB conj 做 VERB acl 比较 VERB dobj 的 PART mark 机会 NOUN dobj 。 PUNCT punct 如果 SCONJ advmod 从 ADP case 这些 DET det 角度 NOUN nmod:prep 来说 PART case 我 PRON nsubj 是 VERB cop 果粉 NOUN dep 呢 PART dep , PUNCT punct 也 ADV advmod 不 ADV neg 为过 VERB ROOT 。 PUNCT punct
这里token上的字段,常用的如下,更多参考:
- text:文本
- pos_:part-of-speech,词性标注,列表见这里
- tag_:详细的pos
- dep_:Syntactic dependency relation,语义分析关联
上面的nlp默认是一个pipeline,任务有:
nlp.pipeline
[('tok2vec', <spacy.pipeline.tok2vec.Tok2Vec at 0x78615a5f2620>),
('tagger', <spacy.pipeline.tagger.Tagger at 0x78615a5f3160>),
('parser', <spacy.pipeline.dep_parser.DependencyParser at 0x786157d4c200>),
('attribute_ruler',
<spacy.pipeline.attributeruler.AttributeRuler at 0x78615ac70780>),
('ner', <spacy.pipeline.ner.EntityRecognizer at 0x786157d4ceb0>)]
2 使用spacy识别命名实体(named entities)
命名实体识别(Named Entity Recognition,简称NER)是自然语言处理中的一项重要任务,它的目的是从文本中识别出具有特定意义的实体,如人名、地名、组织机构名等。NER可以帮助我们更好地理解文本中的信息,从而为后续的文本分析和应用提供更好的基础。
import spacy
nlp = spacy.load('zh_core_web_lg')
doc8 = nlp(u'大众集团将向香港投资10亿美元')
for token in doc8:
print(token.text, end=' | ')
print('\n----')
for ent in doc8.ents:
print(ent.text+' - '+ent.label_+' - '+str(spacy.explain(ent.label_)))
输出:
大众 | 集团 | 将 | 向 | 香港 | 投资 | 10亿 | 美元 | ---- 大众集团 - ORG - Companies, agencies, institutions, etc. 香港 - GPE - Countries, cities, states 10亿美元 - MONEY - Monetary values, including unit
3 使用spacy识别名词短语(Noun Chunks)
Noun Chunks是指由一个名词及其修饰词组成的短语。在NLP中,Noun Chunks通常用于提取文本中的关键信息。
注意中文模型不支持这个任务
import spacy
nlp = spacy.load('en_core_web_lg')
doc = nlp(u'Red cars do not carry higher insurance rates.')
for chunk in doc.noun_chunks:
print(chunk.text)
输出
Red cars higher insurance rates
4 使用nltk做词干提取(Stemming)
在NLP中,Stemming是一种文本处理技术,它的目的是将单词的不同形式(如单数、复数、时态等)转化为它们的基本形式,也就是词干(stem)。这样做的好处是可以减少单词的不同形式对文本分析的干扰,从而提高文本处理的效率和准确性。Stemming通常是在文本预处理阶段进行的,常用的算法有Porter Stemming算法和Snowball Stemming算法等。
Steming一般会较多地改动词的形态,Spacy没有提供这个,nltk有。
Porter Stemmer:
import nltk
from nltk.stem.porter import PorterStemmer
p_stemmer = PorterStemmer()
words = ['run','runner','running','ran','runs','easily','fairly']
for word in words:
print(f'{word} --> {p_stemmer.stem(word)}')
输出:
run --> run runner --> runner running --> run ran --> ran runs --> run easily --> easili fairly --> fairli
Snowball Stemmer是Poeter的改进版,效果更好一些:
from nltk.stem.snowball import SnowballStemmer
s_stemmer = SnowballStemmer(language='english')
words = ['run','runner','running','ran','runs','easily','fairly']
for word in words:
print(f'{word} --> {s_stemmer.stem(word)}')
输出:
run --> run runner --> runner running --> run ran --> ran runs --> run easily --> easili fairly --> fair
5 NLP的词形还原(Lemmatization)
NLP中的Lemmatization(词形还原)是一种文本处理技术,它的目的是将单词还原为它们的基本形式(称为词元或词根),以便更好地进行文本分析和处理。与Stemming不同,Lemmatization会考虑单词的词性和上下文信息,因此得到的结果更加准确。例如,将单词“am”, “are”, “is” 还原为它们的基本形式“be”。
Spacy有Lemmatization
