转载自:http://www.infoq.com/articles/LuceneHbase
Search plays a pivotal role in just about any modern application from shopping sites to social networks to points of interest. Lucene search library is today's de facto standard for implementing search engines. It is used by Apple, IBM, Attlassian (Jira), Wolfram, pick your favorite company [1]. As a result, any implementation allowing for improving of Lucene's scalability and performance is of great interest.
Quick introduction to Lucene
Searchable entities in Lucene are represented as documents comprised of fields and their values. Every field value is comprised of one or more searchable elements - terms. Lucene search is based on inverted index containing information about searchable documents. Unlike normal indexes, where you can look up a document to know what fields it contains, in inverted index, you look up a field's term to know all the documents it appears in.
A high-level Lucene architecture [2] is presented at Figure 1. Its main components are IndexSearcher, IndexReader, IndexWriter and Directory. IndexSearcher implements the search logic. IndexWriter writes reverse indexes for each inserted document. IndexReader reads the content of indexes in support of IndexSearcher. Both IndexReader and IndexWriter rely on Directory, which provides APIs for manipulating index data sets, which are directly mimicking file system API.
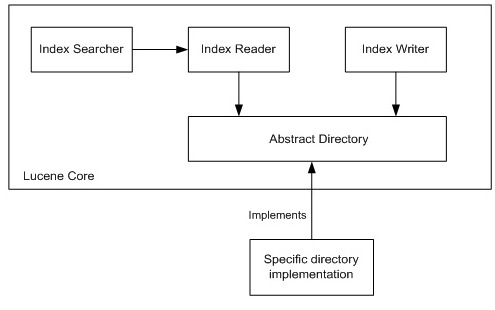
Figure 1: High-level Lucene architecture
The standard Lucene distribution contains several directory implementations, including file system -based and memory-based[1].
The drawback of a standard file system - based backend (directory implementation) is a performance degradation caused by the index growth. Different techniques were used to overcome this problem including load balancing and index sharding - splitting indexes between multiple Lucene instances. Although powerful, usage of sharding complicates overall implementation architecture and requires a certain amount of an apriory knowledge about expected documents to properly partition Lucene indexes.
A different approach is to allow an index backend itself to shard data correctly and build an implementation based on such a backend. One of such backend can be a noSQL database. In this article we will describe an implementation based on an HBase [4].
Implementation approach
As explained in [3], at a very high level, Lucene operates on 2 distinct data sets:
- Index data set keeps all the Field/Term pairs (with additional info like, term frequency, position etc.) and the documents containing these terms in appropriate fields.
- Document data set stores all the documents, including stored fields, etc.
As we have mentioned above, directly implementing directory interface is not always the simplest (most convenient) approach to port Lucene to a new backend. As a result, several Lucene ports, including a limited memory index support from Lucene contrib. module, Lucandra [5] and HBasene [6] took a different approach [2] and overwrote not a directory but higher level Lucene's classes - IndexReader and IndexWriter, thus bypassing Directory APIs (Figure 2).
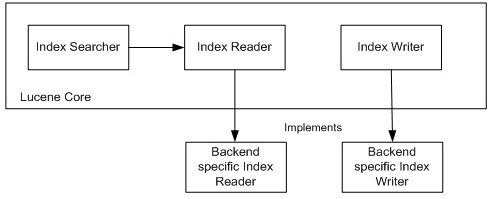
Figure 2: Integration Lucene with back end without file system
Although such approach often requires more work [2], it leads to significantly more powerful implementations allowing for full utilization of back end's native capabilities.
The implementation[2] presented in the article follows this approach.
Overall Architecture
The overall implementation (Figure 3) is based on a memory-based backend used as an in memory cache and a mechanism for synchronizing this cache with the HBase backend.
