- 基础Tensor(张量)操作
TODO - 创建线性(玩具)数据集
import torchfrom torch import nnimport matplotlib.pyplot as pltdevice = "cuda" if torch.cuda.is_available() else "cpu"print(device)# create dataweight = 0.6bias = 0.4start = 0end = 1step = 0.01X = torch.arange(start, end, step).unsqueeze(dim=1)y = weight * X + biasX[:10], y[:10]train_split = int(0.8 * len(X))X_train, y_train = X[:train_split], y[:train_split]X_test, y_test = X[train_split:], y[train_split:]import torch from torch import nn import matplotlib.pyplot as plt device = "cuda" if torch.cuda.is_available() else "cpu" print(device) # create data weight = 0.6 bias = 0.4 start = 0 end = 1 step = 0.01 X = torch.arange(start, end, step).unsqueeze(dim=1) y = weight * X + bias X[:10], y[:10] train_split = int(0.8 * len(X)) X_train, y_train = X[:train_split], y[:train_split] X_test, y_test = X[train_split:], y[train_split:]
import torch from torch import nn import matplotlib.pyplot as plt device = "cuda" if torch.cuda.is_available() else "cpu" print(device) # create data weight = 0.6 bias = 0.4 start = 0 end = 1 step = 0.01 X = torch.arange(start, end, step).unsqueeze(dim=1) y = weight * X + bias X[:10], y[:10] train_split = int(0.8 * len(X)) X_train, y_train = X[:train_split], y[:train_split] X_test, y_test = X[train_split:], y[train_split:]
- 回归模型实现线性数据集的拟合
# modelclass LinearRegressionModel(nn.Module):def __init__(self):super().__init__()self.linear_layer = nn.Linear(in_features=1, out_features=1)def forward(self, x: torch.Tensor) -> torch.Tensor:return self.linear_layer(x)# trainmodel_2 = LinearRegressionModel()model_2, model_2.state_dict()model_2.to(device)# gpu if availabledevice = "cuda" if torch.cuda.is_available() else "cpu"loss_fn = nn.L1Loss()optimizer = torch.optim.SGD(params=model_2.parameters(), lr=0.01)epochs = 500X_train = X_train.to(device)X_test = X_test.to(device)y_train = y_train.to(device)y_test = y_test.to(device)for epoch in range(epochs):model_2.train()y_pred = model_2(X_train)loss = loss_fn(y_pred, y_train)optimizer.zero_grad()loss.backward()optimizer.step()model_2.eval()with torch.inference_mode():test_pred = model_2(X_test)test_loss = loss_fn(test_pred, y_test)print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}")# predictmodel_2.eval()with torch.inference_mode():# X_test = X_test.to(device)y_preds = model_0(X_test)y_preds# save modelMODEL_SAVE_PATH = "./models/model_2.pth"torch.save(obj=model_2.state_dict(), f=MODEL_SAVE_PATH)# load modelmodel_l = LinearRegressionModel()model_l.load_state_dict(torch.load(f=MODEL_SAVE_PATH))# model class LinearRegressionModel(nn.Module): def __init__(self): super().__init__() self.linear_layer = nn.Linear(in_features=1, out_features=1) def forward(self, x: torch.Tensor) -> torch.Tensor: return self.linear_layer(x) # train model_2 = LinearRegressionModel() model_2, model_2.state_dict() model_2.to(device) # gpu if available device = "cuda" if torch.cuda.is_available() else "cpu" loss_fn = nn.L1Loss() optimizer = torch.optim.SGD(params=model_2.parameters(), lr=0.01) epochs = 500 X_train = X_train.to(device) X_test = X_test.to(device) y_train = y_train.to(device) y_test = y_test.to(device) for epoch in range(epochs): model_2.train() y_pred = model_2(X_train) loss = loss_fn(y_pred, y_train) optimizer.zero_grad() loss.backward() optimizer.step() model_2.eval() with torch.inference_mode(): test_pred = model_2(X_test) test_loss = loss_fn(test_pred, y_test) print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}") # predict model_2.eval() with torch.inference_mode(): # X_test = X_test.to(device) y_preds = model_0(X_test) y_preds # save model MODEL_SAVE_PATH = "./models/model_2.pth" torch.save(obj=model_2.state_dict(), f=MODEL_SAVE_PATH) # load model model_l = LinearRegressionModel() model_l.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# model class LinearRegressionModel(nn.Module): def __init__(self): super().__init__() self.linear_layer = nn.Linear(in_features=1, out_features=1) def forward(self, x: torch.Tensor) -> torch.Tensor: return self.linear_layer(x) # train model_2 = LinearRegressionModel() model_2, model_2.state_dict() model_2.to(device) # gpu if available device = "cuda" if torch.cuda.is_available() else "cpu" loss_fn = nn.L1Loss() optimizer = torch.optim.SGD(params=model_2.parameters(), lr=0.01) epochs = 500 X_train = X_train.to(device) X_test = X_test.to(device) y_train = y_train.to(device) y_test = y_test.to(device) for epoch in range(epochs): model_2.train() y_pred = model_2(X_train) loss = loss_fn(y_pred, y_train) optimizer.zero_grad() loss.backward() optimizer.step() model_2.eval() with torch.inference_mode(): test_pred = model_2(X_test) test_loss = loss_fn(test_pred, y_test) print(f"Epoch: {epoch} | Train loss: {loss} | Test loss: {test_loss}") # predict model_2.eval() with torch.inference_mode(): # X_test = X_test.to(device) y_preds = model_0(X_test) y_preds # save model MODEL_SAVE_PATH = "./models/model_2.pth" torch.save(obj=model_2.state_dict(), f=MODEL_SAVE_PATH) # load model model_l = LinearRegressionModel() model_l.load_state_dict(torch.load(f=MODEL_SAVE_PATH)) - 构建非线性(玩具)数据集合
from sklearn.datasets import make_circlesn_samples = 1000X, y = make_circles(n_samples, noise=0.05)print(f"First 5 features:n{X[:5]}")print(f"First 5 labels:n{y[:5]}")import pandas as pdcircles = pd.DataFrame({"X1": X[:, 0],"X2": X[:, 1],"label": y})circles.head(10)circles.label.value_counts()import matplotlib.pyplot as pltplt.scatter(x=circles.X1, y=circles.X2, c=circles.label, cmap=plt.cm.RdYlBu)import torchX = torch.from_numpy(X).type(torch.float)y = torch.from_numpy(y).type(torch.float)X[:5], y[:5]from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# send