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u"I am a runner running in a race because I love to run since I ran today")
for token in doc:
print(f"{token.text:15} {token.pos_:15} {token.lemma:20} {token.lemma_:15}")
输出
I PRON 4690420944186131903 I am AUX 10382539506755952630 be a DET 11901859001352538922 a runner NOUN 12640964157389618806 runner running VERB 12767647472892411841 run in ADP 3002984154512732771 in a DET 11901859001352538922 a race NOUN 8048469955494714898 race because SCONJ 16950148841647037698 because I PRON 4690420944186131903 I love VERB 3702023516439754181 love to PART 3791531372978436496 to run VERB 12767647472892411841 run since SCONJ 10066841407251338481 since I PRON 4690420944186131903 I ran VERB 12767647472892411841 run today NOUN 11042482332948150395 today
可以发现,对时态等都可以做还原,很强大
6 NLP的停用词(Stop Word)
import spacy
nlp = spacy.load('en_core_web_sm')
print(len(nlp.Defaults.stop_words))
print(nlp.vocab['myself'].is_stop)
# add stop word
nlp.Defaults.stop_words.add('btw')
print(len(nlp.Defaults.stop_words))
nlp.vocab['btw'].is_stop = True
print(nlp.vocab['btw'].is_stop)
上述增加自定义停用词的方法有点丑,输出:
326 False 327 True
7 规则匹配(Pattern Matching)
import spacy
from spacy.matcher import Matcher
nlp = spacy.load('en_core_web_sm')
pattern1 = [{'LOWER': 'solarpower'}]
pattern2 = [{'LOWER': 'solar'}, {'LOWER': 'power'}]
pattern3 = [{'LOWER': 'solar'}, {'IS_PUNCT': True}, {'LOWER': 'power'}]
matcher = Matcher(nlp.vocab)
matcher.add('SolarPower', [pattern1, pattern2, pattern3])
doc = nlp(u'The Solar Power industry continues to grow as demand \
for solarpower increases. Solar-power cars are gaining popularity.')
found_matches = matcher(doc)
for match_id, start, end in found_matches:
string_id = nlp.vocab.strings[match_id]
span = doc[start:end]
print(match_id, string_id, start, end, span.text)
输出:
8656102463236116519 SolarPower 1 3 Solar Power 8656102463236116519 SolarPower 10 11 solarpower 8656102463236116519 SolarPower 13 16 Solar-power
规则支持的选项如下:
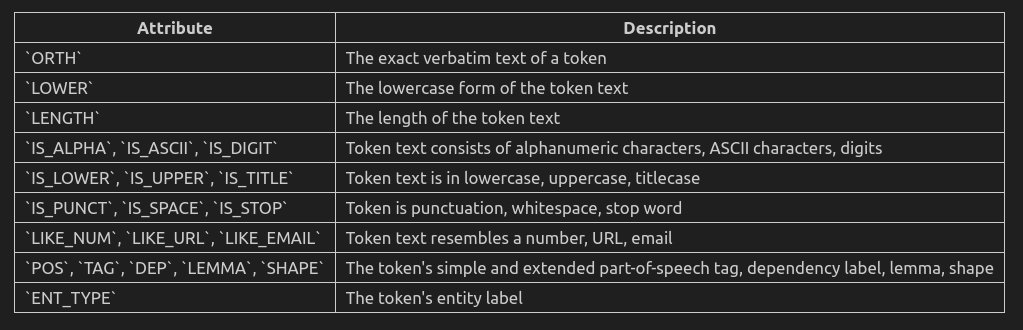
8 短语匹配(Phase Matching)
import spacy
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import PhraseMatcher
with open('reaganomics.txt', encoding='utf8', errors='ignore') as f:
doc = nlp(f.read())
phrase_list = ['voodoo economics', 'supply-side economics', 'trickle-down economics', 'free-market economics']
phrase_patterns = [nlp(text) for text in phrase_list]
matcher = PhraseMatcher(nlp.vocab)
matcher.add('VoodooEconomics', None, *phrase_patterns)
matches = matcher(doc)
sents = [sent for sent in doc.sents]
for sent in sents:
if matches[4][1] < sent.end:
print(sent)
break
更多可以看这里
9 词性标注(Part of Speech)
词性标注任务(Part Of Speech,简称POS),它的作用是为每个词汇确定其在句子中的词性,例如名词、动词、形容词等。这对于自然语言处理任务非常重要,因为不同的词性在句子中扮演不同的角色,对于理解句子的意义和结构非常关键。
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u"The quick brown fox jumped over the lazy dog's back.")