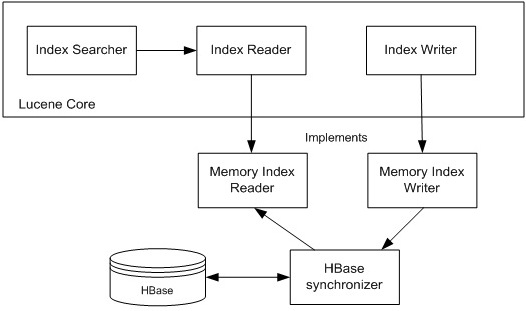
Figure 3: Overall Architecture of HBase-based Lucene implementation
The implementation tries to balance two conflicting requirements - performance: in memory cache can drastically improve performance by minimizing the amount of HBase reads for search and documents retrieval; and scalability: ability to run as many Lucene instances as required to support growing search clients population. The latter requires minimizing of the cache life time to synchronize content with the HBase instance (a single copy of thruth). A compromise is achieved through implementing configurable cache time to live parameter, limiting cache presence in each Lucene instance.
Underlying data model for in memory cache
As mentioned before, internal Lucene data model is based on two main data sets – Index and documents, which are implemented as two models – IndexMemoryModel and DocumentMemoryModel. In our implementation both reads and writes (IndexReader/IndexWriter) are done through the memory cache, but their implementation is very different. For reads, the cache first checks if the required data is in memory and is not stale[3] and if it is uses it directly. Otherwise the cache reads/refreshes data from HBase and then returns it to the IndexReader. For writes, on another hand, the data is written directly to the HBase without storing it in memory. Although this might create a delay in the actual data availability, it makes implementation significantly simpler – we do not need to worry which caches to deliver new/updated data. This delay can be controlled, to adhere to the business requirements, by setting an appropriate cache expiration time.
IndexMemoryModel
The class diagram for index memory model is presented at Figure 4.
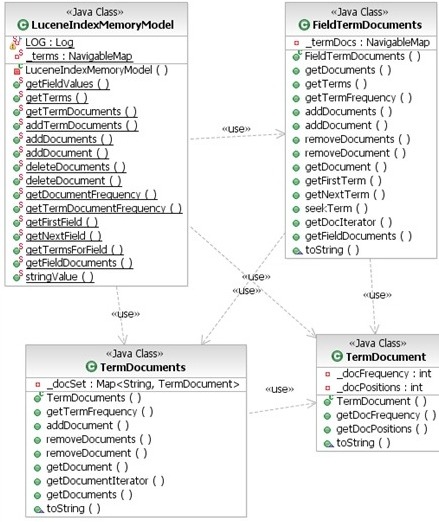
Figure 4: IndexMemoryModel class diagram
In this implementation:
- LuceneIndexMemoryModel class contains FieldTermDocuments class for every field currently present in memory. It also provides all of the internal APIs necessary for implementation of IndexReader/IndexWriter.
- FieldTermDocuments class manages TermDocuments for every field value. Typically for a scannable database list of fields and list of field values are combined in one navigable list of (field/term values). For memory-based cache implementation we have split them into two separate maps to make search times more predictable.
- TermDocuments class contains a list of TermDocument class for every document ID.
- TermDocument class contains information stored in index for a given document - document frequency and array of positions.
DocumentMemoryModel
A class diagram for the document memory model is presented at Figure 5
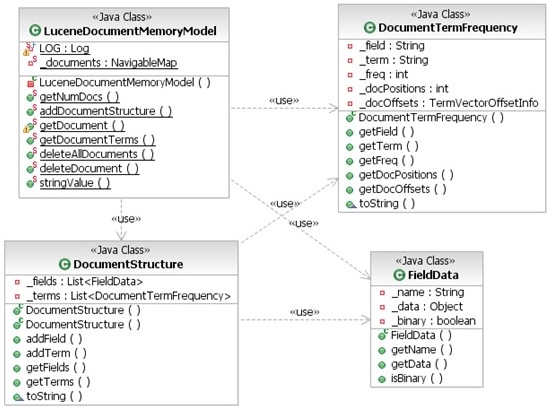
Figure 5: DocumentMemoryModel class diagram
In this implementation:
- LuceneDocumentMemoryModel class contains a map of DocumentStructure class for every indexed document.