to devicedevice = "cuda" if torch.cuda.is_available() else "cpu"print(device)X_train_d = X_train.to(device)X_test_d = X_test.to(device)y_train_d = y_train.to(device)y_test_d = y_test.to(device)from sklearn.datasets import make_circles n_samples = 1000 X, y = make_circles(n_samples, noise=0.05) print(f"First 5 features:n{X[:5]}") print(f"First 5 labels:n{y[:5]}") import pandas as pd circles = pd.DataFrame({ "X1": X[:, 0], "X2": X[:, 1], "label": y }) circles.head(10) circles.label.value_counts() import matplotlib.pyplot as plt plt.scatter(x=circles.X1, y=circles.X2, c=circles.label, cmap=plt.cm.RdYlBu) import torch X = torch.from_numpy(X).type(torch.float) y = torch.from_numpy(y).type(torch.float) X[:5], y[:5] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # send to device device = "cuda" if torch.cuda.is_available() else "cpu" print(device) X_train_d = X_train.to(device) X_test_d = X_test.to(device) y_train_d = y_train.to(device) y_test_d = y_test.to(device)
from sklearn.datasets import make_circles n_samples = 1000 X, y = make_circles(n_samples, noise=0.05) print(f"First 5 features:n{X[:5]}") print(f"First 5 labels:n{y[:5]}") import pandas as pd circles = pd.DataFrame({ "X1": X[:, 0], "X2": X[:, 1], "label": y }) circles.head(10) circles.label.value_counts() import matplotlib.pyplot as plt plt.scatter(x=circles.X1, y=circles.X2, c=circles.label, cmap=plt.cm.RdYlBu) import torch X = torch.from_numpy(X).type(torch.float) y = torch.from_numpy(y).type(torch.float) X[:5], y[:5] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # send to device device = "cuda" if torch.cuda.is_available() else "cpu" print(device) X_train_d = X_train.to(device) X_test_d = X_test.to(device) y_train_d = y_train.to(device) y_test_d = y_test.to(device) - 训练非线性模型
利用ReLU引入非线性学习能力,损失函数是BCEWithLogitsLossfrom torch import nnclass CircleModel(nn.Module):def __init__(self):super().__init__()self.layer = nn.Sequential(nn.Linear(in_features=2, out_features=16),nn.ReLU(),nn.Linear(in_features=16, out_features=128),nn.ReLU(),nn.Linear(in_features=128, out_features=16),nn.ReLU(),nn.Linear(in_features=16, out_features=1),)def forward(self, X):return self.layer(X)model_c = CircleModel().to(device)loss_fn = nn.BCEWithLogitsLoss()optimizer = torch.optim.SGD(params=model_c.parameters(), lr = 0.05)def accuracy_fn(y_true, y_pred):correct = torch.eq(y_true, y_pred).sum().item() # torch.eq() calculates where two tensors are equalacc = (correct / len(y_pred)) * 100return accepochs = 2000for epoch in range(epochs):# 1. forwardy_logits = model_c(X_train_d).squeeze()y_pred = torch.round(torch.sigmoid(y_logits))# 2. loss and accloss = loss_fn(y_logits, y_train_d)acc = accuracy_fn(y_true=y_train_d, y_pred=y_pred)# 3. Optimizer zero gradoptimizer.zero_grad()# 4. Loss backwardsloss.backward()# 5. Optimizer stepoptimizer.step()# Testingmodel_c.eval()with torch.inference_mode():test_logits = model_c(X_test_d).squeeze()test_pred = torch.round(torch.sigmoid(test_logits))test_loss = loss_fn(test_logits, y_test_d)test_acc = accuracy_fn(y_true=y_test_d, y_pred=test_pred)if epoch % 10 == 0 or epoch == epochs:print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")from torch import nn class CircleModel(nn.Module): def __init__(self): super().__init__() self.layer = nn.Sequential( nn.Linear(in_features=2, out_features=16), nn.ReLU(), nn.Linear(in_features=16, out_features=128), nn.ReLU(), nn.Linear(in_features=128, out_features=16), nn.ReLU(), nn.Linear(in_features=16, out_features=1), ) def forward(self, X): return self.layer(X) model_c = CircleModel().to(device) loss_fn = nn.BCEWithLogitsLoss() optimizer = torch.optim.SGD(params=model_c.parameters(), lr = 0.05) def accuracy_fn(y_true, y_pred): correct = torch.eq(y_true, y_pred).sum().item() # torch.eq() calculates where two tensors are equal acc = (correct / len(y_pred)) * 100 return acc epochs = 2000 for epoch in range(epochs): # 1. forward y_logits = model_c(X_train_d).squeeze() y_pred = torch.round(torch.sigmoid(y_logits)) # 2. loss and acc loss = loss_fn(y_logits, y_train_d) acc = accuracy_fn(y_true=y_train_d, y_pred=y_pred) # 3. Optimizer zero grad optimizer.zero_grad() # 4. Loss backwards loss.backward() # 5. Optimizer step optimizer.step() # Testing model_c.eval() with torch.inference_mode(): test_logits = model_c(X_test_d).squeeze() test_pred = torch.round(torch.sigmoid(test_logits)) test_loss = loss_fn(test_logits, y_test_d) test_acc = accuracy_fn(y_true=y_test_d, y_pred=test_pred) if epoch % 10 == 0 or epoch == epochs: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%")from torch import nn class CircleModel(nn.Module): def __init__(self): super().__init__() self.layer = nn.Sequential( nn.Linear(in_features=2, out_features=16), nn.ReLU(), nn.Linear(in_features=16, out_features=128), nn.ReLU(), nn.Linear(in_features=128, out_features=16), nn.ReLU(), nn.Linear(in_features=16, out_features=1), ) def forward(self, X): return self.layer(X) model_c = CircleModel().to(device) loss_fn = nn.BCEWithLogitsLoss() optimizer = torch.optim.SGD(params=model_c.parameters(), lr = 0.05) def accuracy_fn(y_true, y_pred): correct = torch.eq(y_true, y_pred).sum().item() # torch.eq() calculates where two tensors are equal acc = (correct / len(y_pred)) * 100 return acc epochs = 2000 for epoch in range(epochs): # 1. forward y_logits = model_c(X_train_d).squeeze() y_pred = torch.round(torch.sigmoid(y_logits)) # 2. loss and acc loss = loss_fn(y_logits, y_train_d) acc = accuracy_fn(y_true=y_train_d, y_pred=y_pred) # 3. Optimizer zero grad optimizer.zero_grad() # 4. Loss backwards loss.backward() # 5. Optimizer step optimizer.step() # Testing model_c.eval() with torch.inference_mode(): test_logits = model_c(X_test_d).squeeze() test_pred = torch.round(torch.sigmoid(test_logits)) test_loss = loss_fn(test_logits, y_test_d) test_acc = accuracy_fn(y_true=y_test_d, y_pred=test_pred) if epoch % 10 == 0 or epoch == epochs: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Accuracy: {acc:.2f}% | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%") - 生成二维(玩具)数据集