for token in doc:
print(f'{token.text:{10}} {token.pos_:{10}} {token.tag_:{10}} {spacy.explain(token.tag_)}')
输出:
The DET DT determiner quick ADJ JJ adjective (English), other noun-modifier (Chinese) brown ADJ JJ adjective (English), other noun-modifier (Chinese) fox NOUN NN noun, singular or mass jumped VERB VBD verb, past tense over ADP IN conjunction, subordinating or preposition the DET DT determiner lazy ADJ JJ adjective (English), other noun-modifier (Chinese) dog NOUN NN noun, singular or mass 's PART POS possessive ending back NOUN NN noun, singular or mass . PUNCT . punctuation mark, sentence closer
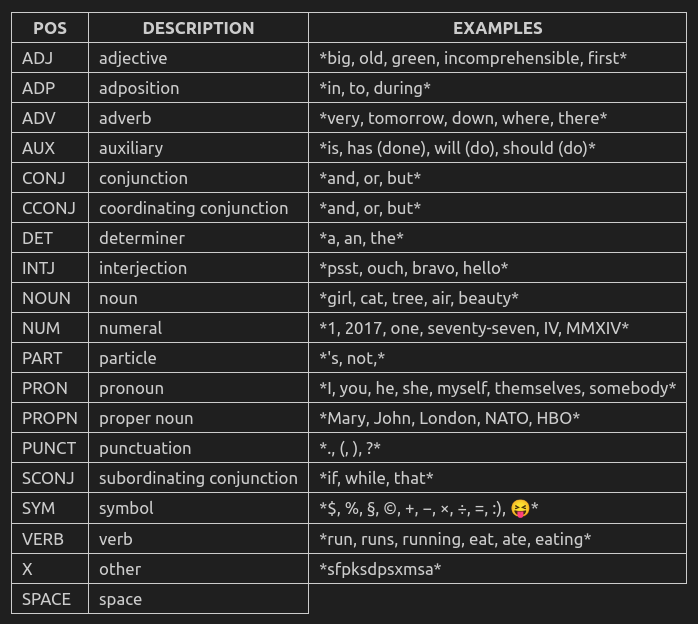
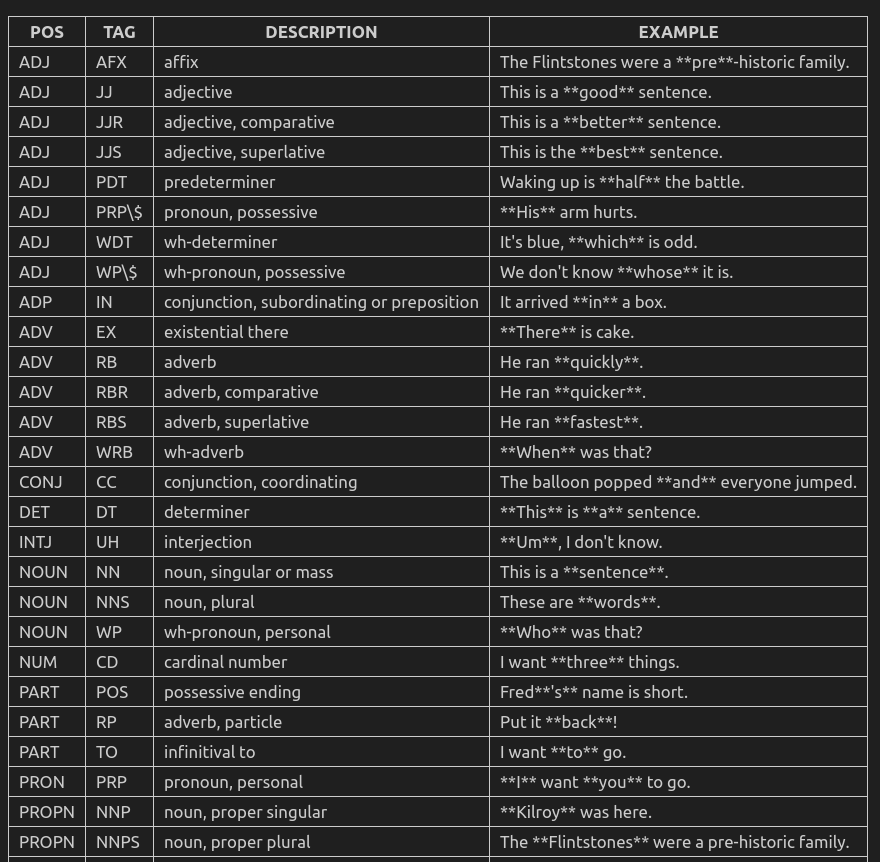
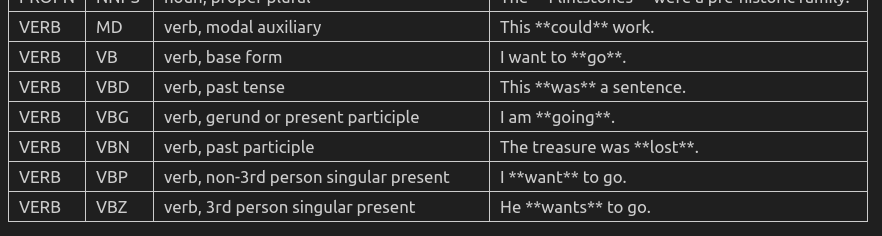
所有POS基本类型如下表,即pos_字段(pos是对应id):