- DocumentStructure class contains information about a single document. For every document it contains a list of saved fields and information about each indexed field.
- FieldData class contains information saved for stored field, including field name, value and binary/string flag.
- DocumentTermFrequency class contains information about each indexed field including a back reference to corresponding index structure (field, term) term frequency in the document, positions of the term in the documents and offsets from the beginning of the document.
LuceneDocumentNormMemoryModel
As explained in [9] norms are used to represent document/field's boost factor, thus providing for better search results ranking at the expense of using significant amount of memory. Class implementation is based on map of maps, where the inner map stores a norm for a document, while the outer one stores a norm map for a field.
Although norm's information is keyed by field name and thus can be appended to LuceneIndexMemoryModel class we decided to implement norms management as a separate class - LuceneDocumentNormMemoryModel. The reason for this is that usage of norms in Lucene is optional.
IndexWriter
With underlying memory model, described above, implementation of index writer is fairly straightforward. Because Lucene does not define IndexWriter interface we had to implement IndexWriter by implementing all of the methods that exist in the standard Lucene implementation. The workhorse of this class is addDocument method. This method iterates through all document's fields. For every field, the method checks whether it should be tokenized and uses specified analyzer to do so. This method also updates all three memory structures - index, document and (optionally) norm storing information for an added document.
IndexReader
IndexReader implements IndexReader interface provided by Lucene core. Because list gets in Hbase are much faster compared to individual reads we extended this class with the method, allowing to read multiple documents.The class itself does not do much outsourcing most of the processing to several classes, which it manages:
- While document ID is typically a string, Lucene internally operates on integers. A class DocIDManager is responsible for string to number translation management. This class is used by IndexReader in the form of ThreadLocalStorage, allowing for automatic clean up as the thread ends.
- MemoryTermEnum class extends TermEnum class provided by Lucene and is responsible for scanning through field/term values.
- MemoryTermFrequencyVector class implements interfaces TermDocs and TermPositions provided by Lucene and is responsible for processing information about documents for a given field/term pair.
- MemoryTermFrequencyVector class implements interfaces TermFreqVector and TermPositionVector provided by Lucene and is responsible for returning back information about frequencies and positions of documents' fields for given documents IDs
HBase tables
Proposed solution is based on two main HBase tables - Index table (Figure 6) and document table (Figure 7).
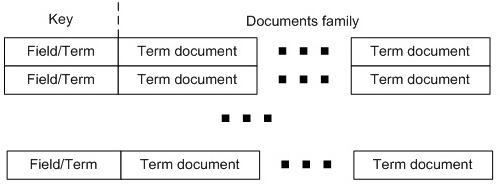
Figure 6: Hbase Index table
(Click on the image to enlarge it)

Figure 7: HBase document tale
An optional third table (Figure 8) can be implemented if Lucene norms need to be supported.
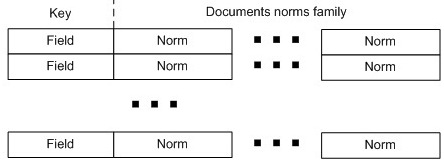
Figure 8: HBase norm table
HBase index table (Figure 6) is the workhorse of the implementation. This table has an entry (row) for every field/term combination known to a Lucene instance, which contains one column family - documents family. This column family contains a column (named as a document ID) for every document containing this field/term. The content of each column is a value of TermDocument class.
HBase document table (Figure 7) stores documents themselves, back references to the indexes/norms, referencing these documents and some additional bookkeeping information used by Lucene for documents processing. It has an entry (row) for every document known to a Lucene instance. Each document is uniquely identified by a document ID (key) and contains two column families - fields family and index family. Fields column family contains a column (named as a field name) for every document's field stored by Lucene. The column value is comprised of the value type (string or byte array) and the value itself. Index column family contains a column (named as a field/term) for every index referencing this document. The column value include document frequency, positions and offsets for a given field/term.