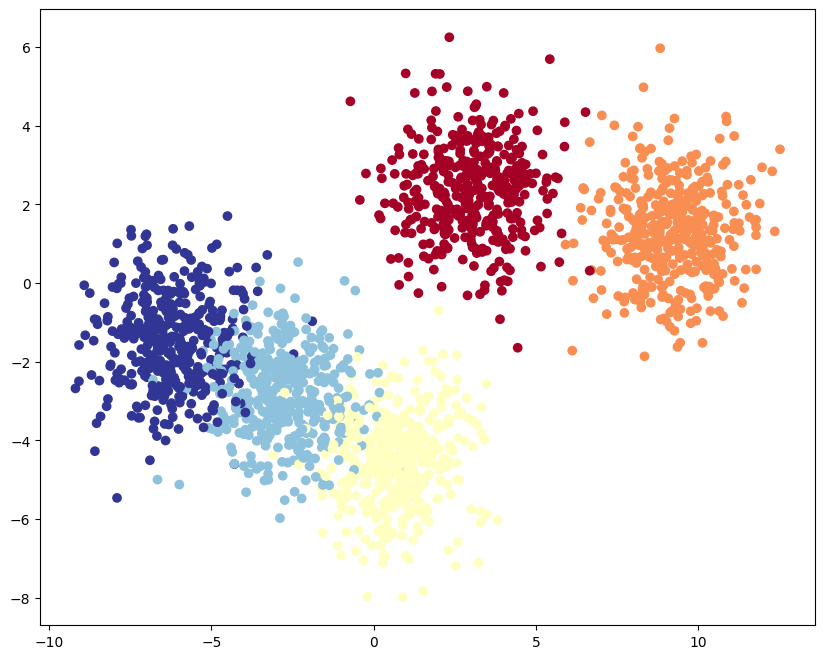
from sklearn.datasets import make_blobsfrom sklearn.model_selection import train_test_splitimport torchimport matplotlib.pyplot as pltSAMPLES = 2000FEATURES = 2CLASSES = 5X_blob, y_blob = make_blobs(n_samples = SAMPLES, n_features = FEATURES, centers = CLASSES, cluster_std = 1.2)X_blob = torch.from_numpy(X_blob).type(torch.float)y_blob = torch.from_numpy(y_blob).type(torch.LongTensor)print(X_blob[:5], y_blob[:5])# train / testX_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob, y_blob, test_size = 0.3)# figureplt.figure(figsize=(10, 8))plt.scatter(X_blob[:,0], X_blob[:,1], c=y_blob, cmap=plt.cm.RdYlBu)from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split import torch import matplotlib.pyplot as plt SAMPLES = 2000 FEATURES = 2 CLASSES = 5 X_blob, y_blob = make_blobs(n_samples = SAMPLES, n_features = FEATURES, centers = CLASSES, cluster_std = 1.2) X_blob = torch.from_numpy(X_blob).type(torch.float) y_blob = torch.from_numpy(y_blob).type(torch.LongTensor) print(X_blob[:5], y_blob[:5]) # train / test X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob, y_blob, test_size = 0.3) # figure plt.figure(figsize=(10, 8)) plt.scatter(X_blob[:,0], X_blob[:,1], c=y_blob, cmap=plt.cm.RdYlBu)
from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split import torch import matplotlib.pyplot as plt SAMPLES = 2000 FEATURES = 2 CLASSES = 5 X_blob, y_blob = make_blobs(n_samples = SAMPLES, n_features = FEATURES, centers = CLASSES, cluster_std = 1.2) X_blob = torch.from_numpy(X_blob).type(torch.float) y_blob = torch.from_numpy(y_blob).type(torch.LongTensor) print(X_blob[:5], y_blob[:5]) # train / test X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob, y_blob, test_size = 0.3) # figure plt.figure(figsize=(10, 8)) plt.scatter(X_blob[:,0], X_blob[:,1], c=y_blob, cmap=plt.cm.RdYlBu)
- 多分类器
相对较二分类问题,多分类问题需要使用损失函数(CrossEntropyLoss)、可用优化器(Adam)、使用torchmetrics计算准确率from torch import nnclass BlobModel(nn.Module):def __init__(self, input_features, output_features, hidden_units=32):super().__init__()self.layer = nn.Sequential(nn.Linear(in_features = input_features, out_features=hidden_units * 2),nn.ReLU(),nn.Linear(in_features = hidden_units * 2, out_features=hidden_units * 4),nn.ReLU(),nn.Linear(in_features = hidden_units * 4, out_features=hidden_units),nn.ReLU(),nn.Linear(in_features = hidden_units, out_features=output_features))def forward(self, x):return self.layer(x)try:from torchmetrics import Accuracyexcept:!pip install torchmetricsfrom torchmetrics import Accuracymodel_b = BlobModel(input_features = FEATURES, output_features = CLASSES).to(device)loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model_b.parameters(), lr=0.01)torchmetrics_accuracy = Accuracy(task='multiclass', num_classes=CLASSES).to(device)epochs = 200for epoch in range(epochs):### Trainingmodel_b.train()# 1. Forward passy_logits = model_b(X_blob_train) # model outputs raw logitsy_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # go from logits -> prediction probabilities -> prediction labels# print(y_logits)# 2. Calculate loss and accuracyloss = loss_fn(y_logits, y_blob_train)acc = torchmetrics_accuracy(y_pred, y_blob_train) * 100# 3. Optimizer zero gradoptimizer.zero_grad()# 4. Loss backwardsloss.backward()# 5. Optimizer stepoptimizer.step()### Testingmodel_b.eval()with torch.inference_mode():# 1. Forward passtest_logits = model_b(X_blob_test)test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1)# 2. Calculate test loss and accuracytest_loss = loss_fn(test_logits, y_blob_test)test_acc = torchmetrics_accuracy(test_pred, y_blob_test) * 100# Print out what's happeningif epoch % 10 == 0 or epoch == epochs:print(f"Epoch: {epoch} | Loss: {loss:.5f}, Acc: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Acc: {test_acc:.2f}%")from torch import nn class BlobModel(nn.Module): def __init__(self, input_features, output_features, hidden_units=32): super().__init__() self.layer = nn.Sequential( nn.Linear(in_features = input_features, out_features=hidden_units * 2), nn.ReLU(), nn.Linear(in_features = hidden_units * 2, out_features=hidden_units * 4), nn.ReLU(), nn.Linear(in_features = hidden_units * 4, out_features=hidden_units), nn.ReLU(), nn.Linear(in_features = hidden_units, out_features=output_features) ) def forward(self, x): return self.layer(x) try: from torchmetrics import Accuracy except: !pip install torchmetrics from torchmetrics import Accuracy model_b = BlobModel(input_features = FEATURES, output_features = CLASSES).to(device) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model_b.parameters(), lr=0.01) torchmetrics_accuracy = Accuracy(task='multiclass', num_classes=CLASSES).to(device) epochs = 200 for epoch in range(epochs): ### Training model_b.train() # 1. Forward pass y_logits = model_b(X_blob_train) # model outputs raw logits y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # go from logits -> prediction probabilities -> prediction labels # print(y_logits) # 2. Calculate loss and accuracy loss = loss_fn(y_logits, y_blob_train) acc = torchmetrics_accuracy(y_pred, y_blob_train) * 100 # 3. Optimizer zero grad optimizer.zero_grad() # 4. Loss backwards loss.backward() # 5. Optimizer step optimizer.step() ### Testing model_b.eval() with torch.inference_mode(): # 1. Forward pass test_logits = model_b(X_blob_test) test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1) # 2. Calculate test loss and accuracy test_loss = loss_fn(test_logits, y_blob_test) test_acc = torchmetrics_accuracy(test_pred, y_blob_test) * 100 # Print out what's happening if epoch % 10 == 0 or epoch == epochs: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Acc: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Acc: {test_acc:.2f}%")from torch import nn class BlobModel(nn.Module): def __init__(self, input_features, output_features, hidden_units=32): super().