扩展POS如下表,即tag_字段(tag为id):
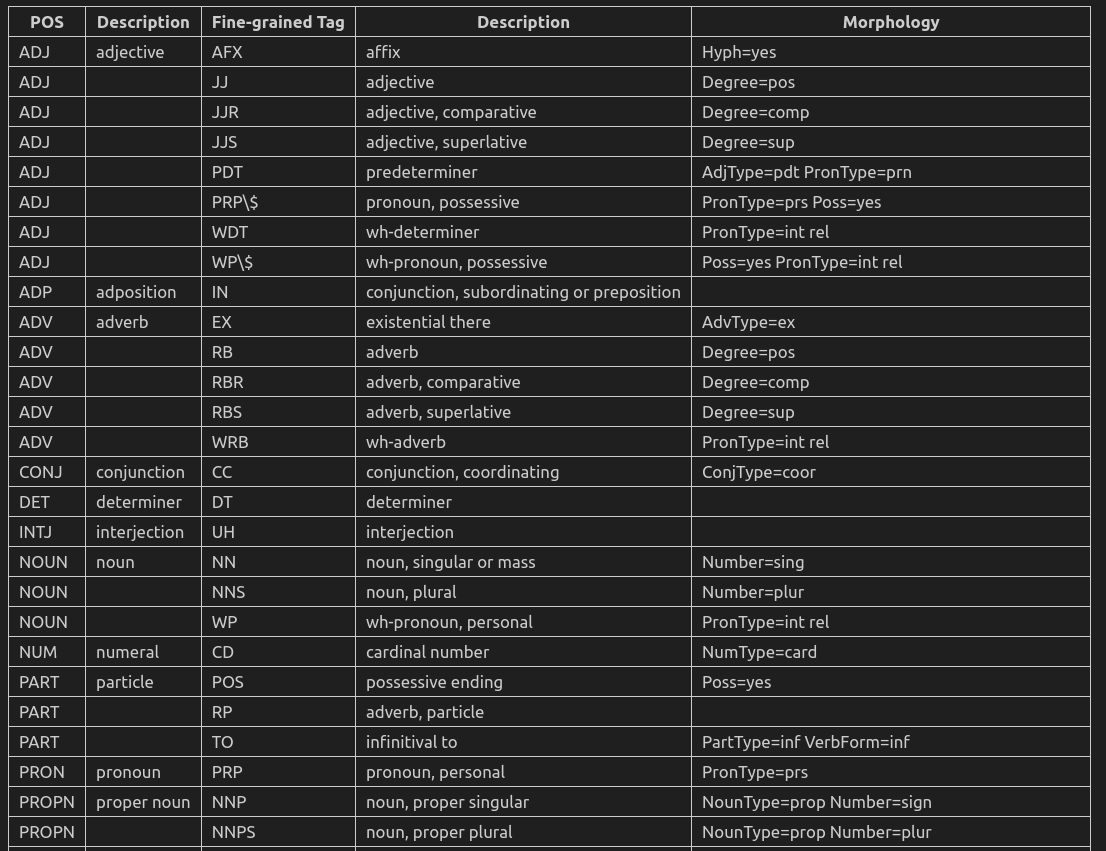
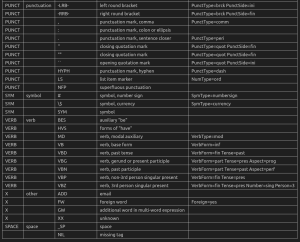
对照如下:
10 词性标注统计
按照POS统计
POS_counts = doc.count_by(spacy.attrs.POS)
for k,v in sorted(POS_counts.items()):
print(f'{k}. {doc.vocab[k].text:{5}}: {v}')
输出
84. ADJ : 3 85. ADP : 1 90. DET : 2 92. NOUN : 3 94. PART : 1 97. PUNCT: 1 100. VERB : 1
按照扩展POS统计
TAG_counts = doc.count_by(spacy.attrs.TAG)
for k,v in sorted(TAG_counts.items()):
print(f'{k}. {doc.vocab[k].text:{4}}: {v}')
输出
74. POS : 1 1292078113972184607. IN : 1 10554686591937588953. JJ : 3 12646065887601541794. . : 1 15267657372422890137. DT : 2 15308085513773655218. NN : 3 17109001835818727656. VBD : 1
11 词性标注(Part of Speech)可视化
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u"The quick brown fox jumped over the lazy dog's back.")