HBase norm table (Figure 8) stores document norms for every field. It has an entry (row) for every field (key) known to a Lucene instance. Each row contains a single column family - norms family. This family has a column (named as document ID) for every document for which a given field's norm needs to be stored.
Data formats
A final design decision is determining data formats for storing data in HBase. For this implementation we have chosen Avro [10] based on its performance, minimal size of resulting data and tight integration with Hadoop.
The main data structures used by implementation are TermDocument (Listing 1), Document's FieldData (Listing 2) and DocumentTermFrequency (Listing 3)
{
"type" : "record",
"name" : "TermDocument",
"namespace" : "com.navteq.lucene.hbase.document",
"fields" : [ {
"name" : "docFrequency",
"type" : "int"
}, {
"name" : "docPositions",
"type" : ["null", {
"type" : "array",
"items" : "int"
}]
} ]
}
Listing 1 Term Document AVRO definition
{
"type" : "record",
"name" : "FieldsData",
"namespace" : "com.navteq.lucene.hbase.document",
"fields" : [ {
"name" : "fieldsArray",
"type" : {
"type" : "array",
"items" : {
"type" : "record",
"name" : "singleField",
"fields" : [ {
"name" : "binary",
"type" : "boolean"
}, {
"name" : "data",
"type" : [ "string", "bytes" ]
} ]
}
}
} ]
}
Listing 2 Field data AVRO definition
{
"type" : "record",
"name" : "TermDocumentFrequency",
"namespace" : "com.navteq.lucene.hbase.document",
"fields" : [ {
"name" : "docFrequency",
"type" : "int"
}, {
"name" : "docPositions",
"type" : ["null",{
"type" : "array",
"items" : "int"
}]
}, {
"name" : "docOffsets",
"type" : ["null",{
"type" : "array",
"items" : {
"type" : "record",
"name" : "TermsOffset",
"fields" : [ {
"name" : "startOffset",
"type" : "int"
}, {
"name" : "endOffset",
"type" : "int"
} ]
}
}]
} ]
}
Listing 3 TermDocumentFrequency AVRO definition
Conclusion
The simple implementation, described in this paper fully supports all of the Lucene functionality as validated by many unit tests from both Lucene core and contrib modules. It can be used as a foundation of building a very scalable search implementation leveraging inherent scalability of HBase and its fully symmetric design, allowing for adding any number of processes serving HBase data. It also avoids the necessity to close an open Lucene Index reader to incorporate newly indexed data, which will be automatically available to user with possible delay controlled by the cache time to live parameter. In the next article we will show how to extend this implementation to incorporate geospatial search support.
About the Authors
Boris Lublinsky is principal architect at NAVTEQ, where he is working on defining architecture vision for large data management and processing and SOA and implementing various NAVTEQ projects. He is also an SOA editor for InfoQ and a participant of SOA RA working group in OASIS. Boris is an author and frequent speaker, his most recent book "Applied SOA".
Michael Segel has spent the past 20+ years working with customers identifying and solving their business problems. Michael has worked in multiple roles, in multiple industries. He is an independent consultant who is always looking to solve any challenging problems. Michael has a Software Engineering degree from the Ohio State University.
References
2. Animesh Kumar. Apache Lucene and Cassandra
3. Animesh Kumar. Lucandra - an inside story!
9. Michael McCandless, Erik Hatcher, Otis Gospodnetic. Lucene in Action, Second Edition.
10. Boris Lublinsky. Using Apache Avro.
[1] Additionally Lucene contrib contains DB directory build for Berkley DB.
[2] This implementation is inspired by Lusandra source code [3]
[3] Has not been in memory too long
nice info to sharing
this is really a solution for search document fastly..
thanks for sharing. nice info
What is the purpose of IndexReader in Lucene?
How does Directory support the functionality of both IndexReader and IndexWriter in Lucene?
Telkom University
What is the significance of Lucene search library in modern applications, and why is improving its scalability and performance important, according to the text?
telkom university