__init__() self.layer = nn.Sequential( nn.Linear(in_features = input_features, out_features=hidden_units * 2), nn.ReLU(), nn.Linear(in_features = hidden_units * 2, out_features=hidden_units * 4), nn.ReLU(), nn.Linear(in_features = hidden_units * 4, out_features=hidden_units), nn.ReLU(), nn.Linear(in_features = hidden_units, out_features=output_features) ) def forward(self, x): return self.layer(x) try: from torchmetrics import Accuracy except: !pip install torchmetrics from torchmetrics import Accuracy model_b = BlobModel(input_features = FEATURES, output_features = CLASSES).to(device) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model_b.parameters(), lr=0.01) torchmetrics_accuracy = Accuracy(task='multiclass', num_classes=CLASSES).to(device) epochs = 200 for epoch in range(epochs): ### Training model_b.train() # 1. Forward pass y_logits = model_b(X_blob_train) # model outputs raw logits y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # go from logits -> prediction probabilities -> prediction labels # print(y_logits) # 2. Calculate loss and accuracy loss = loss_fn(y_logits, y_blob_train) acc = torchmetrics_accuracy(y_pred, y_blob_train) * 100 # 3. Optimizer zero grad optimizer.zero_grad() # 4. Loss backwards loss.backward() # 5. Optimizer step optimizer.step() ### Testing model_b.eval() with torch.inference_mode(): # 1. Forward pass test_logits = model_b(X_blob_test) test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1) # 2. Calculate test loss and accuracy test_loss = loss_fn(test_logits, y_blob_test) test_acc = torchmetrics_accuracy(test_pred, y_blob_test) * 100 # Print out what's happening if epoch % 10 == 0 or epoch == epochs: print(f"Epoch: {epoch} | Loss: {loss:.5f}, Acc: {acc:.2f}% | Test Loss: {test_loss:.5f}, Test Acc: {test_acc:.2f}%") - 打印模型边界
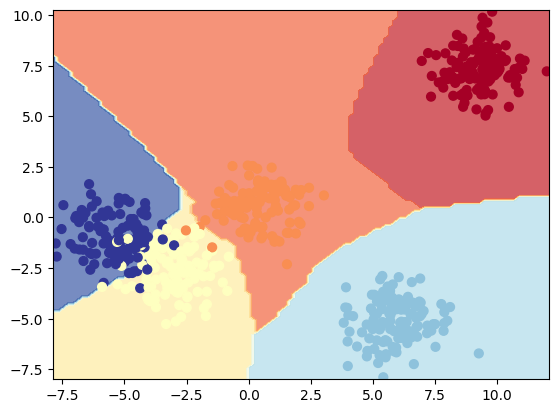
更多好用的函数在这里 https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.pydef plot_decision_boundary(model: torch.nn.Module, X: torch.Tensor, y: torch.Tensor):"""Plots decision boundaries of model predicting on X in comparison to y.Source - https://madewithml.com/courses/foundations/neural-networks/ (with modifications)"""# Put everything to CPU (works better with NumPy + Matplotlib)model.to("cpu")X, y = X.to("cpu"), y.to("cpu")# Setup prediction boundaries and gridx_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))# Make featuresX_to_pred_on = torch.from_numpy(np.column_stack((xx.ravel(), yy.ravel()))).float()# Make predictionsmodel.eval()with torch.inference_mode():y_logits = model(X_to_pred_on)# Test for multi-class or binary and adjust logits to prediction labelsif len(torch.unique(y)) > 2:y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # mutli-classelse:y_pred = torch.round(torch.sigmoid(y_logits)) # binary# Reshape preds and ploty_pred = y_pred.reshape(xx.shape).detach().numpy()plt.contourf(xx, yy, y_pred, cmap=plt.cm.RdYlBu, alpha=0.7)plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())def plot_decision_boundary(model: torch.nn.Module, X: torch.Tensor, y: torch.Tensor): """Plots decision boundaries of model predicting on X in comparison to y. Source - https://madewithml.com/courses/foundations/neural-networks/ (with modifications) """ # Put everything to CPU (works better with NumPy + Matplotlib) model.to("cpu") X, y = X.to("cpu"), y.to("cpu") # Setup prediction boundaries and grid x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1 y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101)) # Make features X_to_pred_on = torch.from_numpy(np.column_stack((xx.ravel(), yy.ravel()))).float() # Make predictions model.eval() with torch.inference_mode(): y_logits = model(X_to_pred_on) # Test for multi-class or binary and adjust logits to prediction labels if len(torch.unique(y)) > 2: y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # mutli-class else: y_pred = torch.round(torch.sigmoid(y_logits)) # binary # Reshape preds and plot y_pred = y_pred.reshape(xx.shape).detach().numpy() plt.contourf(xx, yy, y_pred, cmap=plt.cm.RdYlBu, alpha=0.7) plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max())def plot_decision_boundary(model: torch.nn.Module, X: torch.Tensor, y: torch.Tensor): """Plots decision boundaries of model predicting on X in comparison to y. Source - https://madewithml.com/courses/foundations/neural-networks/ (with modifications) """ # Put everything to CPU (works better with NumPy + Matplotlib) model.to("cpu") X, y = X.to("cpu"), y.to("cpu") # Setup prediction boundaries and grid x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1 y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1 xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101)) # Make features X_to_pred_on = torch.from_numpy(np.column_stack((xx.ravel(), yy.ravel()))).float() # Make predictions model.eval() with torch.inference_mode(): y_logits = model(X_to_pred_on) # Test for multi-class or binary and adjust logits to prediction labels if len(torch.unique(y)) > 2: y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # mutli-class else: y_pred = torch.round(torch.sigmoid(y_logits)) # binary # Reshape preds and plot y_pred = y_pred.reshape(xx.shape).detach().numpy() plt.contourf(xx, yy, y_pred, cmap=plt.cm.RdYlBu, alpha=0.7) plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max())plot_decision_boundary(model_b, X_blob_test, y_blob_test)plot_decision_boundary(model_b, X_blob_test, y_blob_test)plot_decision_boundary(model_b, X_blob_test, y_blob_test)