options = {'distance': 110, 'compact': 'True', 'color': 'yellow', 'bg': '#09a3d5', 'font': 'Times'}
displacy.render(doc, style='dep', jupyter=True, options=options)
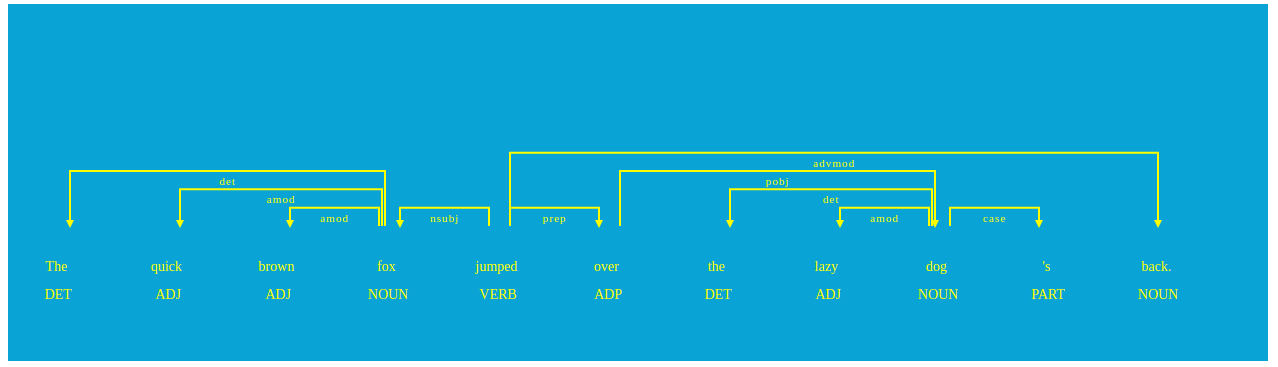
也可以启动本地服务器
displacy.serve(doc, style='dep', options=options)
12 命名实体识别(Named Entity Recognition)
GitHub Copilot: 在自然语言处理(NLP)中,命名实体识别(NER)是一种用于识别文本中具有特定意义的实体的技术。这些实体可以是人、地点、组织、日期、时间、货币、百分比等等。NER技术可以帮助我们自动识别文本中的实体,从而更好地理解文本的含义和上下文。
NER技术在许多NLP应用程序中都有广泛的用途,例如信息提取、问答系统、机器翻译、文本分类、文本摘要等等。例如,在信息提取中,NER可以帮助我们自动识别文本中的人名、地名、组织名等实体,并将它们与其他信息(例如日期、时间、事件等)相关联,从而提取出有用的信息。在问答系统中,NER可以帮助我们自动识别问题中的实体,并将其与知识库中的信息相关联,从而回答问题。
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u'Can I please borrow 500 dollars from you to buy some Microsoft stock?')