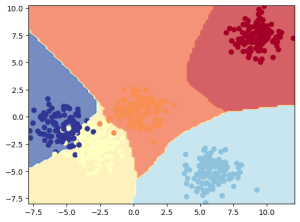
- 加载pyTorch的内置数据集合
import torchfrom torch import nnimport torchvisionfrom torchvision import datasetsfrom torchvision.transforms import ToTensorimport matplotlib.pyplot as plttrain_data = datasets.FashionMNIST(root = "data",train=True,download=True,transform=ToTensor(),target_transform=None)test_data = datasets.FashionMNIST(root = "data",train=False,download=True,transform=ToTensor())image, label = train_data[0]image.shape, labelimport torch from torch import nn import torchvision from torchvision import datasets from torchvision.transforms import ToTensor import matplotlib.pyplot as plt train_data = datasets.FashionMNIST( root = "data", train=True, download=True, transform=ToTensor(), target_transform=None ) test_data = datasets.FashionMNIST( root = "data", train=False, download=True, transform=ToTensor() ) image, label = train_data[0] image.shape, label
import torch from torch import nn import torchvision from torchvision import datasets from torchvision.transforms import ToTensor import matplotlib.pyplot as plt train_data = datasets.FashionMNIST( root = "data", train=True, download=True, transform=ToTensor(), target_transform=None ) test_data = datasets.FashionMNIST( root = "data", train=False, download=True, transform=ToTensor() ) image, label = train_data[0] image.shape, label - 随机打印数据集的图片和标签
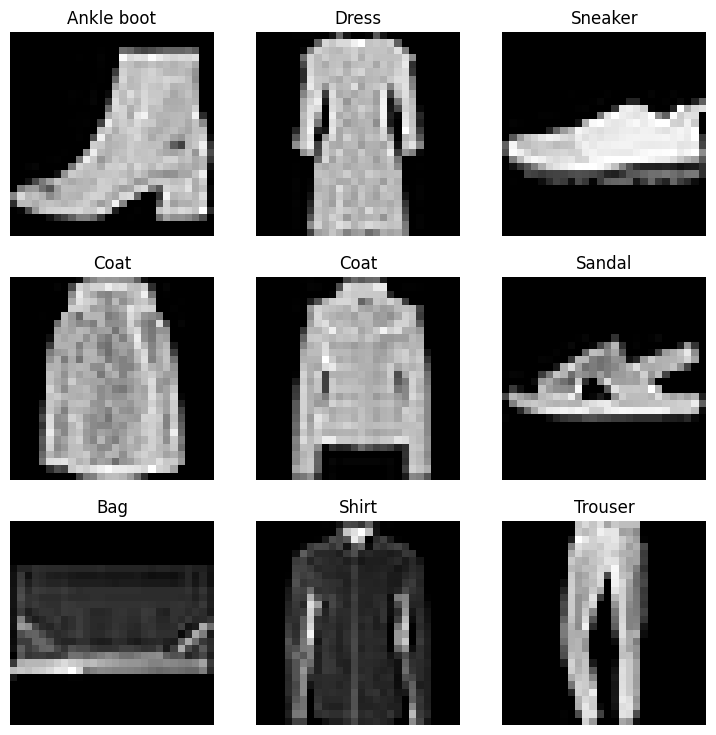
class_names = train_data.classesfig = plt.figure(figsize=(9, 9))rows, cols = 3, 3for i in range(1, rows * cols + 1):rand_idx = torch.randint(0, len(train_data), size=[1]).item()img, label = train_data[rand_idx]fig.add_subplot(rows, cols, i)plt.imshow(img.squeeze(), cmap='gray')plt.title(class_names[label])plt.axis(False)class_names = train_data.classes fig = plt.figure(figsize=(9, 9)) rows, cols = 3, 3 for i in range(1, rows * cols + 1): rand_idx = torch.randint(0, len(train_data), size=[1]).item() img, label = train_data[rand_idx] fig.add_subplot(rows, cols, i) plt.imshow(img.squeeze(), cmap='gray') plt.title(class_names[label]) plt.axis(False)
class_names = train_data.classes fig = plt.figure(figsize=(9, 9)) rows, cols = 3, 3 for i in range(1, rows * cols + 1): rand_idx = torch.randint(0, len(train_data), size=[1]).item() img, label = train_data[rand_idx] fig.add_subplot(rows, cols, i) plt.imshow(img.squeeze(), cmap='gray') plt.title(class_names[label]) plt.axis(False)
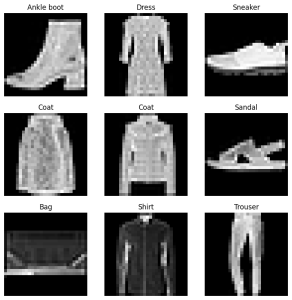
- 加载数据(转batch)
注意训练数据一定要shufflefrom torch.utils.data import DataLoaderBATCH_SIZE = 32train_dl = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)test_dl = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)from torch.utils.data import DataLoader BATCH_SIZE = 32 train_dl = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) test_dl = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)from torch.utils.data import DataLoader BATCH_SIZE = 32 train_dl = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) test_dl = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)
- CNN做图像分类任务
这里使用的是TinyVGG架构,注意点如下:|
1 每一层CNN都是Conv2d + Relu + Conv2d + MaxPool
2 Conv2d的参数:in_chan是图像数量、out_chan是feature_map的数量、kernel_size是核大小、stride是核一次走多少,padding是图片周围是否额外加一圈白
3 下面这个CNN层的shape参数有点难调,可以用print大法打印
4 CNN的解释参数在线演示:https://poloclub.github.io/cnn-explainer/class FashionMNISTModel(nn.Module):def __init__(self, input_n: int, hidden_units: int, output_n: int):super().__init__()self.block1 = nn.Sequential(nn.Conv2d(in_channels = input_n, # image channel, rgb is 3, gray is 1out_channels = hidden_units, # num of feature mapskernel_size = 3, # how bit is square go over imagestride = 1, # kernel skip how manypadding = 1), # add padding for imagenn.ReLU(),nn.Conv2d(in_channels = hidden_units,out_channels = hidden_units,kernel_size = 3,stride = 1,padding = 1),nn.ReLU(),nn.MaxPool2d(kernel_size = 2, stride = 2))self.block2 = nn.Sequential(nn.Conv2d(in_channels = hidden_units,out_channels = hidden_units,kernel_size = 3,stride = 1,padding = 1),nn.ReLU(),nn.Conv2d(in_channels = hidden_units,out_channels=hidden_units,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(in_features = hidden_units * 7 * 7, out_features = output_n))def forward(self, x: torch.Tensor):x = self.block1(x)#print(f"shape of block1 output: {x.shape}")x = self.block2(x)#print(f"shape of block2 output: {x.shape}")x = self.classifier(x)return xclass FashionMNISTModel(nn.Module): def __init__(self, input_n: int, hidden_units: int, output_n: int): super().__init__() self.block1 = nn.Sequential( nn.Conv2d(in_channels = input_n, # image channel, rgb is 3, gray is 1 out_channels = hidden_units, # num of feature maps kernel_size = 3, # how bit is square go over image stride = 1, # kernel skip how many padding = 1), # add padding for image nn.ReLU(), nn.Conv2d(in_channels = hidden_units, out_channels = hidden_units, kernel_size = 3, stride = 1, padding = 1), nn.ReLU(), nn.MaxPool2d(kernel_size = 2, stride = 2) ) self.block2 = nn.Sequential( nn.Conv2d(in_channels = hidden_units, out_channels = hidden_units, kernel_size = 3, stride = 1, padding = 1), nn.ReLU(), nn.Conv2d(in_channels = hidden_units, out_channels=hidden_units, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(in_features = hidden_units * 7 * 7, out_features = output_n) ) def forward(self, x: torch.Tensor): x = self.block1(x) #print(f"shape of block1 output: {x.shape}") x = self.block2(x) #print(f"shape of block2 output: {x.shape}") x = self.classifier(x) return xclass FashionMNISTModel(nn.Module): def __init__(self, input_n: int, hidden_units: int, output_n: int): super().__init__() self.block1 = nn.Sequential( nn.Conv2d(in_channels = input_n, # image channel, rgb is 3, gray is 1 out_channels = hidden_units, # num of feature maps kernel_size = 3, # how bit is square go over image stride = 1, # kernel skip how many padding = 1), # add padding for image nn.ReLU(), nn.Conv2d(in_channels = hidden_units, out_channels = hidden_units, kernel_size = 3, stride = 1, padding = 1), nn.ReLU(), nn.MaxPool2d(kernel_size = 2, stride = 2) ) self.block2 = nn.Sequential( nn.Conv2d(in_channels = hidden_units, out_channels = hidden_units, kernel_size = 3, stride = 1, padding = 1), nn.ReLU(), nn.Conv2d(in_channels = hidden_units, out_channels=hidden_units, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.classifier = nn.Sequential( nn.Flatten(), nn.Linear(in_features = hidden_units * 7 * 7, out_features = output_n) ) def forward(self, x: torch.Tensor): x = self.block1(x) #print(f"shape of block1 output: {x.shape}") x = self.block2(x) #print(f"shape of block2 output: {x.shape}") x = self.classifier(x) return x这里的loss和optimizer如下:
model1 = FashionMNISTModel(input_n=1, hidden_units=32, output_n=len(class_names))loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(params=model1.parameters(), lr=0.01)#optimizer = torch.optim.SGD(params=model1.parameters(), lr=0.1)model1 = FashionMNISTModel(input_n=1, hidden_units=32, output_n=len(class_names)) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(params=model1.parameters(), lr=0.01) #optimizer = torch.optim.SGD(params=model1.parameters(), lr=0.1)model1 = FashionMNISTModel(input_n=1, hidden_units=32, output_n=len(class_names)) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(params=model1.parameters(), lr=0.01) #optimizer = torch.optim.SGD(params=model1.parameters(), lr=0.1)
这里有个很奇怪的现象是:Adam似乎不太稳定,对于特定参数行,另一些可能loss完全下不去,而SGD就很稳定。网上查了下,有说是pyTorch的bug的。
更新:又试了下,把Adam的lr调小,能好很多,甚至能比还SGD强4%,Adam的默认lr应该是0.001,一般都不需要手动设置。 - 训练步骤的抽象函数
注意这里的accuracy函数,如果使用torchmatrics库的话,要乘以100,以及参数顺序不同。
另外,由于是按照批次累计的,所以最终需要按批次进行平均def train_step(model: torch.nn.Module,dl: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,optimizer: torch.optim.Optimizer,accuracy_fn,device: torch.device = device):train_loss, train_acc = 0, 0model.to(device)for batch, (X, y) in enumerate(dl):X, y = X.to(device), y.to(device)# 1. forwardy_pred_logits = model(X)#print(y_pred_logits, y_pred_logits.shape)y_pred = y_pred_logits.argmax(dim=1)#print(y_pred, y_pred_logits.shape)# 2. cal lossloss = loss_fn(y_pred_logits, y)train_loss += losstrain_acc += accuracy_fn(y_pred, y) * 100#train_acc += accuracy_fn(y_true=y, y_pred=y_pred)# 3. optim zero gardoptimizer.zero_grad()# 4. loss backwardloss.backward()# 5. optimize stepoptimizer.step()# avg loss & acctrain_loss /= len(dl)train_acc /= len(dl)print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")def train_step(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, optimizer: torch.optim.Optimizer, accuracy_fn, device: torch.device = device): train_loss, train_acc = 0, 0 model.to(device) for batch, (X, y) in enumerate(dl): X, y = X.to(device), y.to(device) # 1. forward y_pred_logits = model(X) #print(y_pred_logits, y_pred_logits.shape) y_pred = y_pred_logits.argmax(dim=1) #print(y_pred, y_pred_logits.shape) # 2. cal loss loss = loss_fn(y_pred_logits, y) train_loss += loss train_acc += accuracy_fn(y_pred, y) * 100 #train_acc += accuracy_fn(y_true=y, y_pred=y_pred) # 3. optim zero gard optimizer.zero_grad() # 4. loss backward loss.backward() # 5. optimize step optimizer.step() # avg loss & acc train_loss /= len(dl) train_acc /= len(dl) print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")def train_step(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, optimizer: torch.optim.Optimizer, accuracy_fn, device: torch.device = device): train_loss, train_acc = 0, 0 model.to(device) for batch, (X, y) in enumerate(dl): X, y = X.to(device), y.to(device) # 1. forward y_pred_logits = model(X) #print(y_pred_logits, y_pred_logits.shape) y_pred = y_pred_logits.argmax(dim=1) #print(y_pred, y_pred_logits.shape) # 2. cal loss loss = loss_fn(y_pred_logits, y) train_loss += loss train_acc += accuracy_fn(y_pred, y) * 100 #train_acc += accuracy_fn(y_true=y, y_pred=y_pred) # 3. optim zero gard optimizer.zero_grad() # 4. loss backward loss.backward() # 5. optimize step optimizer.step() # avg loss & acc train_loss /= len(dl) train_acc /= len(dl) print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%") - 测试函数的抽象函数
def test_step(model: torch.nn.Module,dl: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,accuracy_fn,device: torch.device = device):test_loss, test_acc = 0, 0model.to(device)model.eval()with torch.inference_mode():for X, y in dl:X, y = X.to(device), y.to(device)# 1. forwardtest_pred_logits = model(X)test_pred = test_pred_logits.argmax(dim = 1)# 2. cal loss & acctest_loss += loss_fn(test_pred_logits, y)test_acc += accuracy_fn(test_pred, y) * 100#test_acc += accuracy_fn(y_true=y, y_pred=test_pred)# avgtest_loss /= len(dl)test_acc /= len(dl)print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%n")def test_step(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, accuracy_fn, device: torch.device = device): test_loss, test_acc = 0, 0 model.to(device) model.eval() with torch.inference_mode(): for X, y in dl: X, y = X.to(device), y.to(device) # 1. forward test_pred_logits = model(X) test_pred = test_pred_logits.argmax(dim = 1) # 2. cal loss & acc test_loss += loss_fn(test_pred_logits, y) test_acc += accuracy_fn(test_pred, y) * 100 #test_acc += accuracy_fn(y_true=y, y_pred=test_pred) # avg test_loss /= len(dl) test_acc /= len(dl) print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%n")