for ent in doc.ents:
print(ent.text, ent.start, ent.end, ent.start_char, ent.end_char, ent.label_)
注意上面的start和stop是span,如果想看char,可以用start_char和end_char
输出如下:
500 dollars 4 6 20 31 MONEY Microsoft 11 12 53 62 ORG
_label的完整表如下:
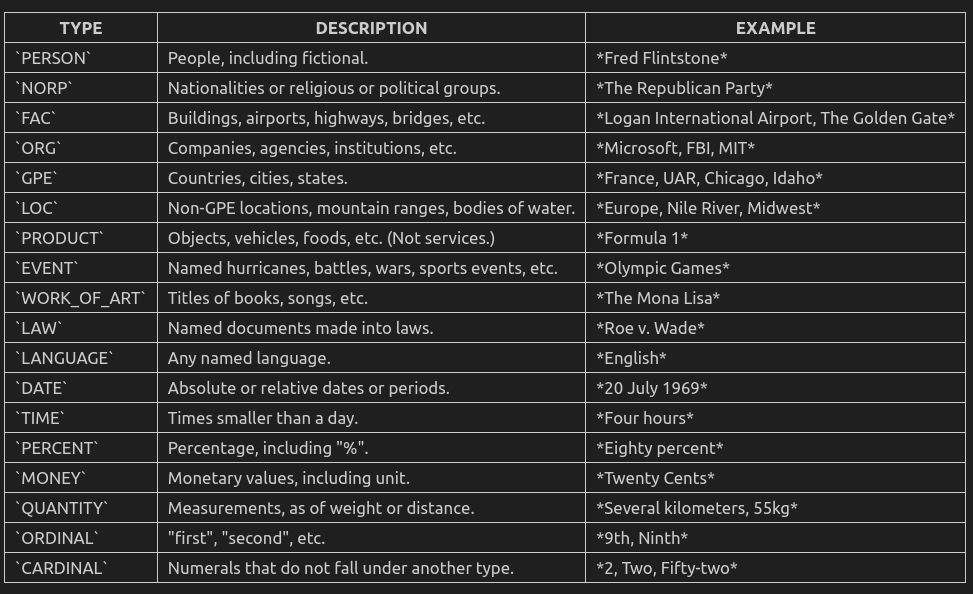
如果遇到NER在换行的问题,可以添加一个pipeline来修复:
def remove_whitespace_entities(doc):
doc.ents = [e for e in doc.ents if not e.text.isspace()]
return doc
nlp.add_pipe(remove_whitespace_entities, after='ner')
可视化:
from spacy import displacy
doc = nlp(u'Over the last quarter Apple sold nearly 20 thousand iPods for a profit of $6 million. '
u'By contrast, Sony sold only 7 thousand Walkman music players.')
for sent in doc.sents:
displacy.render(nlp(sent.text), style='ent', jupyter=True)
![]()
13 名词短语(Noun Chunk)
GitHub Copilot: 在自然语言处理(NLP)中,名词短语(noun chunk)是一个包含一个名词及其相关修饰语的短语。名词短语通常由一个名词作为短语的核心,其前面可能有限定词、形容词、副词等修饰语,后面可能有介词短语、从句等。
名词短语识别(noun chunking)是一种NLP技术,用于自动识别文本中的名词短语。名词短语识别通常是在词性标注和句法分析的基础上进行的。名词短语识别可以帮助我们更好地理解文本的含义和结构,从而支持许多NLP应用程序,例如信息提取、文本分类、文本摘要等。
doc = nlp(u"Autonomous cars shift insurance liability toward manufacturers.")
for chunk in doc.noun_chunks:
print(chunk.text+' - '+chunk.root.text+' - '+chunk.root.dep_+' - '+chunk.root.head.text)
输出:
Autonomous cars - cars - nsubj - shift insurance liability - liability - dobj - shift manufacturers - manufacturers - pobj - toward
14 句子分割(Sentence Segmentation)
doc = nlp(u'This is the first sentence. This is another sentence. This is the last sentence.')
for sent in doc.sents:
print(sent)
自定义分割规则:
def set_custom_boundaries(doc):
for token in doc[:-1]:
if token.text == ';':
doc[token.i+1].is_sent_start = True
return doc
nlp.add_pipe(set_custom_boundaries, before='parser')