def test_step(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, accuracy_fn, device: torch.device = device): test_loss, test_acc = 0, 0 model.to(device) model.eval() with torch.inference_mode(): for X, y in dl: X, y = X.to(device), y.to(device) # 1. forward test_pred_logits = model(X) test_pred = test_pred_logits.argmax(dim = 1) # 2. cal loss & acc test_loss += loss_fn(test_pred_logits, y) test_acc += accuracy_fn(test_pred, y) * 100 #test_acc += accuracy_fn(y_true=y, y_pred=test_pred) # avg test_loss /= len(dl) test_acc /= len(dl) print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%n") - 评估模型
和test流程差不多def eval_model(model: torch.nn.Module,dl: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,accuracy_fn,device: torch.device = device):loss, acc = 0, 0model.eval()with torch.inference_mode():for X, y in dl:X, y = X.to(device), y.to(device)y_pred = model(X)loss += loss_fn(y_pred, y)acc += accuracy_fn(y_pred, y) * 100loss /= len(dl)acc /= len(dl)return {"model_name": model.__class__.__name__,"model_loss": loss.item(),"model_acc": acc}eval_model(model=model1, dl=test_dl, loss_fn=loss_fn, accuracy_fn=accuracy_fn)def eval_model(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, accuracy_fn, device: torch.device = device): loss, acc = 0, 0 model.eval() with torch.inference_mode(): for X, y in dl: X, y = X.to(device), y.to(device) y_pred = model(X) loss += loss_fn(y_pred, y) acc += accuracy_fn(y_pred, y) * 100 loss /= len(dl) acc /= len(dl) return {"model_name": model.__class__.__name__, "model_loss": loss.item(), "model_acc": acc} eval_model(model=model1, dl=test_dl, loss_fn=loss_fn, accuracy_fn=accuracy_fn)def eval_model(model: torch.nn.Module, dl: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, accuracy_fn, device: torch.device = device): loss, acc = 0, 0 model.eval() with torch.inference_mode(): for X, y in dl: X, y = X.to(device), y.to(device) y_pred = model(X) loss += loss_fn(y_pred, y) acc += accuracy_fn(y_pred, y) * 100 loss /= len(dl) acc /= len(dl) return {"model_name": model.__class__.__name__, "model_loss": loss.item(), "model_acc": acc} eval_model(model=model1, dl=test_dl, loss_fn=loss_fn, accuracy_fn=accuracy_fn) - 预测
def make_predictions(model: torch.nn.Module,data: list,device: torch.device = device):pred_probs = []model.eval()with torch.inference_mode():for sample in data:# add batchsample = torch.unsqueeze(sample, dim=0).to(device)pred_logit = model(sample)# remove batch and maxpred_prob = torch.softmax(pred_logit.squeeze(), dim=0)pred_probs.append(pred_prob.cpu())# make into tensorreturn torch.stack(pred_probs)# test dataimport randomn_samples = 4test_samples = []test_labels = []for sample, label in random.sample(list(test_data), k=n_samples):test_samples.append(sample)test_labels.append(label)# make predpred_probs= make_predictions(model=model1,data=test_samples)pred_classes = pred_probs.argmax(dim=1)# figure itplt.figure(figsize=(10, 10))nrows = 2ncols = 2for i, sample in enumerate(test_samples):# Create a subplotplt.subplot(nrows, ncols, i+1)# Plot the target imageplt.imshow(sample.squeeze(), cmap="gray")# Find the prediction label (in text form, e.g. "Sandal")pred_label = class_names[pred_classes[i]]# Get the truth label (in text form, e.g. "T-shirt")truth_label = class_names[test_labels[i]]# Create the title text of the plottitle_text = f"Pred: {pred_label} | Truth: {truth_label}"# Check for equality and change title colour accordinglyif pred_label == truth_label:plt.title(title_text, fontsize=10, c="g") # green text if correctelse:plt.title(title_text, fontsize=10, c="r") # red text if wrongplt.axis(False);def make_predictions(model: torch.nn.Module, data: list, device: torch.device = device): pred_probs = [] model.eval() with torch.inference_mode(): for sample in data: # add batch sample = torch.unsqueeze(sample, dim=0).to(device) pred_logit = model(sample) # remove batch and max pred_prob = torch.softmax(pred_logit.squeeze(), dim=0) pred_probs.append(pred_prob.cpu()) # make into tensor return torch.stack(pred_probs) # test data import random n_samples = 4 test_samples = [] test_labels = [] for sample, label in random.sample(list(test_data), k=n_samples): test_samples.append(sample) test_labels.append(label) # make pred pred_probs= make_predictions(model=model1, data=test_samples) pred_classes = pred_probs.argmax(dim=1) # figure it plt.figure(figsize=(10, 10)) nrows = 2 ncols = 2 for i, sample in enumerate(test_samples): # Create a subplot plt.subplot(nrows, ncols, i+1) # Plot the target image plt.imshow(sample.squeeze(), cmap="gray") # Find the prediction label (in text form, e.g. "Sandal") pred_label = class_names[pred_classes[i]] # Get the truth label (in text form, e.g. "T-shirt") truth_label = class_names[test_labels[i]] # Create the title text of the plot title_text = f"Pred: {pred_label} | Truth: {truth_label}" # Check for equality and change title colour accordingly if pred_label == truth_label: plt.title(title_text, fontsize=10, c="g") # green text if correct else: plt.title(title_text, fontsize=10, c="r") # red text if wrong plt.axis(False);
def make_predictions(model: torch.nn.Module, data: list, device: torch.device = device): pred_probs = [] model.eval() with torch.inference_mode(): for sample in data: # add batch sample = torch.unsqueeze(sample, dim=0).to(device) pred_logit = model(sample) # remove batch and max pred_prob = torch.softmax(pred_logit.squeeze(), dim=0) pred_probs.append(pred_prob.cpu()) # make into tensor return torch.stack(pred_probs) # test data import random n_samples = 4 test_samples = [] test_labels = [] for sample, label in random.sample(list(test_data), k=n_samples): test_samples.append(sample) test_labels.append(label) # make pred pred_probs= make_predictions(model=model1, data=test_samples) pred_classes = pred_probs.argmax(dim=1) # figure it plt.figure(figsize=(10, 10)) nrows = 2 ncols = 2 for i, sample in enumerate(test_samples): # Create a subplot plt.subplot(nrows, ncols, i+1) # Plot the target image plt.imshow(sample.squeeze(), cmap="gray") # Find the prediction label (in text form, e.g. "Sandal") pred_label = class_names[pred_classes[i]] # Get the truth label (in text form, e.g. "T-shirt") truth_label = class_names[test_labels[i]] # Create the title text of the plot title_text = f"Pred: {pred_label} | Truth: {truth_label}" # Check for equality and change title colour accordingly if pred_label == truth_label: plt.title(title_text, fontsize=10, c="g") # green text if correct else: plt.title(title_text, fontsize=10, c="r") # red text if wrong plt.axis(False);
- Transform(预处理)
这里说的是对训练数据(例如图像)做预处理,pyTorch中预置了一些,常用的有
Resize(缩放)、RandomXXFlip(随机旋转)、ToTensor(数值缩放为0~1.0之间)
可以把这些处理整合成一个链路,如下:ata_transform = transforms.Compose([# Resize the images to 64x64transforms.Resize(size=(64, 64)),# Flip the images randomly on the horizontaltransforms.RandomHorizontalFlip(p=0.5), # p = probability of flip, 0.5 = 50% chance# Turn the image into a torch.Tensortransforms.ToTensor() # this also converts all pixel values from 0 to 255 to be between 0.0 and 1.0])ata_transform = transforms.Compose([ # Resize the images to 64x64 transforms.Resize(size=(64, 64)), # Flip the images randomly on the horizontal transforms.RandomHorizontalFlip(p=0.5), # p = probability of flip, 0.5 = 50% chance # Turn the image into a torch.Tensor transforms.ToTensor() # this also converts all pixel values from 0 to 255 to be between 0.0 and 1.0 ])ata_transform = transforms.Compose([ # Resize the images to 64x64 transforms.Resize(size=(64, 64)), # Flip the images randomly on the horizontal transforms.RandomHorizontalFlip(p=0.5), # p = probability of flip, 0.5 = 50% chance # Turn the image into a torch.Tensor transforms.ToTensor() # this also converts all pixel values from 0 to 255 to be between 0.0 and 1.0 ]) - Transfer Learning(Transform)
使用PyTorch内置的模型权重时,需要使用相同的Transform预处理,对于vision(图像)的约定的在这里:transforms = v2.Compose([v2.RandomResizedCrop(size=(224, 224), antialias=True),v2.RandomHorizontalFlip(p=0.5),v2.ToDtype(torch.float32, scale=True),v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])transforms = v2.Compose([ v2.RandomResizedCrop(size=(224, 224), antialias=True), v2.RandomHorizontalFlip(p=0.5), v2.ToDtype(torch.float32, scale=True), v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])transforms = v2.Compose([ v2.RandomResizedCrop(size=(224, 224), antialias=True), v2.RandomHorizontalFlip(p=0.5), v2.ToDtype(torch.float32, scale=True), v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])也可以直接使用模型上的来替代:
weights = torchvision.models.EfficientNet_B0_Weights.DEFAULTauto_transforms = weights.transforms()weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT auto_transforms = weights.transforms()weights = torchvision.models.EfficientNet_B0_Weights.DEFAULT auto_transforms = weights.transforms()
查看 模型形状:
summary(model=model,input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape"# col_names=["input_size"], # uncomment for smaller outputcol_names=["input_size", "output_size", "num_params", "trainable"],col_width=20,row_settings=["var_names"])summary(model=model, input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape" # col_names=["input_size"], # uncomment for smaller output col_names=["input_size", "output_size", "num_params", "trainable"], col_width=20, row_settings=["var_names"] )summary(model=model, input_size=(32, 3, 224, 224), # make sure this is "input_size", not "input_shape" # col_names=["input_size"], # uncomment for smaller output col_names=["input_size", "output_size", "num_params", "trainable"], col_width=20, row_settings=["var_names"] )模型其他层参数保持冻结,只修改输出层的分类数量:
for param in model.features.parameters():param.requires_grad = Falseoutput_shape = len(class_names)model.classifier = torch.nn.Sequential(torch.nn.Dropout(p=0.2, inplace=True),torch.nn.Linear(in_features=1280,out_features=output_shape, # same number of output units as our number of classesbias=True)).to(device)for param in model.features.parameters(): param.requires_grad = False output_shape = len(class_names) model.classifier = torch.nn.Sequential( torch.nn.Dropout(p=0.2, inplace=True), torch.nn.Linear(in_features=1280, out_features=output_shape, # same number of output units as our number of classes bias=True)).to(device)for param in model.features.parameters(): param.requires_grad = False output_shape = len(class_names) model.classifier = torch.nn.Sequential( torch.nn.Dropout(p=0.2, inplace=True), torch.nn.Linear(in_features=1280, out_features=output_shape, # same number of output units as our number of classes bias=True)).to(device)然后用自己的训练数据进行训练、测试即可完成微调。
也可以开启更多层不冻结,做更大范围微调。
甚至可以修改分类器为其他任务,例如用模型做图像分割任务。 - PyTorch中内置的其他常见层:
nn.Flatten:将张量压平
nn.MultiheadAttention:Transform注意力机制的多头(现在基本已经替代了RNN)
nn.LayerNorm:层标准化,能加速收敛,避免梯度消失
nn.GELU:类似RELU,另一种激活函数
nn.TransformerEncoder:叠加了N层encoder的Transfomer
nn.TransformerDecoderLayer:叠加了N层decoder的Transformer - TODO
PyTorch学习笔记
Leave a reply